To open the entry editor for a specific entry, you can either:
double-click on the entry in the table of entries
select the entry and press Enter
select the entry and go to the menu View → Open entry editor
select the entry and press CTRL + E
Then you can modify the content of the entry. When done, click on the top left-hand corner of the entry editor or press ESC to close the entry editor and go back to the table of entries.
Cite
Include citations of your references to your documents.
Based on the .aux file generated by LaTeX, JabRef can create a subdatabase containing only the cited entries.
This feature is available through Tools → New subdatabase based on AUX file.
Knowledge
JabRef Bibliography Management
Stay on top of your literature: JabRef helps you to collect and organize sources, find the paper you need and discover the latest research: JabRef is an open-source, cross-platform citation and reference management tool.
To get started, please follow the installation instructions and familiarize yourself with the basics of JabRef.
Use the Search icon at the top left of this page to find what you're looking for. To learn more about JabRef's features, please follow the links below.
across many online scientific catalogs like CiteSeer, CrossRef, Google Scholar, IEEEXplore, INSPIRE, Medline/PubMed, MathSciNet, Springer, arXiv, and zbMATH
for over 15 reference formats
Easily retrieve and link full-text articles
such as ISBN, DOI, PubMed-ID and arXiv-ID
Import new references directly from the browser with one click using the for , , and
using a convenient user interface
your research into hierarchical collections and organize research items based on keywords/tags, search terms or your manual assignments
Native
for external applications such as Emacs, Kile, LyX, Texmaker, TeXstudio, Vim and WinEdt
Format references in one of the many thousand built-in citation styles or create your style
or
Library is saved as a simple text file, and thus it is easy to e.g. via Dropbox and is version-control friendly
Work in a team: sync the contents of your library
JabRef is and adapts to you, not the other way around.
If you want to dive even deeper, have a look at the about JabRef.
Import
This help page should describe the menu File -> Import (and the various file formats available).
Please, populate this page. Visit our page about .
JabRef can be either installed (the preferred way) or be used as a portable application.
To get the latest version, head to , download the installer for your system (e.g., dmg files for MacOS and msi files for Windows), run them and follow the on-screen instructions.
Version
🍎
🐧
Add entry manually
To add a new entry, select Library → New entry..., press CTRL + N or click on the dedicated icon of the toolbar.
A dialog window is displayed. By default, 5 common types of entries are displayed:
For other types of entries, click on Others. That expands the window and displays the other entry types available:
Finally, the opens and let you fill in the various fields.
Add entry using reference text
Entries can be created from a reference text.
In case you have a reference string, JabRef offers the functionality to convert the text to BibTeX (or biblatex). For this, JabRef uses the technology offered by .
Example:
Click Library and select "New entry from plain text..." Alternatively, you can press Ctrl+Shift+N.
Organize
Organizing your database with JabRef
JabRef is designed to facilitate your workflow.
You can select a subset of entries using the . Within a library, you can organize your entries in a tree-like structure made of .
You can add information to an entry using the , but JabRef can also for you. And JabRef takes care of the (PDF, etc.)
Once your database starts to be large, some tidy-up may be needed. JabRef can , , , help you in .
Hence, your database is always clean and up-to-date.
Comment on an entry
Add comments on an entry
One can add free text to an entry. This is possible in the "Comments" tab of JabRef.
There is the general "comments" field.
JabRef offers to separate comments from as well as user-specific comments field.
The following screenshots show the comments for the user koppor. As default, general comments are managed through the field comment. In addition, the field comment-koppor stores the comments of the user koppor.
Now, lets assume, the library (.bib File) is shared among different users.
Complete information using online databases
JabRef can fetch automatically additional information about your entries. It can even get the publication file!
To find identifiers (arxiv, DOI)_: select the entries and go to the menu Lookup → search document identifier online.
To find the DOI: open the , and in the General tab, click on the button Lookup DOI.
Manage field names and their content
Modify easily the field names and the field contents
After selecting a set of entries, go to Edit → Manage field names and content, to set, append, rename and clear a field.
This dialog window is displayed:
Set the field name (by typing it in or using the drop-down menu), and select the action to be carried out. Additionally, a checkbox allows overwriting the existing field values.
The actions are:
BibTeX and biblatex
The data format of JabRef is BibTeX. In addtion JabRef also supports biblatex.
JabRef is is a program for working with BibTeX and biblatex libraries. JabRef program uses no separate internal file format but directly works with BibTeX and biblatex. That means, your BibTeX/biblatex file is kept as is when opening in JabRef and saving again: You normally load and save your libraries directly in the BibTeX/biblatex.bib format. In addition, you can also and export bibliography libraries in a number of other formats into JabRef.
The library mode can be changed in the .
More information on BibTeX is available on .
Check integrity
JabRef can check the integrity of a library.
This feature is available through Quality → Check integrity.
Share
JabRef allows sharing both and . You can also .
Customize key bindings
This feature is available through File → Preferences → Keyboard shortcuts.
You can reset the keyboard shortcuts to default by pressing the "Default" button. This is especially useful when upgrading from a JabRef version before 3.8.2.
Export
The order of the exported entries can be set in File → Preferences, tab File, under the menu "Export sort order".
See also:
Manage external file types
For each file link, a file type must be chosen, to determine what icon should be used and what application should be called to open the file. The list of file types can be viewed and edited by choosing Options → Preferences, tab External file types.
A file type is specified by a graphical icon, a name, a file extension and an application to view the files. On Windows, the name of the application can be omitted in order to use Window's default viewer instead.
Customize general fields
You can add an arbitrary number of tabs to the entry editor. These will be present for all entry types. To customize these tabs, go to Options → Preferences → Custom editor tabs.
You specify one tab on each line. The line should start with the name of the tab, followed by a colon (:), and the fields it should contain, separated by semicolons (;).
For example:
will give one tab named "General" containing the fields url, keywords, doi and pdf, and another tab named "Abstract" containing the fields abstract and annote.
It does not matter how you capitalise your field names. In the entry editor's tabs, normally fields' first letter is capitalised, i.e. abstract is represented as
Send as email
JabRef allows you to send entries to third parties via email.
Select one or multiple entries
Choose Tools → Send as email in the menu
This will open your default email application and automatically paste the entries in their raw BibTeX format. Once your correspondents have received the email, they will be able to directly copy and paste the entries into JabRef (or use them in other ways).
Field content selector
The preferences for this feature are accessible via Library → Library properties → Content selectors and allows you to store often-used words or phrases. This creates the possibility to conveniently make use of them in the entry editor to fill in field content.
To add a new word by using the content selector in the entry editor, you can simply click into the text box for the field for which you configured the selectors. A drop down menu will appear and you can select the keyword of your choice. This mechanism is based on the functionality in JabRef (File → Preferences → Autocompletion) . Therefore, you need to have autocompletion enabled in your preferences.
By default, the feature is enabled for the fields Journal, Author, Keywords and Publisher, but you can also add selectors to other fields.
The word selection is library-specific, and is saved along with your references in the .bib file.
The Bibtex / Biblatex source tab
The biblatex source tab allows you to add and edit BibTeX entries by simply typing the desired content using correct BibTeX syntax. Advanced users may at times find this to be the speedier option. The required syntax is extensively described in .
Additionally, here the data is shown "as is", which means special symbols that are usually supposed to be hidden or translated into readable form, may show regardless.
License
The JabRef software is under the . In short, JabRef is free to use, even commercially. You can also redistribute and modify JabRef as long as you include the original copyright and license notice in any copy of the software/source.
The documentation of JabRef is under the . In short, you can make a commercial use of it, distribute it, modify it and rename it. You must give credit, include copyright, and state changes. And you cannot sublicense it.
Sharing a Bib(la)TeX Library
When sharing a Bib(la)TeX library, JabRef automatically recognizes a change in the bib file on disk and notifies the user of it. This works well on network drives.
Note: the use of a version control system (SVN, git, etc.) is recommended as this will allow for reverting changes.
To make the sharing of a Bib(la)TeX library easier, it is recommended to set specific library properties. In the menu Library → Library properties:
Select UTF-8
Configuration
JabRef is highly customizable, allowing users to get the behaviour they expect.
The File → Preference menu command allows you to configure the JabRef interface, and to set the default features of your libraries. Features specific to a given library are configured in the Library menu. For example, while the default key patterns are set in File → Preferences → Citation key generator → Key patterns, key patterns specific to a library can be set in Library → Citation key patterns.
Remote operation
This feature can be toggled and configured under Preferences → Network.
Note that activating this feature under Windows XP SP2 (and possibly other configurations) may prompt a message box stating that certain features of the program have been blocked by the Windows firewall. You can safely tell the firewall to keep blocking - the firewall will not interfere with remote operation of JabRef.
If listening for remote operation is enabled, JabRef will at startup attempt to start listening to a specific port. This means that other applications can send information to JabRef through this port. JabRef will only accept local connections, to avoid the risk of interference from outside.
Binding to this port makes it possible for a second JabRef instance to discover that the first one is running. In this case, unless specifically instructed to run in stand-alone mode, the second JabRef instance will pass its command line options through the port to the first JabRef instance, and then immediately quit.
The first JabRef instance will read the command line options, and perform the indicated actions, such as reading or importing a file, or importing a file to the currently shown database. If a file is imported using the command-line option
The 'owner' field
JabRef can optionally mark all new entries added or imported to a library with your username.
You can disable or enable this feature by entering Options → Preferences → General, and selecting/deselecting the line 'mark new entries with owner name'. You can also change the name used to mark entries. By default, your user name is used. Finally, if an entry with an existing field 'owner' is imported, the field is updated with your name if 'Overwrite' is checked.
The owner name is added in a field called 'owner', which by default is visible in the General fields tab in the .
Advanced information
as encoding.
Define a General file directory, which will be used to store shared PDF (and other) files.
Check Refuse to save the library before external changes have been reviewed.
Define a sort order (year, author, title is recommended)..
Check Enable save formatters, and defines these actions, to help enforcing a consistent format for the entries.
--importToOpen
, the imported entries will be added to the currently shown database. If no database is open, a new one will be created.
Once Send as email is pressed, JabRef will also automatically open the folder of attached files, as long as the option automatically open folders of attached files is enabled at File → Preferences → External programs → Sending of emails. Attaching these files to your email is possible by dragging and dropping the PDF files into your favorite email application.
How to send as e-mail
How to attach linked files of entries to your email
Most menu actions referred in the following have keyboard shortcuts, and many are available from the toolbar. The keyboard shortcuts are found in the pull-down menus.
This is the main window from where you work with your databases. Below the menubar and the toolbar is a tabbed pane containing a panel for each of your currently open databases. When you select one of these panels, a table appears, listing all the database's entries, as well as a configurable selection of their fields.
You decide which fields are shown in the table by checking the fields you want to see in the Preferences → Entry table dialog.
Double-click a line of the table to edit the entry content. You can navigate the table with the arrow keys.
Preferences → Entry table, but to more quickly change the order, click the header of a column to set it as the primary sort criterion, or reverse the sorting if it is already set. Another click will deselect the column as sorting criterion. Hold down Ctrl and click a column to add, reverse or remove it as a sub-criterion after the primary column. You can add an arbitrary number of sub-criteria, but only three levels will be stored for the next time you start JabRef.
Adjust the width of each column by dragging the borders between their headers.
EndNote Export Filter
Abstract
,
KEYwords
would be represented as
Keywords
(
DOI
,
ISBN
,
URL
are exceptions in that all letters are capitalised). In the bibtex code, all field names use lower case:
Alternatively, on Windows, you can use the chocolatey package manager and execute choco install jabref to get the latest version. On Ubuntu, you can use snap install jabref to get the latest stable version from snapcraft.
The portable version of JabRef is designed to be run from a USB stick (or similar) with no installation.
Download it from downloads.jabref.org. These are generic archive files (e.g., tar.gz files for Linux and MacOS, and zip files for Windows) which need to be extracted. Inside the archive files you will find the file needed to run JabRef:
for Windows JabRef.exe.
for Linux
either runbin/JabRef
or /lib/runtime/bin/JabRef.
for Mac, this is the file JabRef.app.
Be sure to activate "Load and Save preferences from/to jabref.xml on start-up (memory stick mode)" in Options → Preferences → General. Also, if the Linux version of JabRef portable is put into a folder named bin, it will not start. Other names are fine, like apps.
If you want to take advantage of the latest features, you can use pre-built binaries crafted from the latest development branch. To use the prebuilt binaries, visit builds.jabref.org/main and download the packaged binaries (e.g., dmg files for MacOS and exe files for Windows), run them and follow the instructions.
If you want to try the development version in parallel with the stable version, we recommend to download the portable version (e.g. JabRef-X.Y.portable_windows.zip, JabRef-X.Y.portable_macos.tar.gz, or JabRef-X.Y.portable_linux.tar.gz) from builds.jabref.org/main to ensure that both versions do not conflict.
WARNING: Could not open/create prefs root node Software\JavaSoft\Prefs at root 0x80000002. Windows RegCreateKeyEx(...) returned error code 5.
start regedit and create the following key: HKEY_LOCAL_MACHINE\SOFTWARE\Wow6432Node\JavaSoft\Prefs. []
How can I start or focus JabRef with hotkey ⊞+J (Win+J)?
Use and provided at .
OpenOffice/LibreOffice integration
The connection from JabRef to Libre Office requires some office related jar-archives to be present. For this, you have to install the package libreoffice-java-common.
External program integration in Snap and Flatpak packages
The snap and flatpak packages cannot interact directly with external programs (i.e. programs not contained in the package sandbox). What this means is that for now there is no possible connection between JabRef and Libreoffice if either one is a snap/flatpak.
The integration with TeX editors is fine if JabRef is a deb/rpm, and the editor is a snap/deb/rpm (not a flatpak).
I cannot start JabRef 5.9 due to file beeing damaged
Execute xattr -d com.apple.quarantine /Applications/JabRef.app (This is a known problem related to Apple's notarization)
JabRef is slow/hangs sometimes
Some users with macOS Sierra have reported freezes when using JabRef. It seems this is a bug in the networking part of Java on macOS. seems to solve these issues.
