{kind=link}
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Learn how to add new literature to JabRef.
JabRef provides you with many ways to add a new entry.
Entries can be created from a reference text.
In case you have a reference string, JabRef offers the functionality to convert the text to BibTeX (or biblatex). For this, JabRef uses the technology offered by .
Example:
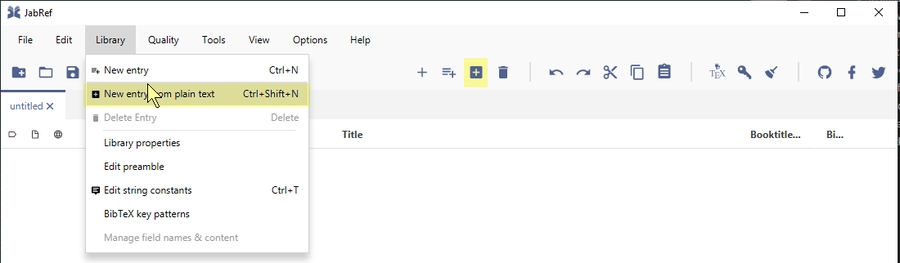
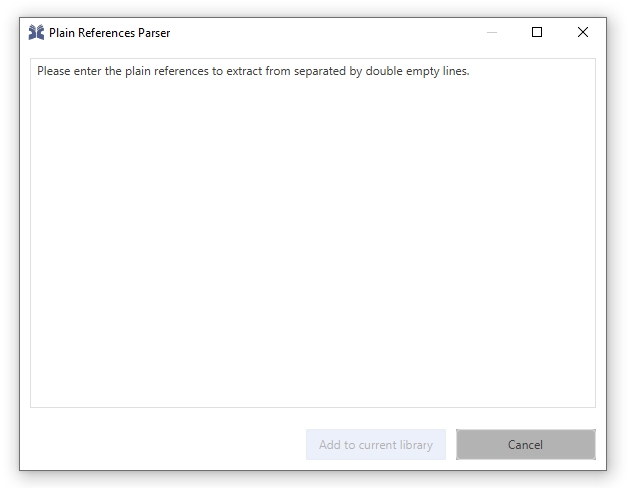
Click Library and select "New entry from plain text..." Alternatively, you can press Ctrl+Shift+N.
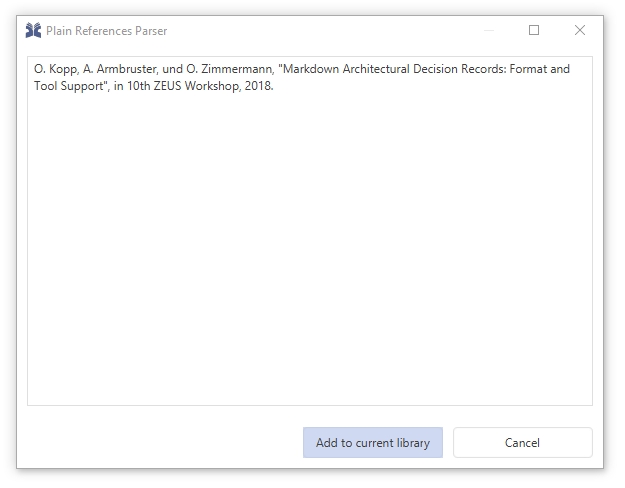
The "Plain Reference Parser" window opens
Paste the reference text:
Click "Add to current library"
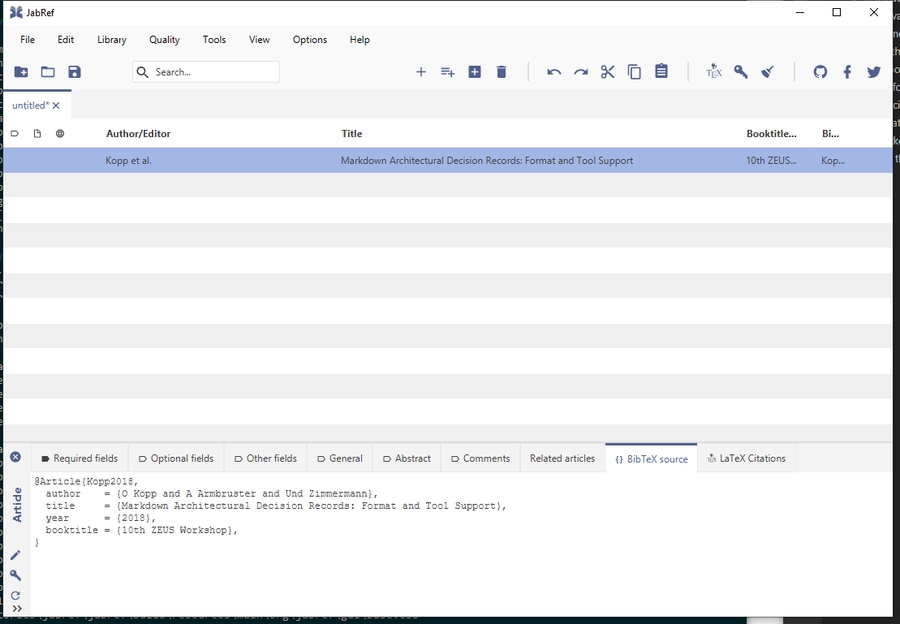
The result is selected in the entry table:
Using online databases to search for references
JabRef is not intended to be a tool for mass download of citations. The purpose of the Web search is to easily gather a few entries directly from within JabRef. If you use the search functionality too extensively you might get blocked (for some time). To fetch entries from an online database, choose View → Web search, and the search interface will appear in the side panel. Select the database you want to search (e.g., arXiv) in the dropdown menu. Note that it might be necessary to scroll downwards to find certain fetchers. An example for this is provided in the image below. You may opt to download the abstracts along with the cite information for each entry, by checking the Include abstracts checkbox.Then enter the words of your query, and press Enter, or the Search button. The results are displayed in the import inspection dialog. Some online services support advanced search queries. These are described below at the respective fetcher.
Apart from fetching entries by using a full search, it is also possible to directly create an entry using a unique identifier.
However, it is still possible to import hundreds or even thousands of entries from these databases. The process depends a bit on the specifics of each database, but in general works as follows: Search the database in your browser, export the result in one of the supported file formats and then import the file into JabRef.
If you need to use an HTTP proxy server, you can configure JabRef to use a proxy using the "Network" preferences (File → Preferences → Network).
Since version 5.2:
JabRef searches the databases by using the specified keywords. One can use quotes (") to keep words togehter: An example is "process mining". It is also possible to restrict the search to dedicated fields:
Thereby, JabRef supports following fields:
author
The author of the work
title
The title of the work
journal
The title of the journal of the work
year
The year in which the work was published
year-range
The year range (e.g., 1999-2001) the work was published
doi
The document object identifier of the work
One can usually combine different searches using the Boolean operators AND and OR. Thereby, the default operator is OR.
author:smith and author:jones: search for references with authors "smith" and "jones"
author:smith or author:jones: search for references with either author "smith" or author "jones"
author:smith and not title:processor: search for author "smith" and omit references with "processor" in the title
Technial note: The search syntax is adapted from Apache Lucene. JabRef takes the Lucene syntax and transforms it to the syntax required by the supported databases.