Some characters are not displayed in the main table (math characters or some upper-cased letter)
This is one the one hand a font problem and second a lognstanding . This might be a problem related to the font you are using. You can download some other font that supports mathematical alphanumeric symbols, for example, FreeSerif or Cambria Math. A list of fonts supporting Math Unicode blocks is available at
This method is mainly for package maintainers and users who would like to build the latest snapshots of JabRef directly from the source. If you want to setup JabRef for development, follow the instructions for setting up a workspace.
To build JabRef from source, you first need to have a working Java Development Kit (see above link for details) and Git installed on your system. After installing the two requirements, you open a terminal window (i.e., a command prompt) and type the following:
In a nutshell, you clone the latest snapshot of JabRef into jabref directory, change directory to jabref, initialize and update all the submodules (dependencies) of JabRef, assemble them to be built via JDK and finally build and link them together.
The output should be the build/image subdirectory that contains the JabRef binary with all of its Java dependencies. To start JabRef, you need to run bin/JabRef (in Linux and MacOS) or bin/JabRef.bat (in Windows) under build/image subdirectory.
closed the library and opened it later again. He sees that a user
otheruser
has written a comment:
JabRef showing the comment of the user "otheruser".
Now, koppor desides, that he does not want to add any comments in JabRef, so he pushes the "Hide user comments" button. Then, JabRef does not display the comment field for koppor's user any more:
JabRef's entry editor showing the general comment field and a comment of another user.
A bit later, koppor thinks, he wants to put comments again. To achieve that, he needs to navigate to File -> Preferences -> Entry editor. Then, he needs to add a checkmark to "Show user comment fields". then, he needs to press "Save" to save the preferences.
Preference to enable user-specific comments
Then, JabRef's entry editor shows the field "Comment-koppor" again.
JabRef's entry editor showing two comment fields
To find the document related to an entry: select the entry and to the menu Lookup → search full text documents online.
Be aware: The options above require your entry or entries to be filled with enough and correct bibliographic information. If the entry holds incomplete or inaccurate data, fetching the identifier or text document my fail.
JabRef can help you complement your entries with bibliographic data, which is associated with their registered DOI or ISBN. This is a very reliable way of obtaining correct bibliographic information and is very much recommended.
The following features require your entry to have a DOI or ISBN and are disabled / greyed out otherwise.
Option A) In the entry table, right-click on the entry to complement, and select the menu Get bibliographic data from DOI/ISBN/...
Option B) Open the entry editor, and in the General tab, click on the button Get bibliographic data from DOI
Using any of the options opens the window Merge entries:
There it is possible to choose what is kept for each field: the left side, the right side, or the merged entry. By default, the original entry (left) is kept, and any fields not present in the original entry are obtained from the information collected from the DOI.
Finally, after selecting which fields to keep, you can decide to Merge entries. Alternatively, you can press Cancel.
Set fields. Enter the field content to be used. For example, "Field name = owner" and "Set fields = Smith" adds the line "owner = {Smith}," to the entries. If the field "owner" is already present in an entry, it is not modified, except if "Overwrite existing field values" is checked.
Append to fields. Enter the string to be appended at the end of the field content (if the field does not exist, it will be created). For example, "Field name = keywords" and "Add to fields = , programming" adds the keyword "programming" to the list of keywords.
Rename field to. Enter the new name for this field. For example, "Field name = institution" and "Rename fields = school" renames the field "institution" into "school". The field content is not altered.
Clear fields. This removes the field from the entries. For example, set the "Field name" to "comments". If "Overwrite existing field values" is checked, all the fields "comments" (and their content) are removed. If it is not checked, only the empty fields "comments" are removed.
To select all the entries of the current library, pressCTRL + A.
External resource:
You can directly create a new entry of a specific entry type by using a keyboard shortcut. We strongly recommend learning the shortcuts for the entry types you use most often, e.g. Ctrl + Shift + A for adding an article entry. See Options → Customize key bindings.
Window for selecting default entry types. Note: the actual content of the "others" menu depends on the database mode (BibTeX or biblatex).
Window with all available entry types. Note: the actual content of the "others" menu depends on the database mode (BibTeX or biblatex).
In general, there is no need to change the settings of external file types. So, this setting is for advanced users.
Manage external file types
Check integrity dialog
Mark and grade
Qualify your entries with tags that make sense to your work.
A set of 6 special fields allows you to tag your entries in order to rate read papers, indicate their relevance to your work, indicate that their quality has been assured, etc. Internally, each special field is stored in a separate BibTeX field.
This feature has to be activated in File → Preferences → Entry Table by checking the item Enable special fields.
The status of each special field can be displayed in the table of entries as dedicated columns.
Six special fields can be displayed in the table of entries
Like any other field, the special field columns can be turned on and off individually in File → Preferences → Entry Table.
You can see the value of a special field by:
clicking in the column.
a right-click on an entry.
the menu Edit.
An entry can be marked as relevant: a black-and-white star is displayed (in the first column of the image below).
The read status can be set to "No" (no symbol in the column), to "Skimmed" (an orange eye), or to "read" (a green eye).
JabRef offers a rank from one to five yellow stars to rate your papers. By default, no rank is given.
An entry may be marked as quality assured (fourth column in the image below). For example, you can mark the entries for which a thorough check of the field contents has been done.
You can set the priority of an entry from low (red flag) to high (green flag). For example, you can use it to prioritize unread papers.
This field allows to state is the paper has been printed or not (sixth column in the image above).
Keywords
Keywords help you in organizing, sorting and searching your entries.
The field "keywords"
Keywords can be added to your entries in a specific field. In the entry editor, the keywords field is displayed in the General tab. There, you can add new keywords to an entry by typing it in. If auto-completion is activated for the field keywords (File → Preferences → Entry editor), suggestions are given based on existing keywords.
By default, the keyword separator is a comma. It can be redefined in the preferences (File → Preferences → Groups).
If some entries have a keyword separator differing from the prescribed one, you can use menu Edit → Find and replace. For example, you may want to replace semi-columns (;) by commas (,). Select the radio button "Limit to Fields" and type in "keywords" as the relevant field.
Additionally, the special field values (relevance, priority, etc.) can be added to the keywords field automatically. This will allow you to group, sort, and search your library based on the special field values. See in File → Preferences → Entry table the item "Special fields" and select "Synchronize with keywords".
Management of keywords
Managing the keywords of specified entries
Select at least one entry and go to Edit → Manage keywords.
The keyword list is displayed in two modes:
the keywords shared by ALL of the selected entries.
the keywords appearing in ANY of the selected entries.
You can edit a keyword by double-clicking on it, or by clicking on the pencil icon. A keyword can be deleted by clicking on the minus icon.
To fasten the addition of often-used keywords, JabRef can store the list of your preferred keywords.
Go to File → Manage content selectors.
First, click on the field name "Keywords". Then, enter the list of your preferred keywords. Now, when you start to type one of your preferred keywords, JabRef will display a list of the matching ones (independently of the auto-completion). For more details, see the help section about .
You can search for entries having specific keywords. For this, use a regular expression search, such as anykeyword matches apple or keywords = modell?ing. For more details, see the help section about .
Different types of groups can be created based on the values of the field keywords. See the help section about .
Merge entries
JabRef can help you to merge entries of your library.
First, select the two entries to be merged. Then select the menu Quality → Merge entries. Alternatively, select the right-click menu Merge entries.
The Merge entries window will pop up:
Diff Highlighting
The differences between the two entries can be configured through the toolbox located at the top of the window. From the toolbox, you can choose to show or hide differences, choose how to display differences (Unified or Split) and you can also choose how to compare entries (by words or characters).
Show or Hide Differences
Plain Text — This option hides the differences.
Show Differences — This option shows the differences.
Unified View — In this mode, differences are shown on the right side.
Split View — In this mode, differences are shown on both sides, with deletions on the left side and additions and updates on the right side.
Highlight words — This option compares entries values in terms of words.
Highlight characters — This option compares entries values in terms of characters. It divides both entry values into characters before comparing each character individually. This is perfect for comparing values with small differences (1 or 2 different characters).
From the toolbox's top-left corner, you also can choose to select all the left entry values by clicking Left or selecting all the right entry values by clicking Right. Be aware that selecting all entry values will select a value even when it is empty.
When merging entries, sometimes you want to select both values for a certain field. A common use case for this would be wanting the merged entry to have both the left and right entry groups. Now, you can simply click the merge button next to the groups label and we’ll take care of the rest. We’ll merge the left and right entry groups, keeping only one copy of any common group. And this works for more than just groups - you can also merge keywords, comments and files. So go ahead and give it a try - it’ll make your life a lot easier.
There are two buttons at the end of each field cell: one for copying the content of the field cell, and the other for opening links; at the moment, only URLs and DOIs can be opened.
For each field, you can select whether to choose the left entry value or the right one. You can do that by clicking on the given field cell. Once you did that, the merged entry will update its content to reflect the new change.
You can also edit the merged entry values manually. Doing so, will update the selected field cell if the left or right cell equals that value you typed.
Finally, after selecting which fields to keep, you can decide to Merge entries. Alternatively, you can press Cancel.
See also:
Migration of pre-3.6 SQL databases into a shared SQL database
Context
This situation occurs when you try to open an SQL database which was created with JabRef version older than 3.6.
With release of JabRef 3.6 the SQL database structure has changed. So all SQL databases with an pre-3.6 structure are no longer supported.
Screenshot of migration popup
Migration
To migrate your pre-3.6 SQL database into new shared SQL database you have to follow these steps:
Open JabRef and goto File -> Import from external SQL database
Enter required data and click on Connect
Choose the database which should be imported and press Import
Save the database locally (File -> Save database)
Turn back at least to
Goto: File -> Open shared database
Enter required data and click on Connect
Now goto File -> Import into current database
Choose the file you saved locally and import it
After that the content is available as a shared SQL database and you can work live on it. .
Export to Microsoft Word
You can import your citations into a Microsoft Word document through JabRef's export feature. Please follow the steps below for instructions on how to export your JabRef sources into a Microsoft Word document.
Select the "File" tab in the upper lefthand corner of JabRef, hover over "Export", and select "Export selected entries". Be sure to save your file as a "MS Office 2007" file.
Open Microsoft Word and click on the "References" tab.
Select "Manage Sources", click "Browse", and locate the desired file. The file type should be an XML document.
Mac OS users will not see a "Manage Sources" button. Mac users should follow these steps:
a.) Copy the selected file to /Library/Containers/com.microsoft.word/Data/Library/Application Support/Microsoft/Office or alternatively to /Users/{username}/Library/Containers/com.microsoft.Word/Data/Library/Application Support/Microsoft/Office/ and name it Sources.xml
b.) Restart Word
c.) Select "References", and then select "Citations"
d.) A sidebar will open on the right side of the window. Click the icon with three dots.
e.) Click “Citation Sources Manager” from the drop down bar.
f.) Copy over your citations from the masters list.
Click on "Bibliography" under the "References" tab to add your cited sources.
More discussion at . See
For a detailed list of the fields which are exported in the Office 2007 XML format see the following page.
Cleanup entries
Tidy up your library
JabRef can cleanup the entries of a library. To do a cleanup of the entries, go to Quality → Cleanup entries. Then select the actions to be carried out.
The Cleanup entries dialog
under the tableEnable field formatters. Then, under the table, you can select using 2 drop-down menus:
an entry field (upon which the action will be applied).
the type of action to be carried out (such as HTML to LaTeX, which converts HTML code to LaTeX code, as described in the window). See the .
A click on the "circular arrow" icon enables a set of recommended formatting actions (the set of actions will depend on your database type: BibTeX or biblatex).
Best practices
How JabRef can make your life easier
Helpful groups
Group for your own papers: author=YOURSELF
Group for the papers of your team: author=YOURSELF and author=COLLEAGUE1 and author=COLLEAGUE2
Use Quality → Check integrity often to ensure that the quality of your library does not degrade.
To ensure that your library stays consistent, specify your save actions in Library → Library properties.
Customize entry types
To customize entry types, select the menu File → Preferences → Entry types.
When customizing an entry type, you both define how its entry editor should look, and what it takes for JabRef to consider an entry complete. You can both make changes to the existing entry types, and define new ones.
Using the entry customization dialog
Screenshot of the entry customization dialog
The entry customization interface is divided into two areas. On the left side all entry types (including any custom types) are listed. If you select a type from the left side, the right area shows all fields for the selected entry.
Adding and removing entry types
The currently available entry types are listed in the left panel.
To add a new entry type, you must enter a name for it in the text field below the type list, and click Add. The new entry type will be added to the list, and selected for modification.
To remove a custom entry type, select it and click the trash icon. This operation is only available for custom entry types that are not merely modifications of standard types. It is not possible to remove a standard entry type.
When an entry type is selected, the current required and optional fields are listed on the right. A radio button indicates and allows to change the field's type from required to optional and vice versa.
To add a new field, edit the text field below the list, or select a field name from the dropdown menu, then click Add. The chosen field name will be added at the end of the list.
To remove a field select it in the list and click the trash icon to remove it.
To change the order of the fields you can use drag and drop.
Certain entry types have an either-or condition in their required fields. For instance, a book entry is complete with either the author or the editor field, or both. To indicate such a condition in a custom entry type, you should add a field named as the set of alternative fields separated by slashes, for instance author/editor indicates the condition mentioned above for the book entry type.
Entry preview setup
Location
The Entry Preview is located inside the Entry Editor (except when navigated to the File annotations or {} biblatex source tab):
Entry Preview
You can display the entry preview as a separate tab (see screenshot above) by checking the box Show preview as a tab in entry editor in the entry preview settings Options > Preferences > Entry preview > Current Preview (see screenshot below).
Layouts/Styles
The entry preview displays either the Customized Preview Style or a certain Citation Style. You can select the styles that should be available for display in Options → Preferences → Entry preview. In Available you find all styles selectable for display, in Selected all styles already selected for display:
You can switch between all selected styles (customized preview and citation styles) in the entry preview in the main window by pressing F9.
The layout is automatically created using the same mechanism as used by the facility. When previewed, an entry is processed using one of the selected layouts/styles to produce HTML code which is displayed by the preview panel.
To customize the appearance and contents of the customize entry preview you need to edit/modify the customized preview style in the entry preview settings (see screenshot above) using the custom export filter syntax described in the .
The string editor
In JabRef you write the contents of all fields the same way as you would in a text editor, with one exception: to reference a string, enclose the name of the string in a set of # characters, e.g.: '#jan# 1997', which will be interpreted as the string named jan followed by 1997.
Strings can be edited by Library → Edit string constants or pressing a button in the toolbar.
Strings are the BibTeX equivalent to constants in a programming language. Each string is defined with a unique name and a content. Elsewhere in the database, the name can be used to represent the content.
For instance, if many entries are from a journal with an abbreviation that may be hard to remember, such as 'J. Theor. Biol.' (Journal of Theoretical Biology), a string named JTB could be defined to represent the journal's name. Instead of repeating the exact journal name in each entry, the characters '#JTB#' (without quotes) are put into the journal field of each, ensuring the journal name is written identically each time.
A string reference can appear anywhere in a field, always by enclosing the string's name in a pair of '#' characters. This syntax is specific for JabRef, and differs slightly from the BibTeX notation that is produced when you save your database. Strings can by default be used for all standard BibTeX fields, and in Options → Preferences → File you can opt to enable strings for non-standard fields as well. In the latter case you can specify a set of fields that are excepted from string resolving, and here it is recommended to include the 'url' field and other fields that may need to contain the '#' character and that may be processed by BibTeX/LaTeX.
A string may in the same way be referred in the content of another string, provided the referred string is defined before the referring one.
While the order of strings in your BibTeX file is important in some cases, you do not have to worry about this when using JabRef. The strings will be displayed in alphabetical order in the string editor, and stored in the same order, except when a different ordering is required by BibTeX.
For a complete description of string syntax, see the .
How to expand first names of an entry
Sometimes, one has a BibTeX/biblatex entry with abbreviated short names:
@Article{Eshuis_2015,
author = {R. Eshuis and A. Norta and O. Kopp and E. Pitkanen},
journal = {{IEEE} Transactions on Services Computing},
title = {Service Outsourcing with Process Views},
year = {2015},
month = {jan},
number = {1},
pages = {136--154},
volume = {8},
publisher = {Institute of Electrical and Electronics Engineers ({IEEE})},
}
Now, one wants to have the full first names. In case, there is a DOI available, this is as simple as the following steps:
Determine the DOI: Switch to the "General" tab and click on "Look up DOI"
Screenshot of determine DOI
Fetch BibTeX data from the DOI: Click on "Get BibTeX data from DOI"
A popup appears. Select which data you want to merge into the eixting entry
JabRef lets you link documents on the web in the form of an URL or a DOI identifier.
Setting up external viewers
JabRef has to know which external viewers to use for web pages. These are by default set to values that probably make sense for your operating system, so there's a fair chance you don't have to change these values.
To change the external viewer settings, go to Options → Preferences → External programs.
Opening external links
There are several ways to open an external web page. In the entry editor, click on the icon "open" right of the text field to open the respective DOI or URL.
Open DOI
In the entry table you can select an entry and use the menu choice, keyboard shortcut or the right-click menu to open the file or web page. Finally, you can click on a URL or DOI icon.
By default the entry table will contain a singly column containing an indicator whether there is a DOI or a URL linked. You can remove the "Link identifiers" column in Options → Preferences → Entry table.
Manage protected terms
This feature is available through File → Preferences → Protected terms files.
This help page should describe the menu Options → Preferences → Protected terms files..
Please, populate this page. Visit our page about .
Find duplicates
JabRef can look for duplicated entries inside a library.
This feature is accessible directly through Quality → Find duplicates. It is also used when from a supported reference format or directly from the Internet.
Detection of potential duplicates is done by an edit distance algorithm. Extra weighting is put on the fields author, editor, title. and journal.
The differences between the two entries can be configured through the toolbox located at the top of the window. From the toolbox, you can choose to show or hide differences, choose how to display differences (Unified or Split) and you can also choose how to compare entries (by words or characters).
Import inspection window
When you import new entries from a supported reference format or fetch entries directly from the Internet, the inspection window allows you to select the entries you want to keep, to , and to perform some simple operations like generating citation keys for the entries or adding them to . If you are importing into an existing database, it is often easier to perform these operations before they are mixed in between the entries of your database.
Entries are first shown in the inspection window. Note that, if this takes too long (for example), you can click on the button Stop at the bottom of the window.
Once the entries displayed in the inspection window, none of them have been added to one of your databases yet.
By default, all the entries are selected for importation, as shown by the checked boxes in the Keep column. You can select/unselect an entry by clicking on these checkboxes. On the left panel, buttons allow you to Select all the entries for importation, or to Deselect all
LaTeX Citations Tab
This tool allows you to search for citations in LaTeX files.
In the user interface, a tab was added to the entry editor, the aesthetics have been improved, and the tool was renamed to Search for Citations in LaTeX files.
A new tab was added to the entry editor. It allows to search for citations to the active entry in the LaTeX file directory. It can be configured in the .
See the image below to see how it works:
Shared SQL Database
JabRef is able to support collaborative work using a shared SQL database.
To use this feature you have to connect to a remote database. To do so you have to open File in the menu bar and then click the Connect to shared database item. The Connect to shared database dialog will open and you will have to fill in the shared's database connection settings. Under the field Database type you can choose between PostgreSQL (at least version 9.1), MySQL (at least 5.5, not recommended, because there is no live synchronization), and Oracle depending on your shared database. Then, you have to fill out the remaining fields with the according information. If you like you can save your password by clicking the Remember password? checkbox.
Since version 5.0 JabRef supports secure SSL connection to the database. For PostgreSQL make sure the server supports SSL and you have correctly setup the . Then into a java readable format and import them into a (custom) keystore. For MySQL the procedure is similar. and for the java keystore. However, it has only been tested with PostgreSQL. Once the certificates are imported into the keystore, specify the path to the keystore file in the connection dialog and the password for accessing the keystore.
Pushing to external editor application
Inserting a citation directly in your editor.
JabRef allows you to push any entries in your main window to an external editor through the push-to-external application feature. It works with Emacs, LyX/Kile, Texmaker, TeXstudio, Vim, and WInEdt.
To push as citation, first select the entries in your entry table that you would like to push. Then, either:
go to Tools → Push entry to external application
Press
Time stamp field
JabRef can optionally set a field to contain the date an entry was added to the database.
You can disable or enable this feature by entering File → Preferences → General, and selecting/deselecting the line 'Mark new entries with addition date'.
If an entry with a timestamp is pasted or imported, the field is updated with the current date if 'Overwrite' is checked. The value of the timestamp field will be updated upon changes in the entry if 'Update timestamp on modification' is checked.
By default, the date is added in a field called 'timestamp', which is visible in the General fields tab in the . You can alter the name of this field. The date format can also be customized (see below).
The timestamp field can be edited in the
Links to other entries
JabRef supports following fields to jump to other entries.
Following fields are supported:
cites - comma separated list of citation keys which are cited by this entry
crossref
Custom themes
Since JabRef 5.2 it is possible to use custom themes. In Preferences > Appearance > Visual theme the themes in general can be changed. Themes are just files defining the look of the UI.
Light Theme: The default theme is the light theme ().
Mac OS X
A: Currently this is necessary, since our code signing infrastructure is not operational. Ctrl-click to open the downloaded .dmg file in Finder to install JabRef.
Because we could not get 5.9 notarized correctly from Apple this step is unfortuantely necessary.
A: To override that, Ctrl + Click instead, and choose "open", which gives the same warning but the possibility to override it. then you can install.
A: This is a problem some users experience in JabRef 4.0 or later on MacOS Sierra. It seems this is a bug in the networking part of Java on MacOS. You can try to add localhost explicitly to
The only problem in the export could be when you have a "company" as author. That is simply exported as author and not in the company field.
related - comma separated list of citation keys which are in some kind related to this entry. The type of all relations can be specified by a single relatedtype (see https://github.com/plk/biblatex/issues/475#issuecomment-246931180). Note: biblatex prints this information if related is active at the biblatex package.
To use the crossref field, navigate to the general tab and insert the Crossref at the top.
To use cites and related, follow these steps:
Navigate to Bib(la)TeX source
Insert related = {citationkey},
Close the entry editor
Open the entry editor
Navigate to "Other fields"
There, you now see "related" with the possibilities to (i) navigate to the entry, (ii) add new related entries, (iii) remove related entries.
If you use crossref, JabRef will move these entries first in the bibliography as otherwise BibTeX cannot use the information of the cross-referenced fields. See also http://tex.stackexchange.com/a/148978/9075.
Please note that biblatex treats crossref differently than BibTeX.
citedBy - this is the opposite of cites. Use cites instead.
relations - this would introduce a complicated field similar to our save actions. A simple key/value is enough
references - stores all references in plain text (PRVV plugin). Thus, we do not use it.
Depending on your use case and needed integrations it is advisable to choose the proper packages. Watch this page for new developments on the interactions with external programs.
Snap
Flatpak
deb/rpm
tar
Libreoffice (system)
❌
❌
✅
Change default application to open files for JabRef snap
When JabRef is installed as a snap, it initially asks which application should be used to open PDFs (or other files). However, after selecting the same application three times, that application is set as default and there is no obvious way to select another application ("Preferences" -> "External File Types" does not help here, because the snap sandbox does not "see" any of the user's applications). This setting is stored in the XDG permission storage, and can be changed with a command like the following (see this forum thread for further information, and have a look at flatpack permissions to find the correct "Table": look for a line where the "App" is snap.jabref - in the below example, the table is the default desktop-used-apps): flatpak permission-set --data "{'always-ask':<false>}" desktop-used-apps application/pdf snap.jabref okularApplication_pdf 0 3 In this example, the default application to open PDF files is set to okularApplication_pdf, and the counter for when to stop asking how to open PDF files is set to 0/3. If you want JabRef to ask you which application to use every time, use 'always-ask':<true> in the data parameter.
You have several Java Virtual Machines installed, and under the command line the wrong one is chosen. Have a look at the previous question that tells you how to change the virtual machine used. For Ubuntu you may also have a look at the Ubuntu page on Java.
Everything looks too big or too small. How can I change it to to a more reasonable size?
In the background, JabRef uses JavaFX. Applications using JavaFX can be scaled via java -Dglass.gtk.uiScale=1.5 -jar <application>.jar. If you have installed JabRef via a package manager, you probably don't have a .jar file but a binary file. In this case, you need to find your JabRef.cfg in your installation folder (possibly located at /opt/JabRef/lib/app/JabRef.cfg) and add in the section [JavaOptions] the line -Dglass.gtk.uiScale=1.5. Then, restart JabRef. Try finding a value that is suitable for you. On high resolution displays, values around 1.5 seem to be reasonable.
Non-latin characters are not showing up properly
You might need to install an additional font for JabRef to display characters correctly.
System
Language
Font
ArchLinux
Japanese
Submenus from the menu bar close immediately after left click is let go of if the menu bar was clicked in its top half
This issue seems to be related to this JavaFX bug. A temporary workaround is to click the menu bar in its lower half. To fix the issue permanently set the following system property: java -Djdk.gtk.version=2. This can be done globally by adding _JAVA_OPTIONS="-Djdk.gtk.version=2" to /etc/environment. It can also be set locally by editing JabRef.cfg in your installation folder (possibly located at /opt/JabRef/lib/app/JabRef.cfg) and add the line -Djdk.gtk.version=2 in the [JavaOptions] section.
Note: This could not work in JabRef 5.12. or later.
Show Differences — This option shows the differences.
Unified View — In this mode, differences are shown on the right side.
Split View — In this mode, differences are shown on both sides, with deletions on the left side and additions and updates on the right side.
Highlight words — This option compares entries values in terms of words.
Highlight characters — This option compares entries values in terms of characters. It divides both entry values into characters before comparing each character individually. This is perfect for comparing values with small differences (1 or 2 different characters).
From the toolbox's top-left corner, you also can choose to select all the left entry values by clicking Left or selecting all the right entry values by clicking Right. Be aware that selecting all entry values will select a value even when it is empty.
Screenshot of the buttons to choose which entry to keep
You are offered to:
Automatically remove exact duplicates. This button shows up if there are exact duplicates. Click it to stop showing other exact duplicates and have them removed automatically.
Keep left — Keeps the left entry and removes the right entry.
Keep right — Keeps the right entry and removes the left entry.
Keep both— Keeps both entries. This usually means that you don't consider the entries to be duplicates.
Keep merged — Keeps the merged entry only and removes the previous entries.
Cancel — Closes the dialog and stops showing other duplicates.
Screenshot of the duplicate resolver dialog in light mode
Choose Differences Display Mode
Choose Entries Comparison Method
Selecting which entry to keep
the entries.
A left-click on an entry (out of the check box and icons) let you choose it. It displays a preview of the entry below the entry table. As usual, you can choose several entries by using the Shift or the Ctrl keys. Then, pushing the button Delete on the left panel will remove the chosen entries from the table.
A right-click on an entry displays a drop-down menu which allows you to:
delete the entry
add the entry to a group
link a local file to the entry
download the file corresponding to the entry
automatically set file links to the entry
attach an URL to the entry
Potential duplicates are pointed out by an icon in the second column. A click on this icon allows you to check the similarities. A button on the left panel allows you to Deselect all duplicates (without inspection).
On the left panel, if the box Generate keys is checked, keys will be automatically generated on import. You can also choose to generate the keys now by clicking on the button Generate now.
Once you are done with the entry selection, you can add these entries to your database by clicking on OK at the bottom of the window. Alternatively, you can Cancel the import.
A custom user interface controller for listing citations
After connecting to your shared database, your main window should look like this:
Screenshot of JabRef with an open shared database
JabRef will automatically detect your changes and push them to the shared side. JabRef will also constantly check if there is a newer version available. If you experience connection issues, you can pull changes from your shared database via the icon in the icon bar. If a newer version is available, JabRef will try to automatically merge the new version and your local copy. If this fails, the Update refused dialog will show up. You will then have to manually merge using the Update refused dialog. The dialog helps you by pointing out the differences, you then will have to choose if you want to keep your local version or update to the shared version. Confirm your merge by clicking on Merge entries.