The ACM Portal includes two databases (Wikipedia):
the ACM Digital Library is a text collection of every article published by the Association for Computing Machinery, including over 60 years of archives from articles, magazines and conference proceedings.
the Guide to Computing Literature that is a bibliographic collection from major publishers in computing with over one million entries.
ArXiv is a repository of scientific preprints in the fields of mathematics, physics, astronomy, computer science, quantitative biology, statistics, and quantitative finance (Wikipedia).
The Bibliotheksverbund Bayern (BVB) provides bibliographic information from all public libraries in Bavaria, Germany. The format used is MarcXML, which has been modified, which in turn is based on other modifications.
Biodiversity Heritage Library makes biodiversity literature openly available to the world as part of a global biodiversity community. It is the world’s largest open access digital library for biodiversity literature and archives (Wikipedia).
CiteSeerX is a public search engine for scientific and academic papers primarily with a focus on computer and information science. However, CiteSeerX has been expanding into other scholarly domains such as economics, physics, and others (Wikipedia).
The Collection of Computer Science Bibliographies is a public search engine for bibliographies of scientific literature in computer science.
Unpaywall is an open database with over 20 million free scholarly articles harvested from over 50,000 journals and open-access repositories around the globe. Sources for these articles include repositories run by renowned universities, governments, and scholarly societies. Unpaywall is integrated into thousands of existing search engines, library platforms, and information products, making articles easy to find, track, and use for your scholarly communication needs.
The Unpaywall database has a very simple structure: it has one record for each article with a Crossref DOI. It harvests from many sources to find Open Access content, and then matches this content to these DOIs using content fingerprints. So for any given DOI, we know about any OA versions that exist anywhere.
To fetch entries from Unpaywall indirectly through Crossref, choose Search → Web search, and the search interface will appear in the side pane. Select Crossref in the dropdown menu. To start a search, enter the words of your query, and press Enter or the Fetch button.
DBLP is a computer science bibliography website listing more than 3.1 million journal articles, conference papers, and other publications on computer science (Wikipedia).
DOAB (Directory of Open Access Books) is is a community-driven discovery service that indexes and provides access to scholarly, peer-reviewed open access books and helps users to find trusted open access book publishers.
DOAJ (Directory of Open Access Journals) is a database covering more than 10000 open access journals covering all areas of science, technology, medicine, social science, and humanities (Wikipedia).
It is possible to limit the search by adding a field name to the search, as field:text. The supported fields are:
title
The title of the article
doi
The DOI of the article
issn
The ISSN of the journal
publisher
The publisher of the journal
abstract
The abstract of the article
Currently not working, because Google changed their API
Google Scholar is a freely accessible database that indexes the full text or metadata of scholarly literature across an array of publishing formats and disciplines. Google Scholar index includes most peer-reviewed online academic journals and books, conference papers, theses and dissertations, preprints, abstracts, technical reports, and other scholarly literature, including court opinions and patents (Wikipedia).
Google scholar can block "automated" crawls which generate too much traffic in a short time. To unblock your IP, doing a Google scholar search in your browser might help. You will be asked to show that you are not a robot (a CAPTCHA challenge). If no CAPTCHA appears, or JabRef is still blocked after performing a search in the browser, you can also change your IP address manually or wait for some hours to get unblocked again.
Thus, the Google Scholar fetcher is not the best way to obtain lots of entries at the same time. The JabRef browser extension might be an alternative to download the bibliographic data directly from the browser.
GVK, the GBV Union Catalogue, is a multimaterial bibliographic database of seven German federal states. It covers 41.5 million records of books, conference proceedings, periodicals, dissertations, microfilms and electronic resources.
You can simply enter words / names / years you want to search for, or you can specify search fields.
Supported fields are:
all
all words. Not specifYing a search key results in an "all" search
title
title words (converted to GVK's tit field)
author
Searches author, editors, etc. (converted to GVK's per field)
journal
The journal (converted to GVK's zti field)
year
The year of publication (converted to GVK's erj field)
thm
topics
slw
key words
txt
tables of content
num
numbers, e.g. ISBN
kon
names of conferences
ppn
Pica Production Numbers of the GVK
bkl
Basisklassifikation-numbers
Year ranges are not supported. In case a year range is provided, it is ignored. Otherwise, GVK returns no results.
queries can be combined with and. The use of and is optional, though.
in many cases you can use the truncation sign ?
spaces in person names are not supported yet. Please use the truncation sign ? after the first name for several given names. E.g. per Maas,jan?
marx kapital
author:grodke and title:db2
author:"Maas,jan?"
IEEEXplore is a scholarly research database that indexes, abstracts, and provides full-text for articles and papers on computer science, electrical engineering and electronics. IEEEXplore comprises over 180 journals, over 1,400 conference proceedings, more than 3,800 technical standards, over 1,800 eBooks and over 400 educational courses (Wikipedia)
INSPIRE-HEP is an open access digital library for the field of high energy physics (Wikipedia).
The INSPIRE-HEP search function merely passes your search queries onto the INSPIRE-HEP web search, so you should build your queries in the same way. INSPIRE supports the fielded search too. See https://inspirehep.net/help/knowledge-base/inspire-paper-search/ for advanced help.
The following list shows some of the field indicators that can be used:
author
search author names
title
search in title
journal
Here either the common abbreviation or the 5 letter CODEN abbreviation for a journal can be used. Volume and page can also be included, separated by commas. For instance, j Phys. Rev.,D54,1 looks in the journal Phys. Rev., volume D54, page 1.
collection
The collecion
fulltext
Search in the fulltext
k
search in keywords
Currently disabled because of traffic limit
Jstor is an online database with access to more than 12 million journal articles, books, and sources in 75 disciplines. About
It is possible to limit the search by adding a field name to the search, such as field:"text". The supported fields are:
title: The title of the article
author: an author of the article
journal: journal title (sent as pt to Jstor)
pt: publication title
MathSciNet is a searchable online bibliographic database. It contains all of the contents of the journal Mathematical Reviews (MR) since 1940 along with an extensive author database, links to other MR entries, citations, full journal entries, and links to original articles. It contains almost 3 million items and over 1.7 million links to original articles (Wikipedia).
MEDLINE is a bibliographic database of life sciences and biomedical information. It includes bibliographic information for articles from academic journals covering medicine, nursing, pharmacy, dentistry, veterinary medicine, and health care. MEDLINE also covers much of the literature in biology and biochemistry, as well as fields such as molecular evolution (Wikipedia).
The Medline syntax is completely different form the Lucene syntax. One cannot use fielded search there.
There are two ways of specifying which entries to download:
Enter one or more MEDLINE IDs (separated by comma/semicolon) in the text field.
Enter a set of names and/or words to search for. You can use the operators and and or and parentheses to refine your search expression. See OVID operators for full description.
May \[au\] AND Anderson \[au\]
Anderson RM \[au\] HIV \[ti\]
Valleron \[au\] 1988:2000\[dp\] HIV \[ti\]
Valleron \[au\] AND 1987:2000\[dp\] AND (AIDS \[ti\] OR HIV\[ti\])
Anderson \[au\] AND Nature \[ta\]
Population \[ta\]
SAO/NASA Astrophysics Data System is an online database of over eight million astronomy and physics papers from both peer-reviewed and non-peer-reviewed sources. Abstracts are available free online for almost all articles, and full scanned articles are available in Graphics Interchange Format (GIF) and Portable Document Format (PDF) for older articles (Wikipedia).
To be detailed.
Semantic Scholar is a free, AI-powered, research tool for scientific literature. Developed at the Allen Institute for AI, it uses advances in natural language processing to provide summaries for scholarly papers (Wikipedia).
Springer (aka Springer Science+Business Media) is a global publishing company that publishes books, e-books, and peer-reviewed journals in science, technical and medical publishing. Springer also hosts a number of scientific databases, including SpringerLink, Springer Protocols, and SpringerImages (Wikipedia).
zbMATH Open is an abstracting and reviewing service in pure and applied mathematics. Its database contains about 4 million bibliographic entries with reviews or abstracts currently drawn from about 3,000 journals and book series, and 180,000 books. The coverage starts in the 18th century and is complete from 1868 to the present by the integration of the "Jahrbuch über die Fortschritte der Mathematik" database (about).
You cannot use the same query syntax as in the one-line search at zbmath.org; you have to stick with the Apache Lucence syntax. This means that your query can be composed of several terms, combined by the logical operators AND and OR. Queries are case-insensitive. Further operators that can be used are NOT for logical negation, * for a right wildcard, " " for exact phrase matches, and parentheses ( ) to group terms. Optionally, it is possible to add a field name in the form field:text to limit the search results. The supported fields are:
author
Author, editor - sent in the au field
title
Author, editor - sent in the ti field
journal
Journal - sent in the so field
year
Year - sent in the py field
yearrange
Year range - sent in the py field
cc
MSC code
dt
document type (possible values are j for journal articles, b for books, a for book articles)
an
the zbl id of the document
ai
internal author identifier
la
ab
search for term in reviews or abstracts
rv
reviewer
sw
software
en
external identifier
br
biographical reference
``algebra*: Searches for publications containing a term starting with algebra (e.g. algebra, algebras, algebraic, etc.) in any field.
title:"Graph Theory": Searches for publications with the exact phrase Graph Theory in their title field.
an:0492.90056: Searches for the document with zbl number 0492.90056.
author:Berge and title:"Graph Theory": Searches for entries written by Berge with Graph Theory in their title field.
dt:b author:Berge: Searches for all books written by Berge.
title:"Graph Theory" yearrange:2010-2020: Searches for documents containing the exact phrase Graph Theory in their title that are published between 2010 and 2020.
so:Combinatorica: Searches for documents published in the journal Combinatorica.
cc:"(05C|90C)": Searches for documents with MSC code in 05C or 90C.
la:"es | pt": Searches for documents written in Spanish or Portuguese.
sw:python: Searches for publications using the software python.
en:arXiv: Searches for entries with a link to an arXiv preprint.
br:"Claude Berge": Searches for publications with biographical information on Claude Berge.
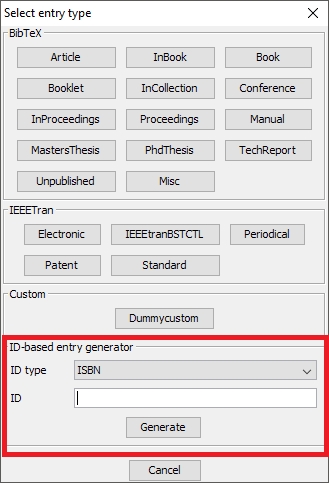
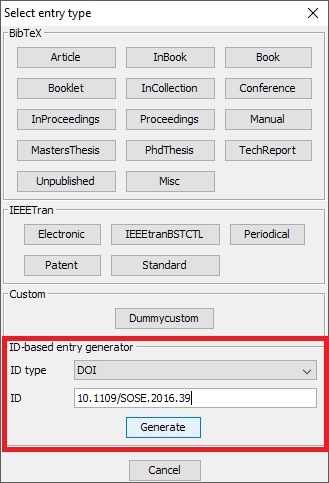
Create an entry based on an ID such as DOI or ISBN.
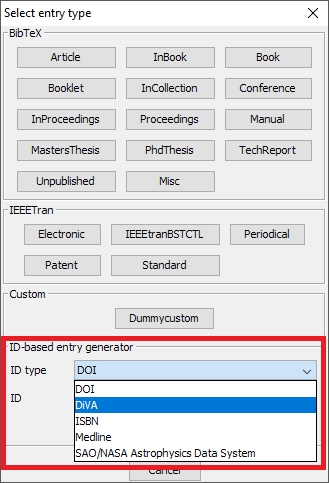
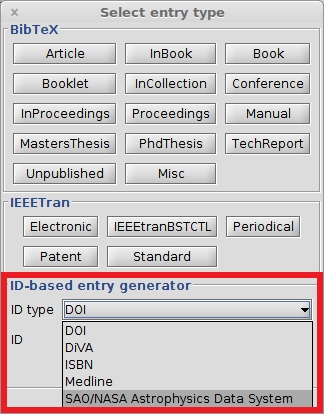
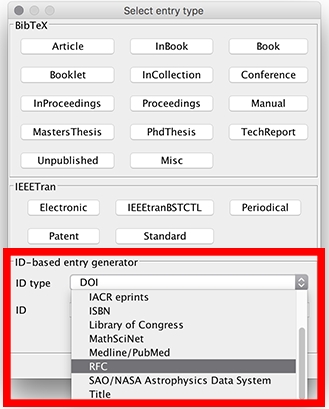
For other identifiers, choose Library → New entry, or click on the New entry button, or use the keyboard shortcut CTRL + N. In the lower part of the window, there are two boxes : "ID type" and "ID". In the field "ID type", you can select the desired identifier, e.g. "ISBN" (it works also for DOI). Then enter the identifier in the textbox below and press Enter. That will generate an entry based on the given ID (you can also click on "Generate"). The entry is added to your library and opened in the entry editor. In case an error occurs, a popup is shown.
You can also add an entry by simply pasting its BibTex or its DOI from your clipboard to the maintable.
ID search is carried out using the DOI.
ID search is carried out using the DiVA id (diva2).
ID search is carried out using the DOI.
If JabRef cannot find the reference of your DOI using this ID type, please, try the same DOI with the ID type "mEDRA". The ID type mEDRA looks for the reference corresponding to a DOI too, but using another registration agency.
ID search is carried out using the Cryptology ePrint ID.
ID search is carried out using the MR number.
ID search is carried out using the DOI.
Based on the title of your publication, JabRef call Crossref, which return the corresponding DOI. Then JabRef fetches the reference based on this DOI.
To return a reference, the publication needs to have a DOI.
IETF (Internet Engineering Task Force) Datatracker is a database that "contains data about the documents, working groups, meetings, agendas, minutes, presentations, and more, of the IETF." It used to be available at https://datatracker.ietf.org/ (currently down).
ID search is carried out using the (Request for Comments number) (RFC) of the IETF database.
ID search is carried out using the Zbl number.