Screenshot of Update refused dialog
The Update refused dialog can also take a different form, if the BibEntry you currently work on has been deleted on the shared side. You can choose to keep the BibEntry in the database by clicking Keep or update to the shared side and click Close.
Screenshot of Update refused dialog due to a deleted entry
If you experience a problem with your connection to your shared database, the Connection lost dialog will show up. You can choose to Reconnect, Work offline or Close database. Most of the time simply reconnecting will fix this problem, if that's not the case you will have to choose between Work offline or Close database. Pick Work offline if you want to make sure your changes are saved. If you think there is nothing to save just pick Close database. If you choose to work offline, JabRef will convert the shared database to a local .bib database. Since you are no longer working online, but instead on a local database, you will have to import your work via copy and paste into the shared database. However before you import it into the shared database, make sure to check if changes happened during your offline time. Otherwise you might override someone else's work.
Click on the dedicated button in the taskbar (left of the Generate citation key button)
By default the external editor used to push citations is TeXstudio. You can select another application in Options → Preferences → External programs. Under the Push applications section, click on the Application to push entries to field. This will cause a dropdown menu to appear, from which you are then able to select from a list of all the external editors you have configured.
Preferences: External Programs: Configuration
You can configure the citation command at "Cite command". JabRef intelligently parses the value you gave here. In the example, the congiration \cite{key1,key2} means, that the cite command is \cite, the keys are enclosed by {...} and that multiple keys are separted by a comma (,). With that, you can even support Pandoc's Markdown citation syntax. Configure it with [@key1,@key2].
Once you have made your selection and click Save, the push-to-external application button icon will change to match that of the selected external editor application.
New Application After Select
When you click on the push-to-external application button, JabRef will export your selected entries to an open LaTeX file in the selected external editor application. As an example, here is what happens when you export one entry to TexStudio.
Initial Push to External Export
As long as you continue using the same external editor application, clicking on the push-to-external application button for subsequent exports will just add new citations or extend an existing citation with additional entries. Following the example above, here is what happens when you export a second entry to TeXStudio on an existing citation, which is extended to include the new entry in your LaTeX document.
Subsequent Push to External Export
There are the tools emacsclient and gnuclient. Both support GNU Emacs. Additionally, gnuclient supports XEmacs. As default configuration, JabRef uses emacsclient. JabRef passes -e as parameter, because JabRef adds the emacs command after the given parameters. For a discussion on the use of emacsclient, see a stackoferflow answer. The parameter -n (for --no-wait) is also passed, but that is not necessary.
On Windows, you can install emacs using choco install emacs. Then, start emacs. Afterwards, start the emacs daemon with following command:
You can manually alter the value by typing in the date and time of your choice. Also, by clicking on the calendar icon located at the right end of the field, you can select the date you want in a calendar.
Screenshot of the calendar
The formatting of the time stamp is determined by a string containing designator words that indicate the position of the various parts of the date.
These are some of the available designator letters (examples are given in parentheses for Wednesday 14th of September 2005 at 5.45 PM):
yy: year (05)
yyyy: year (2005)
MM: month (09)
dd: day in month (14)
HH: hour in day (17)
mm: minute in hour (45)
These designators can be combined along with punctuation and whitespace. A couple of examples:
) which is based on Base.css and just overwrites the colors.
Custom Theme: In Preferences > Appearance > Visual theme > Custom theme there can be set a custom theme by simply selecting a custom CSS (based on Base.css or Dark.css), for instance:
#8523: On Windows 10, it is not possible to use fonts that were installed user-wide in the CSS, only system-wide fonts are working. A workaround to use fonts that are not installed system-wide is to include the font file via @font-face.
The way the special fields are stored in the libraries can be set in File → Preferences → Entry Table.
2 modes of storage are available:
With Write values of special fields as separated fields (default configuration since version 5.2), each special field is stored in a separate field of the entry.
With Synchronize with keywords enabled, the values of the special fields are stored twice: in a separated field and as a keyword. Each change in a special field is reflected in the keyword field, and, vice versa, each change in a keyword leads to a change in the special field. Additionally, when loading a database or pasting a new entry, the keywords are used to set the special field values.
In French/En français: (external document, courtesy of INRAE)
Some videos to help you start using JabRef:
by JoshTheEngineer (youtube - English - 22 minutes - January 2021)
by James Azam (youtube - English - 14 minutes - April 2021)
Main Window of JabRef
Upon the first start of JabRef the main user interface is showing up the main elements are:
Menu bar
Icon bar (shortcuts for most frequently used features)
Side bar (for groups and web search)
A "library" is the main file that saves all the information about your collection of references. The storage format of the file is text-based in the BibTeX standard (by default).
To create a new library, just select the "New library" menu item in the "File" menu:
The main screen is now showing an empty "entry table" we will now start to fill with some entries.
To add a new entry select the menu bar entry "Library" -> "New entry", click on the icon in the icon bar, or just hit CTRL-N.
This opens a dialog where you can select the type of reference you want to store. By default all entry types defined by the BibTeX format are available:
For our running example we will select "Article".
After clicking on the "Article" button, the dialog closes and the so called "Entry Editor" is opened for the newly created entry:
The most important information about the references to be added can now be entered in the "Required Fields" tab. "Author", "Title", "Journal", and "Year" should be self-explanatory - however, a "citationkey", might not be familiar to you. Basically, the idea of the "citationkey" is coming from working with BibTeX, where it is necessary to have an unique identifier for each entry. This allows for referencing within a document you might be creating using the stored information in your library. Moreover, also within JabRef this "key" is used for example for cross-references to other related entries or to determine file names for full-text references.
The key usually follows a global pattern and can be easily created automatically by clicking on the "generate" button next to the field.
After entering some information, you can see on the right side of the entry editor a preview of the bibliographic data:
There are further possibilities to add entries to your library which are described in the section "Collect" of this documentation:
After creating the basic information the addition of all other bibliographical details is often cumbersome and error-prone. To ease this task, JabRef allows for an automatic completion of the bibliographic information by looking up the data in public databases. To use this feature just click on the "Update with bibliographic information from the web" button in the editor:
If additional information is found you will be asked in a dialog which information should be taken over:
Usually, you also want to attach a reference to the full-text of a reference. For this, you can use the "file" field in the "General" tab. Here you can either attach a file manually, search for an already existing local file matching the citationkey pattern, or trying to automatically download a matching full text from the web.
To test the automatic download of full texts you can click on the "Get full-text" icon next to the file field, or choose "Lookup" -> "Search full text documents online" from the menu. As soon as a full-text is found, the file will be stored in the local file directory and linked to the entry:
To open the downloaded full text you can click on the "file" icon before the file name - or use the same icon in the entry table:
If you want to search for other references, it is also possible to directly trigger a search in many of the most common bibliographic databases. To start a search just use the "Web Search" feature of JabRef: First select one of the existing data sources, enter a search term and click on "search":
The search results will be shown in an window where you can select all the search hits to be added to your library.
After adding more and more entries, your library might be a bit too unstructured. In order to keep all you references organized JabRef is offering a lot of helpful features like grouping, consistency checks, etc.
You can find more information on this topics in the "Organize" section of the documentation:
If you want to start writing your own papers, articles or thesis, you might find some helpful information on how to use JabRef for citing your collected references from your library:
Journal abbreviations
Since: 5.0
JabRef can automatically toggle journal names between abbreviated and unabbreviated form, as long as the names are contained in one of your journal lists.
This feature can be configured under Options → Preferences → Manage journal abbreviations.
JabRef includes a fairly extensive build-in list of journal abbreviations. This list is a merge of all lists available at https://abbrv.jabref.org. However, this might still be incomplete (or outdated) for the purposes of some users. Thus, JabRef allows to add abbreviations in the form of a personal list or external lists.
General view
Using the feature
Journal name conversion can be accessed either from within the entry editor, or from the Quality menu. In the entry editor you will find a button labeled Toggle abbreviation by the journal field. Clicking this button will cause the current journal name to be switched to the next of four modes:
Full name, e.g. "Aquacultural Engineering"
Default abbreviation, e.g. "Aquacult. Eng."
Medline abbreviation, e.g. "Aquacult Eng"
Shortest unique abbreviation, e.g. "AQEND6"
If the current journal name is not found in your journal lists, the field will not be modified.
To convert the journal names of many entries in bulk, you can select any number of entries, and choose Quality → Abbreviate journal names → DEFAULT, Quality → Abbreviate journal names → MEDLINE, Quality → Abbreviate journal names → SHORTEST UNIQUE, or Quality → Unabbreviate journal names. These three actions will abbreviate and unabbreviate the journal names of all selected entries for which the journal name could be found in your journal lists.
In addition to the build-in journal list, you can have a personal list and external lists.
Any entry in your personal journal list will override an entry with the same full journal name in one of the external lists. Similarly, the external lists are given precedence in the order they are listed.
Your personal journal list is managed on top of the Manage journal abbreviations window. To start building your personal journal abbreviations list, choose Add new list, and enter a filename. If you already have a file that you want to use as a starting point, use the Open existing list button. The table will update to show the contents of the list you have selected.
The table and the tool buttons in the upper right allow you to add, remove and edit journal entries. For each entry you must provide the full journal name, and the default abbreviation (e.g. "Aquacultural Engineering" and "Aquacult. Eng."). The last field, which contains the shortest unique abbreviation, is optional. Therefore, you can actually safely omit it. To edit an entry, double-click its row in the table.
Once you click Save changes, if you have selected a file, and the table contains at least one entry, the table contents will be stored to the selected file, and JabRef's list of journals will be updated.
You can link to a number of external lists. These links can be set up on top of the Manage journal abbreviations window. External lists are similar to the personal list. The Open existing list button allows you to select an existing file on your computer.
External lists can be found at . These data files are in CSV format (using semicolons as separators):
The two last fields are optional, and you can omit them. JabRef supports the third field, which contains the shortest unique abbreviation. The last field is not currently used; its intention is gives frequency (e.g., M for monthly). For instance:
We want to expand both the build-in list and the selection of smaller lists, so if you have set up a representative list for your own subject area, we would appreciate it if you share your list via or by dropping a note on .
Windows
Q: I have issues with my high resolution display. What can I do?
Q: How can I use JabRef as backend for Microsoft Word?
You can directly use the references in Word's internal reference manager. Short explanation: Export your bibliography in XML format and replace the Sources.xml in %APPDATA%\Roaming\Microsoft\Bibliography. Long explanation: check out Export to Microsoft Word. Also, see https://www.youtube.com/watch?v=2PpLZTol9_o for a video explaining how to add and how to cite references in a Word document.
The last option is to use Docear4Word, which is planned to be ported to JabRef (see ).
Use and provided at .
Start regedit and create the following key: HKEY_LOCAL_MACHINE\SOFTWARE\Wow6432Node\JavaSoft\Prefs. []
A: On Windows, one finds the log files in %APPDATA%\..\Local\org.jabref\jabref\Logs\{version}. {version} indicates the currently used JabRef version.
A: According to , you may have to set the font manually by downloading the Base.css from Custom themes - JabRef. Then open the Base.css, and add the following text at the end of Base.css:
Linux
Is there any way to include JabRef in the start menu of Ubuntu?
You might see the error message Error: Could not find or load main class org.jabref.JabRefMain. This means, you do not have JavaFX support activated in your Java runtime environment. This typically happens if you use OpenJDK, where one needs to setup OpenJFX separately.
You have several Java Virtual Machines installed, and under the command line the wrong one is chosen. Have a look at the previous question that tells you how to change the virtual machine used.
For Ubuntu you may also have a look at the .
In the background, JabRef uses . Applications using JavaFX can be scaled via java -Dglass.gtk.uiScale=1.5 -jar <application>.jar. If you have installed JabRef via a package manager, you probably don't have a .jar file but a binary file. In this case, you need to find your JabRef.cfg in your installation folder (possibly located at /opt/JabRef/lib/app/JabRef.cfg) and add in the section [JavaOptions] the line -Dglass.gtk.uiScale=1.5. Then, restart JabRef. Try finding a value that is suitable for you. On high resolution displays, values around 1.5 seem to be reasonable.
A: On Linux, the path to the log files is ~/.local/share/jabref/logs/$version/
Custom import filters
JabRef allows you to define and use your own importers, in very much the same way as the standard import filters are defined. An import filter is defined by one or more Java classes, which parse the contents of a file from an input stream and create BibTex entries. So with some basic Java programming, you can add an importer for your favorite source of references or register a new, improved version of an existing importer. Also, this allows you to add compiled custom importers that you might have obtained e.g. from GitHub without rebuilding JabRef (see "Sharing your work" below).
Custom importers take precedence over standard importers. This way, you can override existing importers for the Autodetect and Command Line features of JabRef. Custom importers are ordered by name.
Make sure, you have a compiled custom import filter (one or more .class files as described below) and the class files are in a directory structure according to their package structure. To add a new custom import filter, open the dialog box Options → Manage custom imports, and click Add from folder. A file chooser will appear, allowing you to select the classpath of your importer, i.e. the directory where the top folder of the package structure of your importer resides. In a second file chooser, you select your importer class file, which must be derived from ImportFormat
Strings
BibTeX supports storing constant strings using @String {key = value}. JabRef supports managing them using Library → Edit string constants, which opens the . These values can be used in fields. For example, you can have:
and then in some entry for example
or
In the JabRef field editor, the author has to be inserted as #kopp# #et# #kubovy# or #kopp# and #kubovy#.
Strings are rendered specially in the entry editor. This is especially important in the case of months. For instance, take the following BibTeX entry:
Automatic Backup (.sav and .bak) and Autosave
JabRef generates .sav, .bak and .tmp files while working.
.bak stands for the automatic backup feature: Each 20 seconds, after a change to the library, the current state of the library is saved to a .bak file. JabRef keeps 10 older versions of a .bak file in the .
How to Improve the Help Page
Here is a quick start guide on how to improve help pages in the .
The Jabref help pages are hosted at with integration to GitHub, which provides version control based on . In order to edit or create a JabRef help page, you need a GitHub account. You can sign up for free. If you already have an account, please make sure that you are signed in.
The easiest way to fix small errors, or to add additional information, is to edit a help page directly in your browser, using the following steps.