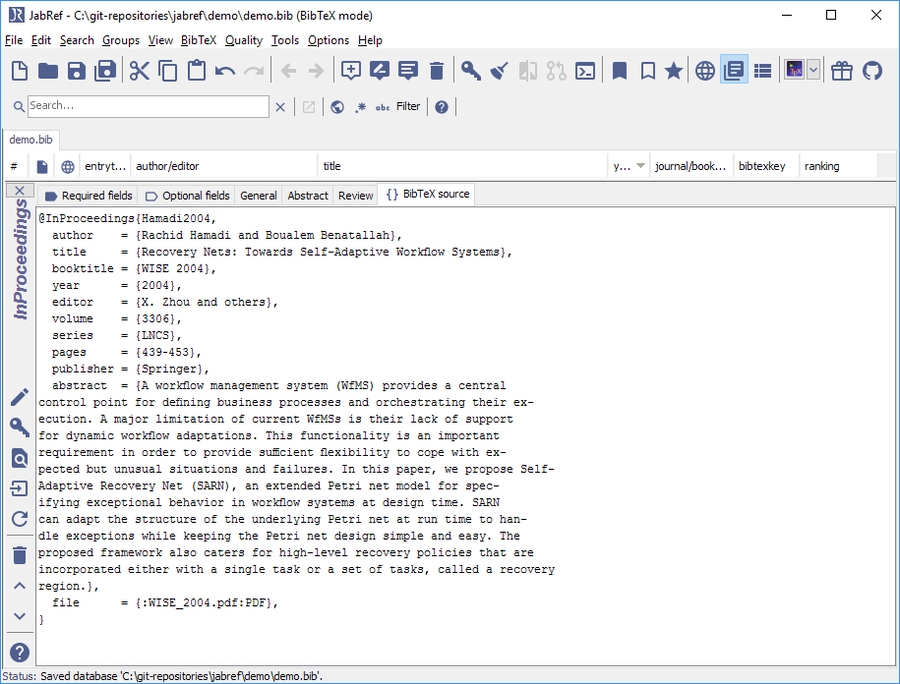
JabRef can create entries from PDF files.
The simplest way to create a new entry based on a single PDF file is to drag & drop the file onto the table of entries (between two existing entries). JabRef will then analyze the PDF and create a new entry.
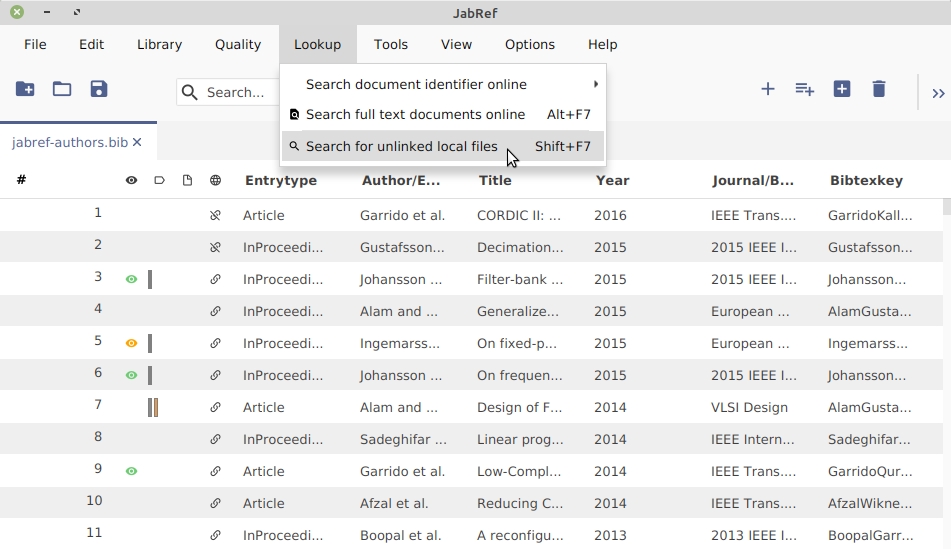
This feature is available through Lookup -> Search for unlinked local files.
This page is partly outdated. Please, help.
The following description appeared first on .
JabRef offers a BibTeX key generation and offers different patterns described at .
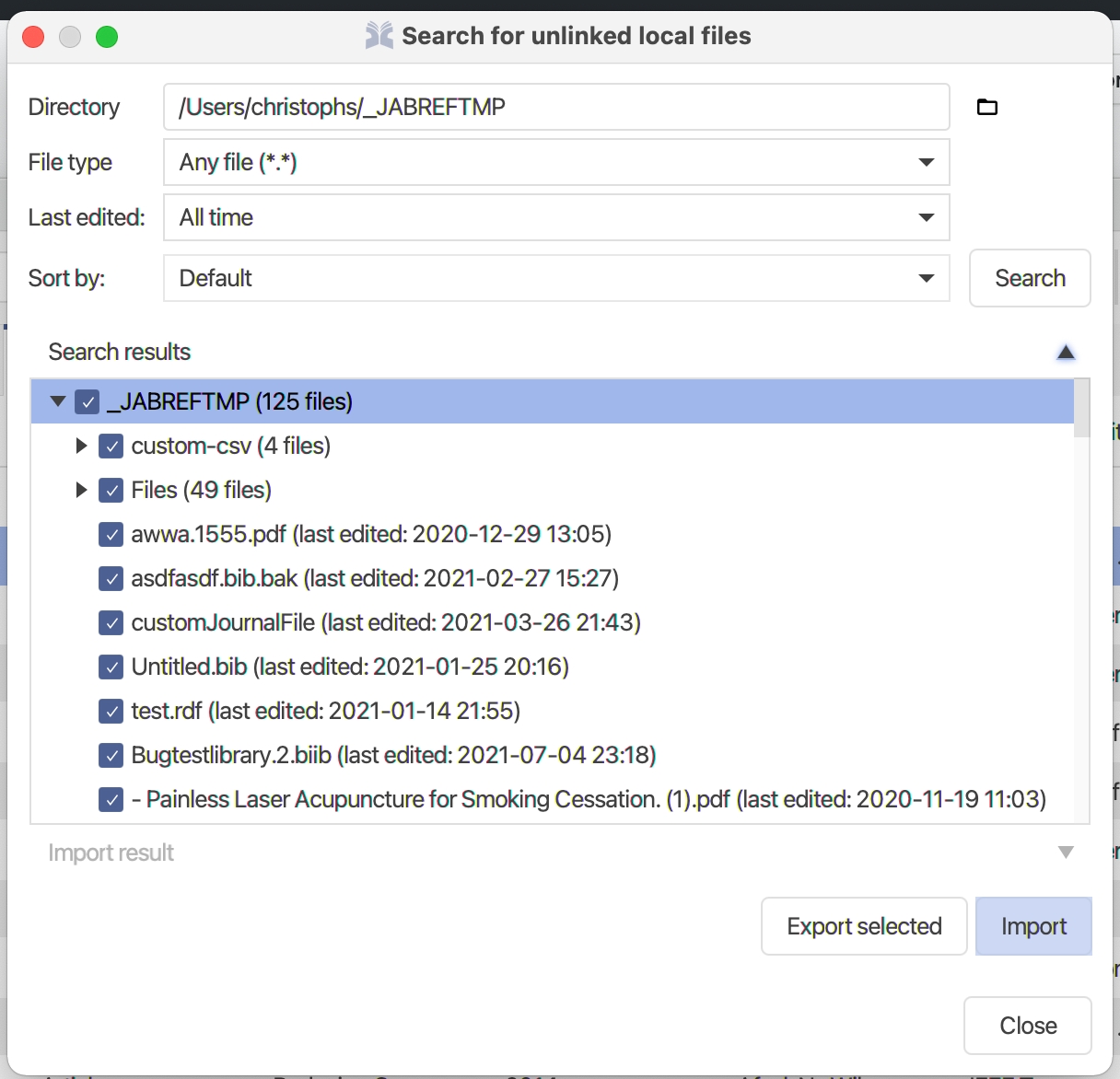
In case you have numerous PDF files and want to convert them into new entries, JabRef can search automatically for the PDF files, let you select the relevant ones, and convert them into new entries.
Create or open a .bib library.
Go to Lookup -> Search for unlinked local files. (or press SHIFT + F7)
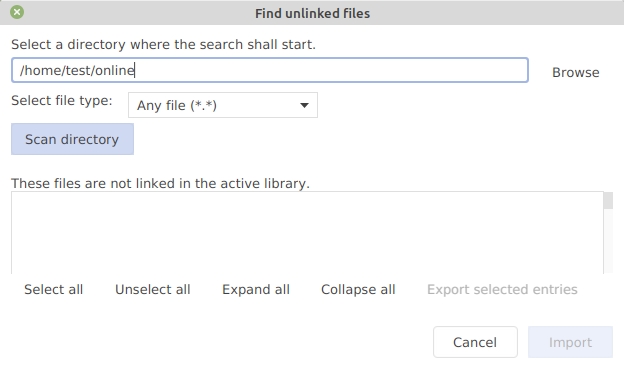
The "Search for unlinked local files" dialog opens.
Choose a start directory using the "Browse" button.
Click on "Search" / "Scan directory".
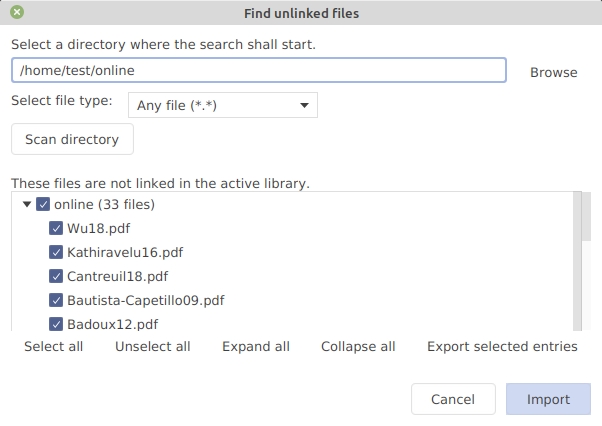
In "Select files", the files not yet contained in the library are shown.
Select the entries you are interested in. Note: the button Export selected files allows you to export the list of the selected files (a text file containing on each line one filename with its path)
Click on Import.
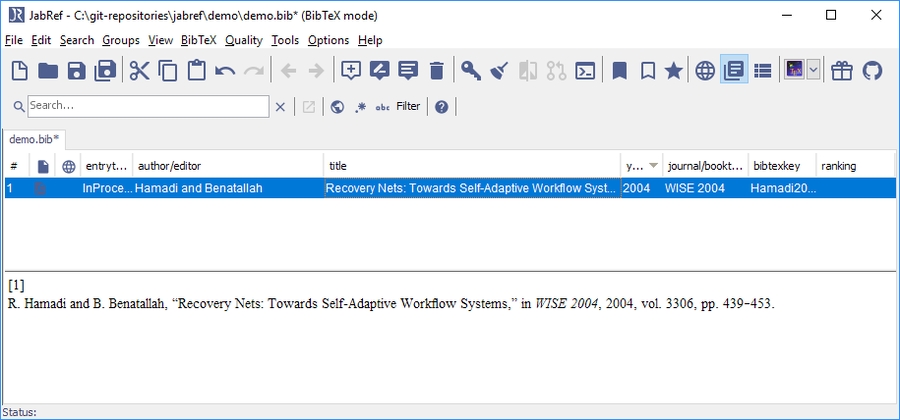
The windows close and the entry table now contains the newly-imported entries.
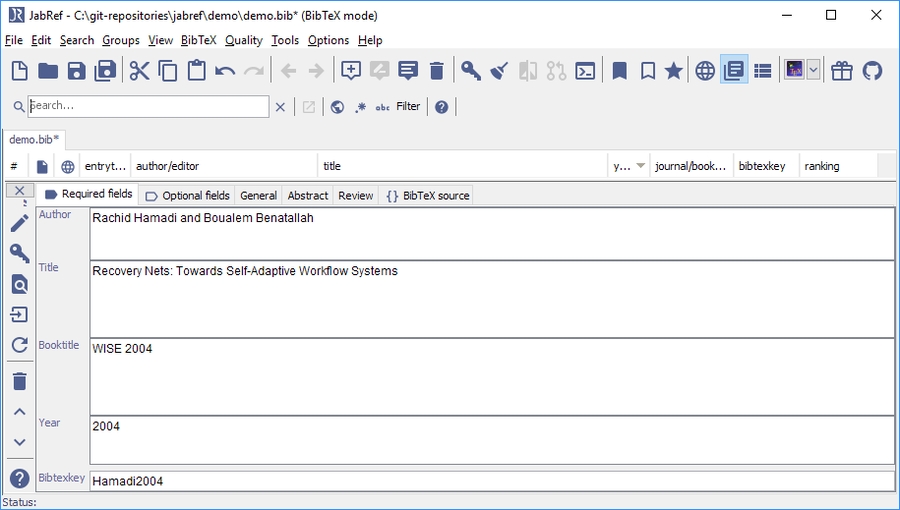
The entry editor with the last imported entry is shown
You can now save the file and are finished.
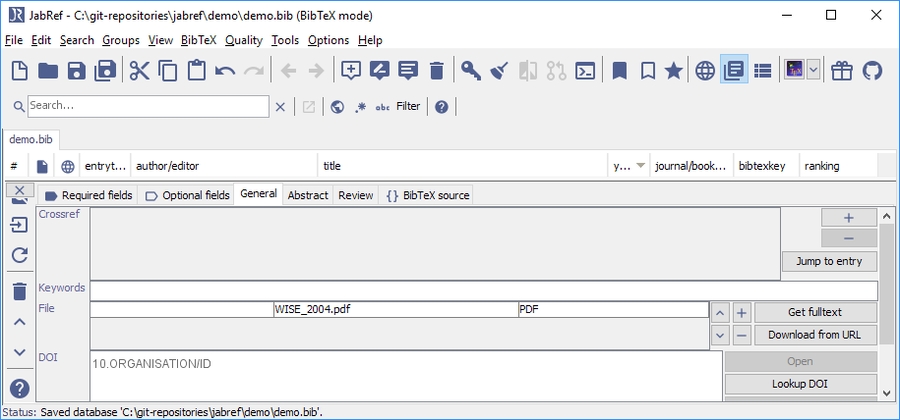
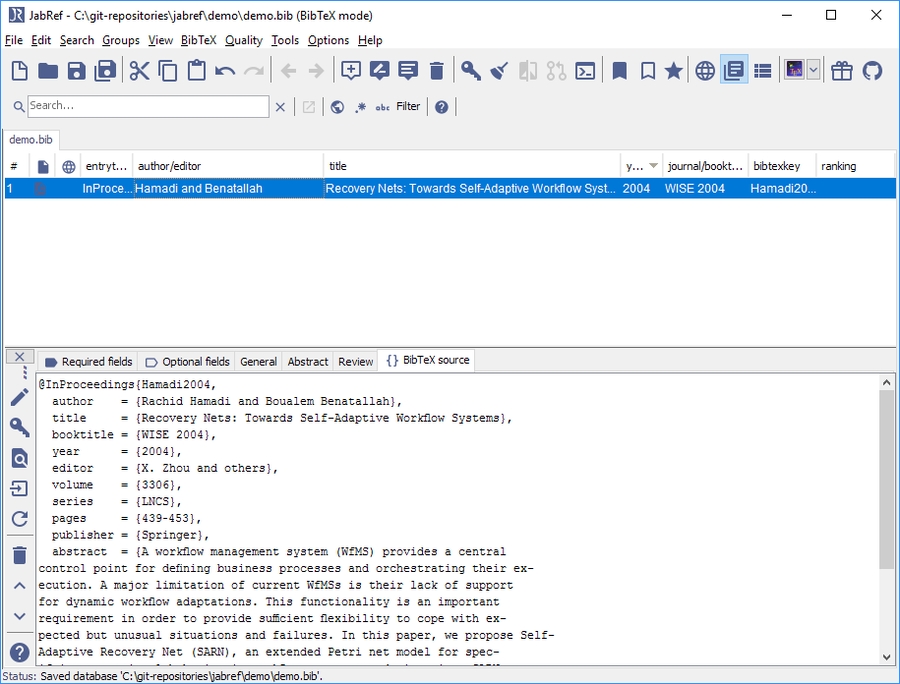
Optional: Click on "General" to see the linked file
Optional: Click on "BibTeX source" to see the BibTeX source
Optional: You have to shrink it to see the entry in the entry table, enlarge the JabRef window and use the mouse at the upper border of the entry editor
Optional: Press Esc to show the entry preview
The imported entries may need some editing because all the information gathered from the PDF files may not be accurate (see below "PDFs for which it works").