At the top of each help page, you can find the GitHub icon with "Edit on GitHub" link. Just click the link to show the source of the page.
This leads you to the GitHub page associated with the help page:
I am on Debian/Ubuntu and clicking on the JabRef icon works, but I cannot start JabRef from the command line. What is wrong?
Everything looks too big or too small. How can I change it to to a more reasonable size?
, your new importer will appear in the list of custom import filters. All custom importers will appear in the
File → Import → Custom Importers
and
File → Import and Append → Custom Importers
submenus of the JabRef window.
Please note that if you move the class to another directory you will have to remove and re-add the importer. If you add a custom importer under a name that already exists, the existing importer will be replaced. Although in some cases it is possible to update an existing custom importer without restarting JabRef (when the importer is not on the classpath), we recommend restarting JabRef after updating a custom-importer. You can also register importers contained in a ZIP- or JAR-file, simply select the Zip- or Jar-archive, then the entry (class-file) that represents the new importer.
For examples and some helpful files on how to build your own importer, please check our download page.
Let us assume that we want to import files of the following form:
In your favorite IDE or text editor create a class derived from ImportFormat that implements methods getFormatName(), isRecognizedFormat and importEntries(). Here is an example:
Note that the example is in the default package. Suppose you have saved it under /mypath/SimpleCSVImporter.java. Also, suppose the JabRef-2.0.jar is in the same folder as SimpleCSVImporter.java and Java is on your command path. Compile it using a JSDK 1.4 e.g. with
Now there should be a file /mypath/SimpleCSVImporter.class.
In JabRef, open Options → Manage custom imports and click Add from folder. Navigate to /mypath and click the Select ... button. Select the SimpleCSVImporter.class and click the Select ... button. Your importer should now appear in the list of custom importers under the name "Simple CSV Importer" and, after you click Close also in the File → Import → Custom Importers and File → Import and Append → Custom Importers submenus of the JabRef window.
With custom importer files, it's fairly simple to share custom import formats between users. If you write an import filter for a format not supported by JabRef, or an improvement over an existing one, we encourage you to post your work on our GitHub page. We'd be happy to distribute a collection of submitted import files or to add to the selection of standard importers.
In JabRef, the entry editor then displays #may#. In case the entry editor just displays may, this is written as follows:
In other words: The character # indicates something special in the entry editor.
JabRef enhances the concept of Strings to add a type to those @Strings. The issue is how to preserve such type of a string in a BibTeX file. JabRef adds the type though prefixes:
@String { aKopp = "Kopp, Oliver" } is a @String with the type author.
@String { iMIT = "{Massachusetts Institute of Technology ({MIT})}" } is a @String with the type of institution.
@String { anct = "Anecdote" } is a @String of type other.
@String { lTOSCA = "Topology and Orchestration Specification for Cloud Applications" } is a @String of type other.
Then @Strings of type author should be used for author and editors fields only. @Strings of type institution should be used for institution and organization fields only. @Strings of type publisher should be used only for publisher fields. And finally @Strings of type other can be used anywhere.
It can also happen that you will have the same institution for more types:
@String { aMIT = "{Massachusetts Institute of Technology ({MIT})}" } if the institution will appear as author or editor
@String { iMIT = "{Massachusetts Institute of Technology ({MIT})}" } if the institution will appear as institution or organization
@String { pMIT = "{Massachusetts Institute of Technology ({MIT}) press}" } if the institution will appear as publisher.
Even if the last example may appear contradicting the intention was to remove duplicity and unify the names of persons and institutions.
1936;John Maynard Keynes;The General Theory of Employment, Interest and Money
2003;Boldrin & Levine;Case Against Intellectual Monopoly
2004;ROBERT HUNT AND JAMES BESSEN;The Software Patent Experiment
import java.io.BufferedReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import net.sf.jabref.logic.importer.Importer;
import net.sf.jabref.logic.importer.ParserResult;
import net.sf.jabref.logic.util.FileExtensions;
import net.sf.jabref.model.entry.BibEntry;
import net.sf.jabref.model.entry.BibtexEntryTypes;
public class SimpleCSVImporter extends Importer {
@Override
public String getName() {
return "Simple CSV Importer";
}
@Override
public FileExtensions getExtensions() {
return FileExtensions.TXT;
}
@Override
public String getDescription() {
return "Imports CSV files, where every field is separated by a semicolon.";
}
@Override
public boolean isRecognizedFormat(BufferedReader reader) {
return true; // this is discouraged except for demonstration purposes
}
@Override
public ParserResult importDatabase(BufferedReader input) throws IOException {
List<BibEntry> bibitems = new ArrayList<>();
String line = input.readLine();
while (line != null) {
if (!line.trim().isEmpty()) {
String[] fields = line.split(";");
BibEntry be = new BibEntry();
be.setType(BibtexEntryTypes.TECHREPORT);
be.setField("year", fields[0]);
be.setField("author", fields[1]);
be.setField("title", fields[2]);
bibitems.add(be);
line = input.readLine();
}
}
return new ParserResult(bibitems);
}
}
The usage of a text-based file format has some advantages:
The file is "human readable" and editable with every text editor
the text format allows for an easy tracking of changes with every common version control protocol (e.g., git)
and finally: the format is dedicated for the usage with LaTeX; so you do not need to convert it to any other format but you can just directly link to your JabRef library
Adding of a new entry manually
The default key pattern is [auth][year], which means that Author information is followed by the year of the publication, resulting in the example in Turing1950. However, the key pattern is customizable to your needs. See Configuration > "Customize the citation key generator" for more details.
Enhancing the information
The found information is most accurate if an identifier like a "DOI" or "ISBN" is maintained. If you already know such an unique identifier, this can also be already the starting point to create a new entry without manual entering any information by using the "create from ID" feature in the Create entry dialog. For more information see: Collect > "Add entry using an ID"
Adding a full text document
In order to use the automated feature, it is necessary to set-up a file directory first. To do so, please go to "Options" > "Preferences", go to "Linked files" section, and select there an existing folder as the "Main file directory":
.sav preserves the last state of the library after saving. Thus, one can go back one save command in the history. Used when writing the .bib file. Used for copying the .bib away before overwriting on save.
.tmp is a temporary file with changes that are supposed to be written to the .bib file.
Rough outline of what's happening during a write to the .bib file:
A .tmp will be written --> .bib copies to .sav --> .tmp copies to .bib --> .sav gets deleted --> 20 seconds later, a copy of the .bib file will be stored as.bak file in the user data dir.
This functionality runs in the background while you are working on a bibliographic database. It makes a backup copy (the .bak file) and keeps that up-to-date on every user interaction. For instance, when you change a field the new value would get saved into the backup copy. Assuming that JabRef crashes while you are working on a BibTeX database. When you try again to open the file JabRef crashed with you will get the following dialog:
Screenshot of the backup found dialog
Now you have the possibility to restore and review your changes which would normally get lost.
Windows:
Windows 7/10:
C:\Users\<Account>\AppData\org.jabref\jabref
Alternatively, open the run dialogue by pressing Windows+R, then enter %APPDATA%\..\Local\org.jabref\jabref
Windows XP:
C:\Documents and Settings\<Account>\Application Data\Local Settings\org.jabref\jabref>
Mac OS X:/Users/username/Library/Application Support/org.jabref/jabref
JabRef offers automatic saving of the library. No need to click on File --> Save or pressing Ctrl+S anymore: The opened database are saved automatically without manual intervention.
In case the .bib file should automatically be saved on each change, you can direct JabRef to do so. This feature needs to be activated in the preferences:
Screenshot of the autosave preferences
Changelog:
JabRef 5.8
Major rework and a change in what .bak and .sav denote. Henceforth,
.sav is a temporarily written file.
.bak is a backup file.
JabRef 5.1
To reduce the amount of configuration options, the possibility to disable the creation of .bak files was removed.
JabRef 3.7
First introduction of the autosave and backup features.
.sav is the automatic backup feature.
.bak preserves the last state of the library after saving
To actually edit the page, click on the pencil icon, as highlighted above.
The window to edit the page at GitHub looks like this:
Edit view at GitHub
Most text can be simply added/edited in this field as plain text. However, you can style your contribution by using markdown. Markdown is a rather easy way to format text without the need for complex markup, such as with HTML. You can find an introduction to markdown here or here.
In order to review your changes, click on the "Preview changes" tab:
Edit view at GitHub
To save the changes, create a so-called "Commit" by scrolling down and pressing the "Propose File Change" button:
Save changes
Please note: The message you provide here will be visible in the history of the help page, so please consider your change and provide a meaningful description of your changes.
As the last step, submit the changes you have made back to the JabRef team:
Create Pull Request
Just press the "Create Pull Request" button, and confirm the creation of the request on the next page.
That's it! The JabRef team will review your changes and publish them on docs.jabref.org.
To edit more than one file at a time, add screenshots, and for other more advanced changes, we recommend that you checkout this repository locally and create a Pull Request of your changes using the standard git and GitHub workflow.
The best way to enter tables is to use this Table Generator for Markdown. It has the nice feature to generate markdown tables from different sources, e.g. you can directly copy the table from a spreadsheet or upload a csv file. Just copy and paste the generated markdown into the documentation.
The simplest way to create a new entry based on a single PDF file is to drag & drop the file onto the table of entries (between two existing entries). JabRef will then analyze the PDF and create a new entry.
This feature is available through Lookup -> Search for unlinked local files.
Preparation: Adjust the JabRef key generation pattern to fit your needs
JabRef offers a BibTeX key generation and offers different patterns described at BibtexKeyPatterns.
Link the PDFs to your bib library
In case you have numerous PDF files and want to convert them into new entries, JabRef can search automatically for the PDF files, let you select the relevant ones, and convert them into new entries.
Create or open a .bib library.
Go to Lookup -> Search for unlinked local files. (or press SHIFT + F7)
The "Search for unlinked local files" dialog opens.
Choose a start directory using the "Browse" button.
Click on "Search" / "Scan directory".
In "Select files", the files not yet contained in the library are shown.
Select the entries you are interested in. Note: the button Export selected files allows you to export the list of the selected files (a text file containing on each line one filename with its path)
Click on Import.
The windows close and the entry table now contains the newly-imported entries.
The entry editor with the last imported entry is shown
You can now save the file and are finished.
Optional: Click on "General" to see the linked file
Optional: Click on "BibTeX source" to see the BibTeX source
Optional: You have to shrink it to see the entry in the entry table, enlarge the JabRef window and use the mouse at the upper border of the entry editor
Optional: Press Esc to show the entry preview
The importer based on the content has been written for IEEE and formatted papers. Other formats are not (yet) supported. In case a DOI is found on the first page, the DOI is used to generate the BibTeX information.
The next development step is to extract the title of the PDF, use the "Lookup DOI" and then the functionality from JabRef to fetch the BibTeX data.
We are also replacing the code completely by using another library. This is much effort and there is no timeline for that.
JabRef also offers to change the filenames. You can adapt the pattern at Preferences -> Import
Select "Choose pattern" and choose "bibtexkey - title" This results in the setting \bibtexkey\begin{title} - \format[RemoveBrackets]{\title}\end{title}.
This makes the filenames start with the bibtey key followed by the full title. In the concrete case, \bibtexkey only may be the better option as the described bibtey key already contains the title.
JabRef used to have support for , which returned back a full BibTeX entry or a PDF. Due to unclear copyright situation of a used library, this service was removed. Further, Mr.DLib changes its focus and will provide literature recommendations. See .
Manage associated files
JabRef lets you link up your entries with files of any type stored on your system. Thereby, it uses the field file, which contains a list of linked files. Each entry can have an arbitrary number of file links, and each linked file can be opened quickly from JabRef. The fields url and doi are used as links to documents on the web in the form of a URL or a DOI identifier, respectively (see URL and DOI in JabRef).
In BibTeX/biblatex terms, the file links are stored as text in the field file. From within JabRef, however, they appear as an editable list of links accessed from the entry editor along with other fields.
Adding external links to an entry
If the "file" field is included in General fields, you can edit the list of external links for an entry in the Entry editor. The editor includes buttons for inserting, editing and removing links, as well as buttons for reordering the list of links.
JabRef offers the following directory settings:
File → Preferences → Linked files, item Main file directory.
Library → Library properties, items General file directory, and User-specific file directory.
One of these settings is required. Mostly the "Main file directory" is enough.
JabRef uses these 3 directories to search for the files: JabRef starts in the user-specific file directory, then the general file directory, and, finally, the main file directory
JabRef enables setting a directory per database. When sharing a library across multiple persons, each user might have a different directory. Either, each user can set his directory in the "Main file directory". In case the group also shares papers and thus there are two directories (the private one and a group-shared one), one can set a directory within the library (the "General file directory"). In case a user has a different location of the shared folder (e.g., different paths on Linux and Windows), he can use the "User-specific file directory". This setting is persisted in the bib file in a way that it does not overwrite the setting of another user. For this, JabRef uses the username of the currently logged-in user (-<loginname> is used as a suffix in the jabref-meta field). So, both mary and aileen can set a different user-specific file directory.
If JabRef saves an attached file and my login name matches the name stored in the bib file, it chooses that directory. If no match is found, it uses the "General file directory" of the bib file. If that is not found, it uses the one configured at File → Preferences → Linked files.
In some settings, the bib file is stored in the same directory as the PDF files. Then, one ignores all the above directories and enable "Search and store files relative to library file location". In this case, JabRef starts searching for PDF files in the directory of the bib file. It is also possible to achieve this result by setting . as "General file directory" in the library properties.
.
Relative file directories obviously only work in the library properties for a bib file, e.g. a.bib Library → Library properties → General file directory → papers. Assume to have two bib files: a.bib and b.bib located in different directories: a.bib located at C:\a.bib and b.bib located at X:\b.bib. When I click on the + icon in the general Tab of file a.bib, the popup is opened in the directory C:\papers
If you have a file within or below one of your file directories with an extension matching one of the defined external file types, and a name starting with (or matching) an entry's citation key, the file can be auto-linked. JabRef will detect the file and display a "link-add" icon in the entry editor, at the left of the filename. Click on the "link-add" icon to link this file to the entry.
The rules for which file names can be auto-linked to a citation key can be set up in File → Preferences → Linked files, section Autolink files.