This makes the filenames start with the bibtey key followed by the full title. In the concrete case, \bibtexkey only may be the better option as the described bibtey key already contains the title.
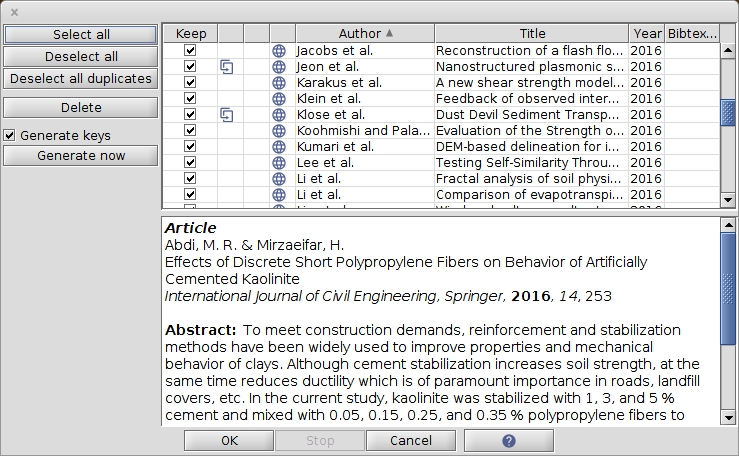
When you import new entries from a supported reference format or fetch entries directly from the Internet, the inspection window allows you to select the entries you want to keep, to , and to perform some simple operations like generating citation keys for the entries or adding them to . If you are importing into an existing database, it is often easier to perform these operations before they are mixed in between the entries of your database.
Entries are first shown in the inspection window. Note that, if this takes too long (for example), you can click on the button Stop at the bottom of the window.
Once the entries displayed in the inspection window, none of them have been added to one of your databases yet.
By default, all the entries are selected for importation, as shown by the checked boxes in the Keep column. You can select/unselect an entry by clicking on these checkboxes. On the left panel, buttons allow you to Select all the entries for importation, or to Deselect all the entries.
A left-click on an entry (out of the check box and icons) let you choose it. It displays a preview of the entry below the entry table. As usual, you can choose several entries by using the Shift or the Ctrl keys. Then, pushing the button Delete on the left panel will remove the chosen entries from the table.
A right-click on an entry displays a drop-down menu which allows you to:
delete the entry
add the entry to a group
link a local file to the entry
download the file corresponding to the entry
automatically set file links to the entry
attach an URL to the entry
On the left panel, if the box Generate keys is checked, keys will be automatically generated on import. You can also choose to generate the keys now by clicking on the button Generate now.
Once you are done with the entry selection, you can add these entries to your database by clicking on OK at the bottom of the window. Alternatively, you can Cancel the import.
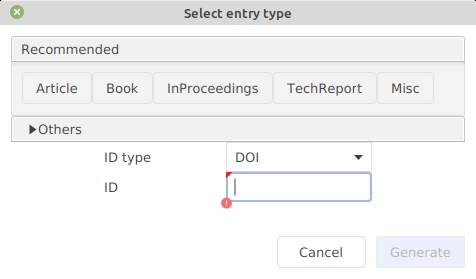
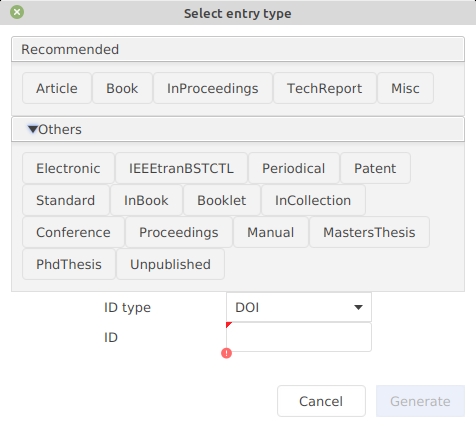
To add a new entry, select Library → New entry..., press CTRL + N or click on the dedicated icon of the toolbar.
A dialog window is displayed. By default, 5 common types of entries are displayed:
For other types of entries, click on Others. That expands the window and displays the other entry types available:
You can directly create a new entry of a specific entry type by using a keyboard shortcut. We strongly recommend learning the shortcuts for the entry types you use most often, e.g. Ctrl + Shift + A for adding an article entry. See Options → Customize key bindings.
This help page should describe the menu File -> Import (and the various file formats available).
Please, populate this page. Visit our page about .
See also:
This information is outdated. Please help to improve it ().
JabRef allows you to define and use your own importers, in very much the same way as the standard import filters are defined. An import filter is defined by one or more Java classes, which parse the contents of a file from an input stream and create BibTex entries. So with some basic Java programming, you can add an importer for your favorite source of references or register a new, improved version of an existing importer. Also, this allows you to add compiled custom importers that you might have obtained e.g. from GitHub without rebuilding JabRef (see "Sharing your work" below).
Custom importers take precedence over standard importers. This way, you can override existing importers for the Autodetect and Command Line features of JabRef. Custom importers are ordered by name.
Make sure, you have a compiled custom import filter (one or more .class files as described below) and the class files are in a directory structure according to their package structure. To add a new custom import filter, open the dialog box Options → Manage custom imports, and click Add from folder. A file chooser will appear, allowing you to select the classpath of your importer, i.e. the directory where the top folder of the package structure of your importer resides. In a second file chooser, you select your importer class file, which must be derived from ImportFormat. By clicking Select new ImportFormat Subclass, your new importer will appear in the list of custom import filters. All custom importers will appear in the File → Import → Custom Importers and File → Import and Append → Custom Importers submenus of the JabRef window.
Please note that if you move the class to another directory you will have to remove and re-add the importer. If you add a custom importer under a name that already exists, the existing importer will be replaced. Although in some cases it is possible to update an existing custom importer without restarting JabRef (when the importer is not on the classpath), we recommend restarting JabRef after updating a custom-importer. You can also register importers contained in a ZIP- or JAR-file, simply select the Zip- or Jar-archive, then the entry (class-file) that represents the new importer.
For examples and some helpful files on how to build your own importer, please check our download page.
Let us assume that we want to import files of the following form:
In your favorite IDE or text editor create a class derived from ImportFormat that implements methods getFormatName(), isRecognizedFormat and importEntries(). Here is an example:
Note that the example is in the default package. Suppose you have saved it under /mypath/SimpleCSVImporter.java. Also, suppose the JabRef-2.0.jar is in the same folder as SimpleCSVImporter.java and Java is on your command path. Compile it using a JSDK 1.4 e.g. with
Now there should be a file /mypath/SimpleCSVImporter.class.
In JabRef, open Options → Manage custom imports and click Add from folder. Navigate to /mypath and click the Select ... button. Select the SimpleCSVImporter.class and click the Select ... button. Your importer should now appear in the list of custom importers under the name "Simple CSV Importer" and, after you click Close also in the File → Import → Custom Importers and File → Import and Append → Custom Importers submenus of the JabRef window.
With custom importer files, it's fairly simple to share custom import formats between users. If you write an import filter for a format not supported by JabRef, or an improvement over an existing one, we encourage you to post your work on our GitHub page. We'd be happy to distribute a collection of submitted import files or to add to the selection of standard importers.
The official browser extension automatically identifies and extracts bibliographic information on websites and sends them to JabRef with one click.
- - -
JabRef offers an official browser extension. It automatically identifies and extracts bibliographic information on websites and sends them to JabRef with one click.
When you find an interesting article through Google Scholar, the arXiv or journal websites, this browser extension allows you to add those references to JabRef. Even links to accompanying PDFs are sent to JabRef, where those documents can easily be downloaded, renamed, and placed in the correct folder. .
Normally, you simply install the extension from the browser store and are ready to go.
- - -
While Chrome extensions can work in Edge (and will install), JabRef is configured to work with the Edge extension in the Edge Browser, and the Chrome extension in the Chrome Browser. It will not work if they are mixed.
After the installation, you should be able to import bibliographic references into JabRef directly from your browser. Just visit a publisher site or some other website containing bibliographic information (for example, ) and click the JabRef symbol in the Firefox search bar (or press Alt+Shift+J). Once the JabRef browser extension has extracted the references and downloaded the associated PDF's, the import window of JabRef opens.
You might want to configure JabRef so that new entries are always imported in an already opened instance of JabRef. For this, activate "Listen to remote operation on port" under the "Network" tab of the JabRef Preferences.
1) Go to . 2) Deactivate AdBlock plus extension for the whole domain (zotero.org) by clicking on the Adblock plus extension button and sliding the corresponding slider to allow adds on the whole domain. 3) Close and reopen the browser in order to reload all the extension and their settings. 4) Verify the functioning of the Jabref extension by visiting a page you know is working to extract its bibliographic data (for example, ) by pressing the extension button or Alt + Shift + J.
In case you encounter problems in this procedure refer to issue #241 on GitHub for further help.
Error message bad interpreter: /usr/bin/python3: no such file or directory means that python3 is not installed at the expected location. Run which python3 to see if python3 is installed elsewhere. Then copy that path at the first line of jabrefHost.py maintaining #! prefix.
Most JabRef installations include the necessary files, so test the extension before proceeding with the following instructions. However, sometimes, a manual installation is necessary (e.g. if you use the portable version of JabRef). In this case, please take the following steps:
Download the following files and copy them to the same directory as JabRef.exe
Make sure that the correct file name of the JabRef.bat file is specified in JabRefHost.ps1 under $jabRefExe.
Run the following command from the console (with the correct path to the jabref.json file):
a. For Firefox support:
b. For Chrome/Opera/Brave/Vivaldi and other chromium-based browser support:
c. For Edge support:
You may need to change the root HKEY_LOCAL_MACHINE to HKEY_CURRENT_USER if you don't have admin rights.
/usr/lib64/mozilla/native-messaging-hosts/org.jabref.jabref.json (and /usr/lib/mozilla/native-messaging-hosts/org.jabref.jabref.json) to install with admin rights for all users
~/.mozilla/native-messaging-hosts/org.jabref.jabref.json to install without admin rights for the current user
/etc/opt/chrome/native-messaging-hosts/org.jabref.jabref.json to install with admin rights for all users
~/.config/google-chrome/NativeMessagingHosts/org.jabref.jabref.json to install without admin rights for the current user
/etc/chromium/native-messaging-hosts/org.jabref.jabref.json to install with admin rights for all users
~/.config/chromium/NativeMessagingHosts/org.jabref.jabref.json to install without admin rights for the current user
/etc/opt/edge/native-messaging-hosts/org.jabref.jabref.json to install with admin rights for all users
~/.config/microsoft-edge/NativeMessagingHosts/org.jabref.jabref.json to install without admin rights for the current user
Open the file org.jabref.jabref.json with a text editor, and alter it so that its path variable matches the location of your jabrefHost.py file.
Connect the appropriate plug for the selected browser:
Firefox: snap connect jabref:hostfs-mozilla-native-messaging-jabref
Chrome: snap connect jabref:etc-opt-chrome-native-messaging-jabref
Chromium: snap connect jabref:etc-chromium-native-messaging-jabref
Edge: snap connect jabref:etc-opt-edge-native-messaging-jabref
If the browser is installed as a snap or flatpak there is an extra step to enable the extension.
With Firefox installed as a snap (default in Ubuntu):
flatpak permission-set webextensions org.jabref.jabref snap.firefox yes
With Firefox installed as a flatpak:
Enable the following permission (Note that this will partially disable confinement):
via terminal command: flatpak override --user --talk-name=org.freedesktop.Flatpak org.mozilla.firefox
via Flatseal app: add org.freedesktop.Flatpak to the Session Bus Talk section for org.mozilla.firefox
/Library/Application Support/Mozilla/NativeMessagingHosts/org.jabref.jabref.json to install with admin rights for all users
~/Library/Application Support/Mozilla/NativeMessagingHosts/org.jabref.jabref.json to install without admin rights for the current user
/Library/Google/Chrome/NativeMessagingHosts/org.jabref.jabref.json to install with admin rights for all users
~/Library/Application Support/Google/Chrome/NativeMessagingHosts/org.jabref.jabref.json to install without admin rights for the current user
/Library/Application Support/Chromium/NativeMessagingHosts/org.jabref.jabref.json to install with admin rights for all users
~/Library/Application Support/Chromium/NativeMessagingHosts/org.jabref.jabref.json to install without admin rights for the current user
/Library/Microsoft/Edge/NativeMessagingHosts/org.jabref.jabref.json to install with admin rights for all users
~/Library/Application Support/Microsoft Edge {Channel_Name}/NativeMessagingHosts/org.jabref.jabref.json to install without admin rights for the current user
The {Channel_Name} in Microsoft Edge {Channel_Name} must be one of the following values: Canary, Dev, Beta.
When using the Stable release/channel, {Channel_Name} is not required.