Files can be automatically renamed and organized in folders according to custom patterns. The pattern syntax follows the same as for the . JabRef can rename files according to this pattern, either automatically or as part of a cleanup operation.
With file directory pattern, JabRef can automatically create subfolders and move the files into the directory based on the defined pattern. As an example, you have a single folder, e.g. papers for all your PDFs linked to their corresponding entry in JabRef. Now you want to arrange them according to defined groups. Let's say you have two groups, Automation and Biology, with a couple of entries.
Now set the file directory pattern to: [groups:(unknown)]
If you now execute the cleanup action "Move files", JabRef will automatically move the files of the corresponding in the file directory to the subfolders papers/Automation and papers/Biology respectively.
Explanation: The expression in the brackets says: Create a subdirectory based on the field “groups” of the entry. If the field groups is not set or empty, use “unknown” as a fallback name for the directory. If you have one entry assigned to multiple groups, the directory will have the name “groupA, groupB”.
For an entry, if you want to download a file and link it to the entry, you can do this by clicking the Download button in the entry editor.
A dialog box will appear, prompting you to enter the URL. The file will be downloaded to your main file directory, named based on the entry's citation key, and finally linked from the entry.
It is possible to have greater flexibility in the naming scheme by using regular expressions for the search. In most cases, it should not be necessary though to adapt the given default.
If you open the preferences (File → Preferences → Linked Files), you will find in the section Autolink files an option called "Use regular expression search". Checking this option will allow you to enter your own regular expression for search in the PDF directories.
The following syntax is understood:
* - Search in all immediate subdirectories, excluding the current and any deeper subdirectories.
** - Search in all subdirectories recursively AND the current directory.
.
The default for searches is **/.*[citationkey].*\\.[extension]. As you can see, this will search in all subdirectories of the extension-based directory (for instance in the PDF directory) for any file that has the correct extension and contains the citation key somewhere.
There are several ways to open an external file or web page. In the entry table, you can click on the PDF icon to open the PDF. In case there are multiple PDFs linked, always the first one is opened. You can also right-click on the line of the entry in the entry table and select "Open file". There is also a keyboard shortcut for this: In the default setting, this is F4, but .
To access any of an entry's links, click on the icon with the right mouse button (or Ctrl + Click on Mac OS X) to bring up a menu showing all links.
In general, there is no need to change the settings of external file types. So, this setting is for advanced users. See .
Library properties
Each library can have specific properties that can be modified through Library→ Library properties. These specific properties override the generic properties defined in Options → Preferences.
The library-specific properties are stored in the database itself. This way, when moving the database to another computer, these properties are preserved. In most of cases, these are stored in the bib-file database using text blocks starting with @Comment{jabref-meta:.
For shared SQL databases, some properties are not available as they are not handled like a .bib file.
The following properties are not available:
Database encoding (always UTF-8)
The library properties window consists of four tabs:
General
Saving
String constants
Citation key patterns
This setting determines which character encoding JabRef will use when writing this library to disk. Changing this setting will override the setting made in Preferences dialog for this database. JabRef specifies the encoding near the top of the bib file, in order to be able to use the correct encoding next time you open the file. The drop-down menu allows to select one encoding.
You can select if your library follows the .
In your library, files (PDF, etc.) can be linked to an entry. The list of these files are stored in the file field of the entry. The location of these files has to be specified.
For your library, you can define a General file directory and a User-specific file directory. These settings override the main file directory defined in the Preferences dialog.
The General file directory is a common path for all the users of a shared database.
The User-specific file directory allows each user to have its own file directory for the database. If defined, it overrides the General file directory.
JabRef stores the name of the current system alongside the User-specific file directory. This assumes that each user of the library has a different system name. For example, when using the computer laptop, the entry in the bib file is @Comment{jabref-meta: fileDirectory-jabref-laptop:\somedir;}
Relative directories can be specified. This means that the location of the files will be interpreted relative to the location of the bib file. Simply setting a directory to "." (without quotes) means that the files should reside in the same directory as the bib file.
The preamble defines some LaTeX commands that will be included in the bibliography once processed by BibTeX.
While you edit a shared library, another user may be editing it too. By default, saving the library will overwrite changes done by others (although a warning message about the changes will be displayed).
To avoid discarding changes involuntarily, and hence to allow a smooth collaborative work, you can choose to refuse to save the library before external changes have been reviewed. This setting lets you enforce reviewing of external changes before the library can be saved: users will only be able to save the library after any external changes have been reviewed and either merged or rejected.
When saving the library, the order of the entries will be preserved if Save entries in their original order is selected. Alternatively, by selecting Save entries ordered as specified, you can choose to sort the entries using three criteria. For each criterion, you can type-in the field to be used and select the order.
Field formatting can be tidied up when saving the library. That ensures your entries to have consistent formatting. If you check Enable save actions, the list of actions can be configured.
For more information see .
The of the library.
The to be used with this library.
How to translate the JabRef User Interface
Introduction
JabRef comes with a set of translations into 20 different languages: Chinese (simplified), Danish, Dutch, English, Farsi, French, German, Greek, Indonesian, Italian, Japanese, Norwegian, Persian, Portuguese, Portuguese (Brazil), Russian, Spanish, Swedish, Tagalog, Turkish and Vietnamese.
If the JabRef interface already exists in your language, you can help improve it. Otherwise, you can start translating JabRef into your own language.
Improving an existing translation
We use the service of Crowdin to keep our translations updated. It is a service directly running in the browser and one can quickly join and start translating.
Select your preferred language, login, and click on JabRef_en.properties
Choose the string you want to translate in the left panel (strings to be translated are listed first)
and enter the translation in the central panel (suggestions are given at the bottom)
Crowdin offers to quickly add a new language. Please contact us so that we add a new language for you.
You may decide to wait for .
To test directly your translation, you must be able to compile the source tree after making your additions. This requires you to install the . Ensure that you use the most recent version.
Crowdin allows for downloading the current translation file:
Place the downloaded file in the path src/main/resources/l10n. Then, execute gradlew run in the root directory and JabRef should start.
For a new language to be available within JabRef, a corresponding line must be added in the Java class GUIGlobals (found in the directory /src/main/java/org/jabref/logic/l10n/Languages.java in the JabRef source code tree). The line is inserted in the static {} section where the map LANGUAGES is populated. The code must of course be recompiled after this modification.
For each language, there is the file JabRef_xx.properties (xx denotes the country code for the language). It contains all translations in a key/value format. In the JabRef source code tree, the property files reside in the directory.
Each entry is first given in English, then in the other language, with the two parts separated by an '=' character. For instance, a line can look like this in a German translation file:
Note that each space character is escaped (\) to make it a valid property key. The translation value does not need any escapes.
Some entries contain "variables" that are inserted at runtime by JabRef - this can for instance be a file name or a file type name:
A variable is denoted by %0, %1, %2 etc. In such entries, simply repeat the same notation in the translated version.
As we can see, there are several "special" characters: the percent sign and the equals sign, along with the colon character. If these characters are to be part of the actual text in an entry, they must be escaped in the English version, as with the colon in the following example:
The character encoding should be UTF-8. Please avoid Unicode escaping such as \u2302.
Debugging your library file
When error ensues, how to debug your library file with various methods.
Sometimes, it helps to .
If you encounter any errors that are related to wrong, erroneous, corrupt or vanished data in your library file or simply unintended behavior that has unknown causes, the first thing that is advised to do, is to find and make use of your backups.
Navigate to your.
XMP metadata support in JabRef
Bib(la)TeX information into the PDF metadata
XMP is a standard created by Adobe Systems for storing metadata (data about data) in files. A well known example for metadata are MP3 tags, which can be used to describe artist, album and song name of a MP3 file. Adding metadata to MP3 helps other people to identify the songs correctly independent of file-name and can provide means for software (MP3 players for instance) to sort and group songs.
With XMP support the JabRef team tries to bring the advantages of metadata to the world of reference managers. You can now choose to "Write XMP metadata to PDFs" in the Tools menu of JabRef, which will put all the Bib(la)TeX information into the PDFs. If you then email a PDF to a colleague, they can just drag the file into JabRef and all information that you entered will be available to them.
To use the XMP-feature in JabRef you can do the following:
To import a single annotated PDF-file
Entry Editor
The entry editor opens from (table of entries). To open it for a specific entry, you can either:
double-click on the entry in the table of entries
select the entry and press Enter
that contains XMP
, select
File → Import into...
and then choose the filter "XMP-annotated PDF", or drag the file into the main view.
To annotate all the PDFs in a given database, select Tools → Write XMP metadata to PDFs.
To verify if it worked, you can open the PDF in Adobe Acrobat and select File → Document Properties → Additional Metadata → Advanced. In the tree to the right you should see an entry called "http://purl.org/net/bibteXMP". Note: this works only with Adobe Acrobat, not with Adobe Reader. If you do not have Adobe Acrobat, you can use pdfinfo instead in order to see the XMP metadata. pdfinfo is part of Xpdf tools and Poppler.
JabRef builds on Dublin Core to encode bibliographic information. That information us embedded in the PDF using the XMP format. Dublin Core itself i) builds on RDF and ii) can be extended with own information. In case BibTeX data cannot be stored using native Dublin Core fields, new fields are used. Basically, all fields and values are turned into nodes of an XML document. Only authors and editors are stored as rdf:Seq-structures, so users of the data can skip the splitting on ands. All strings and crossrefs will be resolved in the data.
The following easy minimal schema is used:
The citation key is stored as citationkey.
The type of the BibTeX entry is stored as entrytype.
author and editor are encoding as rdf:Seqs where the individual authors are represented as rdf:lis.
All other fields are saved using their field-name as is.
The following is an example of the mapping
will be transformed into
Be aware of the following caveats if you are trying to parse BibTeXMP:
In RDF attribute-value pairs can also be expressed as nodes and vice versa.
@INPROCEEDINGS{CroAnnHow05,
author = {Crowston, K. and Annabi, H. and Howison, J. and Masango, C.},
title = {Effective work practices for floss development: A model and propositions},
booktitle = {Hawaii International Conference On System Sciences (HICSS)},
year = {2005},
owner = {oezbek},
timestamp = {2006.05.29},
url = {http://james.howison.name/publications}
}
<?xpacket begin="" id="W5M0MpCehiHzreSzNTczkc9d"?><x:xmpmeta xmlns:x="adobe:ns:meta/">
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Description xmlns:dc="http://purl.org/dc/elements/1.1/" rdf:about="">
<dc:creator>
<rdf:Seq>
<rdf:li>K. Crowston</rdf:li>
<rdf:li>H. Annabi</rdf:li>
<rdf:li>J. Howison</rdf:li>
<rdf:li>C. Masango</rdf:li>
</rdf:Seq>
</dc:creator>
<dc:relation>
<rdf:Bag>
<rdf:li>bibtex/booktitle/Hawaii International Conference On System Sciences (HICSS)</rdf:li>
<rdf:li>bibtex/citationkey/CroAnnHow05</rdf:li>
<rdf:li>bibtex/file/:CroAnnHow05.pdf:PDF</rdf:li>
<rdf:li>bibtex/owner/fdarboux</rdf:li>
<rdf:li>bibtex/timestamp/2020-11-22</rdf:li>
<rdf:li>bibtex/url/http://james.howison.name/publications</rdf:li>
</rdf:Bag>
</dc:relation>
<dc:title>
<rdf:Alt>
<rdf:li xml:lang="x-default">Effective work practices for floss development: A model and propositions</rdf:li>
</rdf:Alt>
</dc:title>
<dc:date>
<rdf:Seq>
<rdf:li>2005</rdf:li>
</rdf:Seq>
</dc:date>
<dc:format>application/pdf</dc:format>
<dc:type>
<rdf:Bag>
<rdf:li>InProceedings</rdf:li>
</rdf:Bag>
</dc:type>
</rdf:Description>
</rdf:RDF>
</x:xmpmeta><?xpacket end="w"?>
The imported entries may need some editing because all the information gathered from the PDF files may not be accurate (see below "PDFs for which it works").
[title] - All expressions in square brackets are replaced by their corresponding citation key pattern.
[extension] - Is replaced by the file-extension of the field you are using.
All other text is interpreted as a regular expression. But caution: You need to escape backslashes by putting two backslashes after each other to not confuse them with the path-separator.
The legacy PDF/PS links (i.e. the pdf and ps fields, which were used in JabRef versions prior to 2.3), should in current versions be replaced by general file links. This can be done using Quality → Cleanup entries... and enabling Upgrade external PDF/PS links to use the 'file' field.
Preamble
Tab "Saving"
Library protection
This is not a security feature, merely a way to prevent users from overwriting other users' changes inadvertently. This feature does not protect your library against malicious users.
Save sort order
Entries containing a crossref field will always be placed prior to the other entries. This is a necessary preliminary for BibTeX to be able to determine the correct referenced values. (See: Tame the BeaST, p. 26)
Copy the backup files to a safe, but different location. (Basically, create a backup of the backups. This step is very important, as each 20 seconds, after a change to the library, the current state of the library is saved to a .bak file, but JabRef at most stores 10 backup files and if you continue to work with your original library file (.bib), eventually JabRef will overwrite your old backup files)
Compare the backup file with the erroneous library. You can do this by editing your chosen backup file (via JabRef or file editor) in such a way that the modification date is newer than that of your erroneous library. Open the erroneous library and the backup merge dialogue should trigger, which allows you to see what has changed in the file. Alternatively, to achieve the same result, it is possible to use third party file versioning systems like Git or visual difference and merge tools like Meld or WinMerge.
If this method works: Great!
If this method does not work with the first backup file: Try an older backup file
If this method does not work with any backup file: Try the method of half splitting.
The method of half splitting (also referred to as halving) can be used to find certain faults in your library file, which are caused by erroneous syntax, file conversions or incompatible encodings/charsets. These faults may make it impossible for JabRef to correctly parse, read or import the library file.
An easy way to look at the method of halving is to repeatedly ask yourself the following question, after having deleted a part of your library file: "Is the error in the first part or the last part of the entries?"
Create a backup of your library file.
Open your library with the text-editor of your choice (For example, Notepad++).