Check that the Python script works. In Terminal run /Applications/JabRef.app/Contents/Resources/jabrefHost.py. If there are no errors the script is working properly. Stop the script by pressing Ctrl + D.
org.jabref.jabref.json directs the browser extension to a python script in the JabRef app, which is set to the most common install path by default (/Applications/JabRef.app/Contents/Resources/jabrefHost.py). If you have installed JabRef somewhere else, most likely to your local applications folder (~/Applications/JabRef), then you will need to update this path to the correct location. For example, in local installs this would be /Users/USER/Applications/JabRef.app/Contents/Resources/jabrefHost.py, where USER is your username.
language either as a string or as language code
Sometimes the new entry contains a url field. This field usually points to the URL of the book at the respective online book store. In case you buy the book using this link, the service provider (e.g., ) receive a commission to fund the service.
is a repository of scientific preprints in the fields of mathematics, physics, astronomy, computer science, quantitative biology, statistics, and quantitative finance ().
ID search is carried out using the .
is an official Digital Object Identifier (DOI) Registration Agency of the International DOI Foundation.
First, API is used to fetch bibliographic information based on the ISBN. If no entry is found, the JabRef tries to get data.
ID search is carried out using the .
is a database with publications from about Swedish universities and research institutions.
JabRef uses (provided by ) to convert the given DOI to a new entry.
The maintains an eprint archive to which anyone can submit papers and technical reports. These eprints are given IDs based on the year of submission, e.g. the 10th submission in 2018 gets the ID "2018/10". To get the ID, you may want to use their web search form at .
The Library of Congress is the research library that officially serves the United States Congress and is the de facto national library of the United States ().
ID search is carried out using the (LCCN).
is a searchable online bibliographic database. It contains all of the contents of the journal Mathematical Reviews (MR) since 1940 along with an extensive author database, links to other MR entries, citations, full journal entries, and links to original articles. It contains almost 3 million items and over 1.7 million links to original articles ().
is a bibliographic database of life sciences and biomedical information. It includes bibliographic information for articles from academic journals covering medicine, nursing, pharmacy, dentistry, veterinary medicine, and health care. Medline also covers much of the literature in biology and biochemistry, as well as fields such as molecular evolution ().
ID search is carried out using the (PMID).
is the multilingual European Registration Agency of DOI, the standard persistent identifier for any form of intellectual property on a digital network.
is an online database of over eight million astronomy and physics papers from both peer reviewed and non-peer reviewed sources. Abstracts are available free online for almost all articles, and full scanned articles are available in Graphics Interchange Format (GIF) and Portable Document Format (PDF) for older articles ().
ID search is carried out using the .
is an abstracting and reviewing service in pure and applied mathematics. Its database contains about 4 million bibliographic entries with reviews or abstracts currently drawn from about 3,000 journals and book series, and 180,000 books. The coverage starts in the 18th century and is complete from 1868 to the present by the integration of the "Jahrbuch über die Fortschritte der Mathematik" database ().
The importer based on the content has been written for IEEE and formatted papers. Other formats are not (yet) supported. In case a DOI is found on the first page, the DOI is used to generate the BibTeX information.
The next development step is to extract the title of the PDF, use the "Lookup DOI" and then the functionality from JabRef to fetch the BibTeX data.
We are also replacing the code completely by using another library. This is much effort and there is no timeline for that.
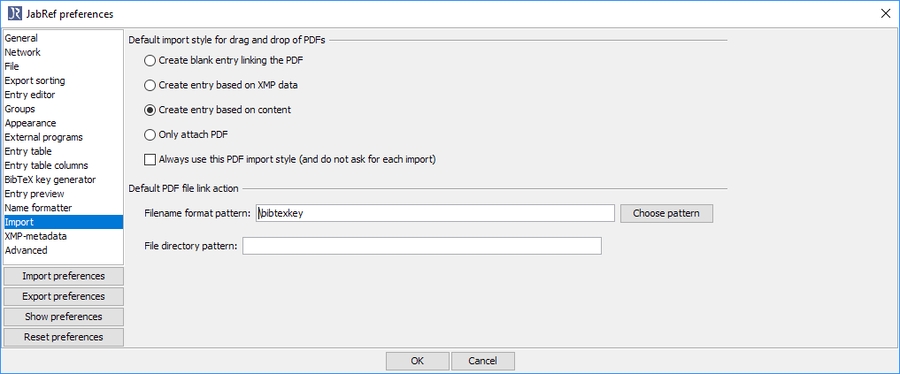
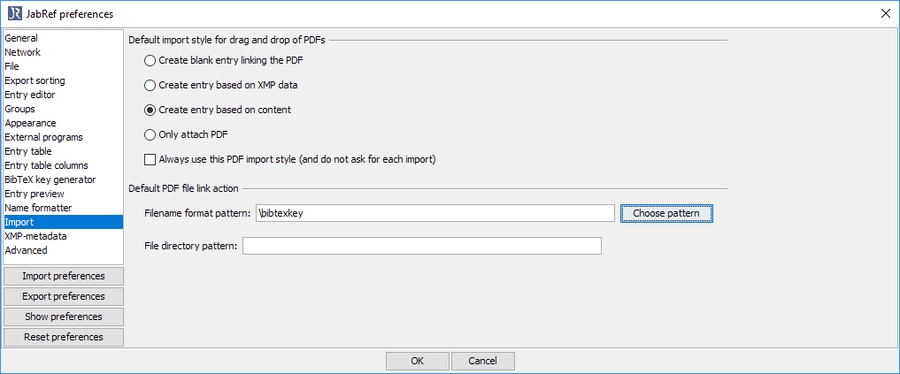
JabRef also offers to change the filenames. You can adapt the pattern at Preferences -> Import
Select "Choose pattern" and choose "bibtexkey - title" This results in the setting \bibtexkey\begin{title} - \format[RemoveBrackets]{\title}\end{title}.
JabRef used to have support for , which returned back a full BibTeX entry or a PDF. Due to unclear copyright situation of a used library, this service was removed. Further, Mr.DLib changes its focus and will provide literature recommendations. See .
Potential duplicates are pointed out by an icon in the second column. A click on this icon allows you to . A button on the left panel allows you to Deselect all duplicates (without inspection).
Finally, the opens and let you fill in the various fields.
Check your ExecutionPolicy by using Get-ExecutionPolicy -List in PowerShell. If you get something else than Undefined for your MachinePolicy, changes are high that this policy is set by Microsoft Group Policy. In this case the option -ExecutionPolicy Bypass in JabRefHost.bat won't work. If your MachinePolicy says AllSigned you can self-sign your JabRefHost.ps1 script, by following tutorials like .
Make sure you have at least installed.
Install the JabRef browser extension: , , ,
Download and install the Debian package of (>= 5.0).
Install the JabRef browser extension: , , ,
Firefox: Download and put it into
Chrome and Brave: Download and put it into
Note: Brave is using the Google file structure for NativeMessagingHosts, see .
Chromium: Download and put it into
Edge: Download and put it into
Install the snap package of (>= 5.0).
Install the JabRef browser extension: , , ,
Install the flatpak of .
Install the JabRef browser extension: , , ,
Download and install the DMG package of (>= 5.0).
Install the JabRef browser extension: , , ,
Firefox: If it's not auto-installed for you, download and put it into
Chrome and Brave: If it's not auto-installed for you, download and put it into
Note: Brave is using the Google file structure for NativeMessagingHosts, see .
Chromium based: If it's not auto-installed for you, download and put it into
Edge: If it's not auto-installed for you, download and put it into