If your library now miraculously does not trigger the error, don't stop and leave. Instead, rinse and repeat and use the technique of halving on the junk of entries that you just deleted (hence the need for backups!). Use the technique of halving on THAT part of the library.
Repeat deleting entries until you can isolate the specific entry or entries that trigger errors.
Remove these entries with the error.
Add all the other entries back.
Open JabRef.
Be happy :-)\
Half splitting a library with two entries:
Halving as a process of elimination will quickly lead to results, as the following table illustrates:
Number of entries
2
3
4
5
6
7
8
9
10
17
33
65
129
257
...
If you want to find out more about this method, the following articles explain the method of halving in various contexts:
select the entry and go to the menu View → Open entry editor
select the entry and press CTRL + E
Then you can modify the content of the entry (see below). When done, click on the top left-hand corner of the entry editor or press ESC to close the entry editor and go back to the table of entries.
In this panel you can specify all relevant information on a single entry. The entry editor checks the type of your entry, and lists all the fields that are required, and the ones that are optional, for referring the entry with BibTeX. In addition, there are several fields termed General fields, that are common to all entry types.
You can fully customize which fields should be regarded as required and optional for each type of entry, and which fields appear in the General fields tabs. See Customizing entry types for more information about this.
For information about how the fields should be filled out, see BibTeX help.
The entry editor contains six panels: Required fields, Optional fields, General, Abstract, Comments and Bib(la)TeX source, where General, Abstract and Comments can be customized (see Customizing general fields for details). Inside the three first panels, Tab and Shift + Tab are used to switch focus between the text fields.
Up to JabRef 4.1, the field was called "Review". The field name was changed to "Comments" as "Review" indicated some external reviews or some fundamental comments.
Switch panels by clicking on the tabs, or navigate to the panel to the left or right using the following key combinations: Ctrl + Tab or Ctrl + + switch to the tab to the right, and Ctrl + Shift + Tab or Ctrl + - switch to the tab to the left. You can also switch to the next or previous entry by pressing Ctrl + Shift + Down or Ctrl + Shift + Up, respectively, or by clicking the appropriate toolbar button.
BibTeX source (termed biblatexsource in case of a biblatex library) shows how th entry will appear when the database is saved in BibTeX (or biblatex) format. If you wish, you can edit the source directly in this panel. When you move to a different panel, press Ctrl + S or close the entry editor, JabRef will try to parse the contents of the source panel. If there are problems, you will be notified, and given the option to edit your entry further, or to revert to the former contents.
Tip: If your database contains fields unknown to JabRef, these will be visible in the source panel.
Tip: the pdf and url fields support Drag and Drop operations. You can drop there an url from your browser. either a link to a pdf file (that JabRef can download for you) or you can keep the link.
When the contents of a field is changed, JabRef checks if the new contents are acceptable. For field types that are used by BibTeX, the contents are checked with respect to the use of the '#' character. The hash symbol is only to be used in pairs (except in escaped form, '\#'), wrapping the name of a BibTeX string that is referenced. Note that JabRef does not check if the referenced string actually exists (this is not trivial, since the BibTeX style you use can define an arbitrary set of strings unknown to JabRef).
If the contents are not accepted, the field will turn red, indicating an error. In this case the change will not be stored.
BibTeX supports string constants. One can define in the bibliography. JabRef offers editing of these strings via the String Editor.
For instance, if you see #jan# in the month field, the "real" BibTeX entry looks like month = jan. For more details, see Strings.
The entry editor offers autocompletion of words. In the File → Preferences → Autocomplete, you can enable or disable autocompletion, and choose for which fields autocompletion is active.
With autocompletion, JabRef records all words that appear in each of the chosen fields throughout your database. Whenever you write the beginning of one of these words, it will be suggested visually. To ignore the suggestion, simply write on. To accept the suggestion, either press Enter or use your arrow keys or other keys to remove the selection box around the suggested characters.
Note: the words considered for suggestion are only the ones appearing in the same field in entries of the same database as the one you are editing. There are many ways to realise this kind of feature, and if you feel it should have been implemented differently, we'd like to hear your suggestions!
The entry editor allows for file(s) to be dragged and dropped directly into the entry editor window. JabRef follows the default behavior of your operating system and uses Modifier keys to distinguish the drag and drop options. Copy means the entry editor will create a copy of the file in the current directory. The keyboard shortcuts needed to move, copy or link files are the following: Move means, the entry will move the file to the defined file directory, and rename the file according to the filename and file directory patterns. Link means the entry editor will create a link to the file. This creates a shortcut to the file and will not copy the file to the current directory.
Move: Ctrl + Drag (Windows) or Option + Drag (MacOS/Linux)
Copy: Shift + Drag (Windows) or Command + Drag (MacOS/Linux) or no key + Drag
Link: Alt + Drag (Windows) or Command + Option + Drag (MacOS/Linux)
Pressing Ctrl + K or the 'key' button causes the citation key for your entry including the surrounding to be copied to the clipboard.
Pressing Ctrl + Shift + K causes the citation key for your entry to be copied to the clipboard.
Press Ctrl + G or the 'gen key' button (the magic wand) to autogenerate a citation key for your entry based on the contents of its required fields.
By selecting this Tab, we are sending the title of the selected paper to Mr. DLib.
Mr. DLib is a service that calculates recommendations for you based on this title. After a short loading time the recommendations are listed in the Related Articles Tab. For detailed information see Mr. DLibs help page. The following image shows the Related Articles Tab with recommendations to the selected item.
JabRef can display the content of annotations in PDFs linked to an entry.
Mark or annotate something in a linked PDF.
In the entry editor, you can now select the tab "File annotations" and you will see the content you have highlighted or commented on in the PDF.
If you have multiple PDFs linked to the entry, you can select the document as well in the File Annotation tab.
Create an entry based on an ID such as DOI or ISBN.
From an ID to an entry
For other identifiers, choose Library → New entry, or click on the New entry button, or use the keyboard shortcut CTRL + N. In the lower part of the window, there are two boxes : "ID type" and "ID". In the field "ID type", you can select the desired identifier, e.g. "ISBN" (it works also for DOI). Then enter the identifier in the textbox below and press Enter. That will generate an entry based on the given ID (you can also click on "Generate"). The entry is added to your library and opened in the entry editor. In case an error occurs, a popup is shown.
Window for selecting an entry type or the ID of an entry. Note: the actual content of the dialog depends on the database mode (BibTeX or biblatex).
Sometimes the new entry contains a url field. This field usually points to the URL of the book at the respective online book store. In case you buy the book using this link, the service provider (e.g., ) receive a commission to fund the service.
You can also add an entry by simply pasting its BibTex or its DOI from your clipboard to the maintable.
Supported databases
Arxiv
ArXiv is a repository of scientific preprints in the fields of mathematics, physics, astronomy, computer science, quantitative biology, statistics, and quantitative finance (Wikipedia).
is an official Digital Object Identifier (DOI) Registration Agency of the International DOI Foundation.
ID search is carried out using the DOI.
First, API is used to fetch bibliographic information based on the ISBN. If no entry is found, the JabRef tries to get data.
ID search is carried out using the .
is a database with publications from about Swedish universities and research institutions.
ID search is carried out using the DiVA id (diva2).
JabRef uses (provided by ) to convert the given DOI to a new entry.
ID search is carried out using the DOI.
The maintains an eprint archive to which anyone can submit papers and technical reports. These eprints are given IDs based on the year of submission, e.g. the 10th submission in 2018 gets the ID "2018/10". To get the ID, you may want to use their web search form at .
ID search is carried out using the Cryptology ePrint ID.
The Library of Congress is the research library that officially serves the United States Congress and is the de facto national library of the United States ().
ID search is carried out using the (LCCN).
is a searchable online bibliographic database. It contains all of the contents of the journal Mathematical Reviews (MR) since 1940 along with an extensive author database, links to other MR entries, citations, full journal entries, and links to original articles. It contains almost 3 million items and over 1.7 million links to original articles ().
ID search is carried out using the MR number.
is a bibliographic database of life sciences and biomedical information. It includes bibliographic information for articles from academic journals covering medicine, nursing, pharmacy, dentistry, veterinary medicine, and health care. Medline also covers much of the literature in biology and biochemistry, as well as fields such as molecular evolution ().
ID search is carried out using the (PMID).
is the multilingual European Registration Agency of DOI, the standard persistent identifier for any form of intellectual property on a digital network.
ID search is carried out using the DOI.
is an online database of over eight million astronomy and physics papers from both peer reviewed and non-peer reviewed sources. Abstracts are available free online for almost all articles, and full scanned articles are available in Graphics Interchange Format (GIF) and Portable Document Format (PDF) for older articles ().
ID search is carried out using the .
Based on the title of your publication, JabRef call Crossref, which return the corresponding DOI. Then JabRef fetches the reference based on this DOI.
To return a reference, the publication needs to have a DOI.
IETF (Internet Engineering Task Force) Datatracker is a database that "contains data about the documents, working groups, meetings, agendas, minutes, presentations, and more, of the IETF." It used to be available at https://datatracker.ietf.org/ (currently down).
ID search is carried out using the (Request for Comments number) (RFC) of the IETF database.
is an abstracting and reviewing service in pure and applied mathematics. Its database contains about 4 million bibliographic entries with reviews or abstracts currently drawn from about 3,000 journals and book series, and 180,000 books. The coverage starts in the 18th century and is complete from 1868 to the present by the integration of the "Jahrbuch über die Fortschritte der Mathematik" database ().
ID search is carried out using the Zbl number.
Resources
JabRef-compatible text editors
JabRef can push entries, i.e., insert \cite{key} commands, to the following text editors:
Additionally, JabRef can natively insert citations and format a bibliography in:
See for details.
JabRef can help you refactor your reference list by automatically abbreviating or unabbreviating journal names, as explained in .
Although JabRef comes with a build-in list of journals, additional lists are available at .
JabRef allows you to create custom export filters and style files for LibreOffice. This functionality and the installation procedure are described in the help file on . Some users have created export filters that can be useful to many others.
Export filters are collected at . Style files for LibreOffice are available at .
This improves author recognition and adds support for more fields to EndNote.
Homepage:
Using this tool you can easily create a custom export filter for JabRef to build your own bibliography style. The tool itself supports:
HTML Export Filter
RTF Export Filter
OpenOffice/ LibreOffice Style File
is a tool to synchronize your paper library with a BibTeX file which might be most useful for Physicists and Mathematicians since it supports synchronization with DOI and arXiv.
is an add-in for Microsoft Word that allows the citation of references and the insertion of a bibliography into your document using your choice of formatting style. It is lightweight, transparent and does not mess up your documents.
Eratosthenes Reference Manager is a BibTeX-based bibliography manager for Android. It , supporting top-level groups and attached files/external links.
Available for Android 4.0 and up.
Unfortunately, this application is not available anymore from Google Play and must be .
is a tool for improving the JabRef-LibreOffice integration when writing for the humanities. This tool can be run to finalize a document, providing citation features that are not supported by JabRef itself.
This site offers to generate .gitignore files using common patterns for applications. For instance, you can use the keywords JabRef, Windows, Linux, macos, latex to generate a .gitignore for your daily tex work.
Homepage:
.gitignore for JabRef and friends:
This WinEdt's package allows to launch the JabRef program from within WinEdt.
A LibreOffice extension that converts JabRef references to plain text code and vice versa so that you can use your references with MS Office and other software.
Contribute to JabRef
We are really happy that you are interested in contributing to JabRef. Please take your time to look around here. We especially invite you to look into our where members introduce themselves.
I would like to improve the help page. What are the steps?
Please use the "Edit on GitHub" link in the upper right corner. Then, follow .
I would like to help translating JabRef to another language. How do I get started?
Donations keep us going! You can use Paypal, Flattr, or bank transfers. Your institution/company can contribute too, through bank transfer for example. All details are provided at https://donations.jabref.org.
Our team consists of volunteers. To provide better support, we are currently trying to get a funded developer on board. Please consider donating money!
I am a student and I want to start with something easy.
We collect good issues to start with at our . After finding something, please check our .
I want something with huge impact
Look at the discussions in our forum about . Find an interesting topic, discuss it and start contributing. Alternatively, you can check out . Although, of course, you can choose to work on ANY issue, choosing from the projects page has the advantage that these issues have already been categorized, sorted and screened by JabRef maintainers. A typical sub-classifications scheme is "priority" (high, normal and low). Fixing high priority issues is preferred.
I am a lecturer If you ask yourself how to integrate JabRef into your class, please read the . As student, you may notify your lecturer about this possibility.
I want to know how to contribute code and set up my workspace
Check out the
I need help with the code
You can talk to the core developers of JabRef in the .
I want to learn about code quality
Please head to to learn about our current efforts to measure and improve code quality.
If JabRef cannot find the reference of your DOI using this ID type, please, try the same DOI with the ID type "mEDRA". The ID type mEDRA looks for the reference corresponding to a DOI too, but using another registration agency.
Tidy up automatically your library each time you save it.
Field formats can be tidied up when saving the library. That ensures your entries to have consistent formatting. In Library → Library properties, check Enable save actions. You can now select the actions to be carried out using the 2 drop-down menus located under the table. Each action is defined by:
an entry field (upon which the action will be applied).
the type of action to be carried out (such as HTML to LaTeX, which converts HTML code to LaTeX code, as described in the window).
A click on the "circular arrow" icon enables a set of recommended formatting actions (the set of actions will depend on your library type: BibTeX or BibLaTeX).
Clears the field completely.
Escape underscores
Escapes ampersands.
Text & with &ersands ⇒ Text \& with \&ersands
Converts HTML code to LaTeX code.
Cleanup URL links.
http%3A%2F%2Fwikipedia.org ⇒ http://wikipedia.org
Converts HTML code to Unicode.
Cleans up LaTeX code:
Escape percent character (e.g.50% ⇒ 50\%)
Remove redundant $, {, and } (but not if the } is part of a command argument)
Normalizes the date to ISO date format. Format date string to yyyy-mm-dd or yyyy-mm. Keeps the existing String if it does not match one of the following formats:
"M/y" (covers 9/15, 9/2015, and 09/2015)
"MMMM (dd), yyyy" (covers September 1, 2015 and September, 2015)
"yyyy-MM-dd" (covers 2009-1-15)
Normalize month to Bib(la)TeX standard abbreviation.
Normalizes lists of persons to the Bib(la)TeX standard. This separates authors by "and"s with first names after last name separated by a comma; first names are not abbreviated.
"John Smith" ⇒ "Smith, John"
"John Smith and Black Brown, Peter" ⇒ "Smith, John and Black Brown, Peter"
"John von Neumann and John Smith and Black Brown, Peter" ⇒ "von Neumann, John and Smith, John and Black Brown, Peter".
Normalize pages to Bib(la)TeX standard. Format page numbers, separated either by commas or double-hyphens. Converts the range number format to page_number--page_number. Removes unwanted literals except for letters, numbers, and -+ signs. Keeps the existing String if the resulting field does not match the expected Regex.
Converts ordinals to LaTeX superscripts, e.g. 1st, 2nd or 3rd. Will replace ordinal numbers even if they are semantically wrong, e.g. 21rd
Removes braces encapsulating the complete field content.
Shortens DOI to more human-readable form using .
Converts Unicode characters to LaTeX encoding.
Converts LaTeX to Unicode characters if possible.
$\acute{\omega}$ ⇒ ώ
Converts units to LaTeX formatting. This includes:
Add braces around the unit to keep case.
Replace hyphen with non-break hyphen
Replace space with a hard space
Remove protective braces from words.
{In} {CDMA} ⇒ In CDMA
Changes the first letter of all words to capital case and the remaining letters to lower case.
Changes all letters to lower case.
Capitalize the first word, changes other words to lower case.
Capitalize all words, but converts articles, prepositions, and conjunctions to lower case.
Changes all letters to upper case.
Shortens lists of persons if there are more than 2 persons to "et al.".
The can also be used as modifiers in using their keys listed below.
Save action
Key
Browser Extension
The official browser extension automatically identifies and extracts bibliographic information on websites and sends them to JabRef with one click.
- - -
JabRef offers an official browser extension. It automatically identifies and extracts bibliographic information on websites and sends them to JabRef with one click.
When you find an interesting article through Google Scholar, the arXiv or journal websites, this browser extension allows you to add those references to JabRef. Even links to accompanying PDFs are sent to JabRef, where those documents can easily be downloaded, renamed, and placed in the correct folder. .
Normally, you simply install the extension from the browser store and are ready to go.
Groups
Structure your bibliography to your needs
Groups allow structuring of bibliographic libraries in a tree-like way that is similar to organizing files on disk in directories and sub-directories. The two main differences are:
While a file is always located in exactly one directory, an entry may be contained in more than one group.
Groups may use certain criteria to dynamically define their content. New entries that match these criteria are automatically added to these groups. This feature is not available in common file systems, but in several Email clients (e.g. Thunderbird and Opera).
Command line use and options
Although JabRef is primarily a GUI based application, it offers several command line options that may be useful. JabRef can even perform file conversion operations without opening the graphical interface.
Windows:
Locate JabRef.bat, for example: JabRef-5.0-portable_windows\JabRef\runtime\bin\JabRef.bat
While Chrome extensions can work in Edge (and will install), JabRef is configured to work with the Edge extension in the Edge Browser, and the Chrome extension in the Chrome Browser. It will not work if they are mixed.
After the installation, you should be able to import bibliographic references into JabRef directly from your browser. Just visit a publisher site or some other website containing bibliographic information (for example, the arXiv) and click the JabRef symbol in the Firefox search bar (or press Alt+Shift+J). Once the JabRef browser extension has extracted the references and downloaded the associated PDF's, the import window of JabRef opens.
You might want to configure JabRef so that new entries are always imported in an already opened instance of JabRef. For this, activate "Listen to remote operation on port" under the "Network" tab of the JabRef Preferences.
1) Go to zotero.org. 2) Deactivate AdBlock plus extension for the whole domain (zotero.org) by clicking on the Adblock plus extension button and sliding the corresponding slider to allow adds on the whole domain. 3) Close and reopen the browser in order to reload all the extension and their settings. 4) Verify the functioning of the Jabref extension by visiting a page you know is working to extract its bibliographic data (for example, the arXiv) by pressing the extension button or Alt + Shift + J.
In case you encounter problems in this procedure refer to issue #241 on GitHub for further help.
Error message bad interpreter: /usr/bin/python3: no such file or directory means that python3 is not installed at the expected location. Run which python3 to see if python3 is installed elsewhere. Then copy that path at the first line of jabrefHost.py maintaining #! prefix.
Check your ExecutionPolicy by using Get-ExecutionPolicy -List in PowerShell. If you get something else than Undefined for your MachinePolicy, changes are high that this policy is set by Microsoft Group Policy. In this case the option -ExecutionPolicy Bypass in JabRefHost.bat won't work. If your MachinePolicy says AllSigned you can self-sign your JabRefHost.ps1 script, by following tutorials like windows-10-signing-a-powershell-script-with-a-self-signed-certificate.
Most JabRef installations include the necessary files, so test the extension before proceeding with the following instructions. However, sometimes, a manual installation is necessary (e.g. if you use the portable version of JabRef). In this case, please take the following steps:
/usr/lib64/mozilla/native-messaging-hosts/org.jabref.jabref.json (and /usr/lib/mozilla/native-messaging-hosts/org.jabref.jabref.json) to install with admin rights for all users
~/.mozilla/native-messaging-hosts/org.jabref.jabref.json to install without admin rights for the current user
Chrome and Brave: Download and put it into
/etc/opt/chrome/native-messaging-hosts/org.jabref.jabref.json to install with admin rights for all users
Check that the Python script works. In Terminal run /Applications/JabRef.app/Contents/Resources/jabrefHost.py. If there are no errors the script is working properly. Stop the script by pressing Ctrl + D.
org.jabref.jabref.json directs the browser extension to a python script in the JabRef app, which is set to the most common install path by default (/Applications/JabRef.app/Contents/Resources/jabrefHost.py). If you have installed JabRef somewhere else, most likely to your local applications folder (~/Applications/JabRef), then you will need to update this path to the correct location. For example, in local installs this would be /Users/USER/Applications/JabRef.app/Contents/Resources/jabrefHost.py, where USER is your username.
In case you have Adblock Plus extension and Jabref extension doesn't work
In case script jabrefHost.py doesn't work
In case PowerShell script JabRefHost.ps1 cannot be executed due to ExecutionPolicy
Manual Installation
Windows
Linux
Deb, RPM or Portable
Snap
Flatpak
Browser
macOS
Local JabRef installs
Selecting a group shows the entries contained in that group. Selecting multiple groups shows the entries contained in any group (union) or those entries common in all selected groups (intersection), depending on the current settings. All this is explained in detail below.
The group interface is shown in the side pane on the left of the screen. It can be toggled on or off by pressing Alt + 3 or by the menu View → Groups. The interface has several buttons, but most functions are accessed via a context menu (i.e. a right-click). Drag-and-drop is also supported.
The main group interface
To create a group and manually assign entries to it, press the Add group button located at the bottom of the pane, enter a name for the group, then press (leaving all values at their defaults). Now select the entries to be assigned to the group, and drag-and-drop them to the group (or use Add selected entries to this group in the context menu of the group interface). Finally, select the group to see its content. Only the entries you just assigned to the group should be displayed in the entry table.
You can also automatically fill a group based on keywords. For this, you need to use a different type of groups.
When you have numerous groups, the one of interest can be displayed by typing its name in the ''Filter groups'' field located near the top of the group pane.
Selecting one group shows the entries contained in that group (accounting for hierarchical settings).
When selecting several groups, you can intersect or unionize them: Union displays all the entries of the selected groups while Intersection displays all the entries shared among the selected groups.
Button for toggling union/intersection
For example, if you have a group for the author 'Smith' and another one for the author 'Doe', selecting the groups displays the entries that they co-authored if 'Intersection' is selected. If 'Union' is selected, the entries that at least one of them authored are displayed.
To test this, create two groups having some entries in common. Click the Intersection/Union button and make sure that Union is selected. Now select both groups. You should see all entries contained in any of the two groups. Click again on the Intersection/Union. This selects Intersection. Now you should see only those entries contained in both groups (which might be none at all if groups do not share entries, or exactly the same entries if both groups contain the same entries).
Just like directories, groups are structured like a tree, with the group All Entries at the root. By right-clicking on a group and selecting Add subgroup, you can add a subgroup to the selected group. The Add group button (at the bottom of the pane) lets you create a new subgroup of the group All Entries, regardless of the currently selected group(s). The context menu also allows removing groups and/or subgroups, and to sort subgroups alphabetically. Moving groups to a different location in the tree can be done by drag-and-drop.
The properties of a group can be defined in the 'Edit group' dialog window (the same window is displayed when creating a new group). To modify the group properties, right-click on the group name in the group pane and select Edit group in the context menu.
Edit group window
Defines the name of the group, as displayed in the group pane.
A description of the group, to help you remember what it is about. This description is displayed when hovering the mouse over the group name.
An icon can be displayed in front of the group name. Choose your favorite icon among the ones available at https://materialdesignicons.com/, and enter its name of the field Icon (replacing any hyphens (-) with underscores (_)). The color of the icon can be set in the field Color.
The displayed entries depend on the hierarchical context of the group. When a group is selected, the displayed entries can be:
independent of its supergroup and of its subgroups.
a union between the entries of the group and of its subgroups.
an intersection between the entries of the group and of its supergroup.
By default, a group is independent of its position in the group's tree: When selected, the table of entries shows only the group's content (i.e. all of its entries).
For a group defined with a hierarchical context Intersection, only the entries contained in both the group and its supergroup are displayed when the group is selected.
This is especially relevant for groups based on keywords or search expression, where it is often useful to define a group that intersects its supergroup. For example, consider a supergroup containing entries with the keyword distribution and a subgroup containing entries with the keyword gauss. With the subgroup gauss defined as an intersection (of its supergroup), selecting the subgroup gauss displays entries that match both conditions, i.e. are concerned with Gaussian distributions. Note that entries that only belong to the subgroup gauss will not be shown, i.e. for an entry to be displayed when selecting gauss, it must be assigned to both the subgroup gauss and the supergroup distribution. By adding another intersection group for laplace to the supergroup distribution, the grouping can easily be extended to Laplace distributions.
The union of a group and its subgroups is the logical complement of the intersection: when defined as union, selecting the group displays both the group's own entries and its subgroups' entries.
For example, you can create a group for your references about music, and then subgroups about the music styles (classic, jazz, rock, etc.). By setting the group "Music" as union, when you subsequently add references to a subgroup, they will automatically appear in group "Music" as well (without additional action).
You can populate your Group pane by configuring JabRef to use the bibtex source's keywords = {...}, by clicking the + icon and following the previous instructions. You can nest subgroups by using the right chevron > (see here). You achieve this by editing the keywords = {...}, bibtex field in the entry source by placing > between any two keywords where the left-hand keyword is the parent group and the right-hand keyword will be its sub-group. The library entry will be placed there. Note: when you select + to do this, the first delimiter must be the right chevron, and the second must be whichever field separator you have configured (by default a comma ,).
If a refining group is a subgroup of a group that includes its subgroups -- the refining group's siblings --, these siblings are ignored when the refining group is selected.
JabRef has five types of groups:
Explicit selection. The group contains entries that were assigned manually. It behaves like a directory on disk, and contains only those entries that you explicitly assigned to it.
Searching for a keyword. The group contain entries in which a certain field (e.g. author) contains a certain keyword (e.g. Smith). This method does not require manual assignment of entries but uses information that is already present in the database.
Free search expression. Similar to Searching for a keyword, but for several keywords in several fields.
Specified keywords. This feature will gather all words found in a specific field of your choice, and create a group for each word.
Authors' last names. Groups can be generated for each author's last name.
Cited entries. The group contains the entries cited in a LaTeX document, based on its .aux file.
Groups based on explicit selection are populated only by manual assignment of entries.
Fields for collecting by using an explicit selection
After creating an explicit-selection group, you select the entries to be assigned to it and use either drag-and-drop or the context menu Add selected entries to this group of the group interface.
To remove entries from an explicit-selection group, select them and use the context menu Remove selected entries from this group of the group interface.
This method groups entries in which a specified field (e.g. author) contains a specified keyword (e.g. Smith). The mentioned example will group all entries referring to the author Smith.
Fields for collecting by searching for a keyword
The search can be case-sensitive or not (checkbox 'Case sensitive'). The search can either be done as a plain-text or a regular-expression search (checkbox 'Regular expression').
Obviously, this will work only for entries including the specified grouping field, and the quality of the grouping will depend on the content accuracy.
The content of the group is updated dynamically whenever the database changes: JabRef allows to manually assign/remove entries to/from the group by simply appending/removing the search term to/from the content of the grouping field. For example, if you add the keyword A to an entry, this entry will be added to the dedicated group automatically. This makes sense only for the keywords field or for self-defined fields, but obviously not for fields like author or year.
This is similar to the above, but rather than search for a single search term on a single field, a search expression syntax can be used. It supports logical operators (AND, OR, NOT) and allows searching multiple fields.
Fields for collecting by a free-form search expression
For example, the search expression keywords=regression and not keywords=linear groups entries concerned with non-linear regression.
The content of the group is updated dynamically whenever the database changes.
With the group type "Specified keywords", you can quickly create a set of groups appropriate for your database. This feature will gather all words found in a specific field of your choice, and create a group for each word. This is useful for instance if your database contains suitable keywords for all entries. By auto-generating groups based on the keywords field, you should have a basic set of groups at no cost. If you have an entry with "keywords = {A, B}", then this group type creates subgroups "A" and "B" both containing the entry.
You can also specify characters to ignore, for instance, commas used between keywords. These will be treated as separators between words, and not part of them. This step is important for combined keywords such as laplace distribution to be recognized as a single semantic unit. (You cannot use this option to remove complete words. Instead, delete the unwanted groups manually after they were created automatically.)
Fields for collecting by specified keywords
The content of the group is updated dynamically whenever the database changes.
The group contains the entries cited in a LaTeX document, based on its '.aux' file. The .aux file has to be specified.
Fields for collecting by cited entries
The content of the group is updated dynamically whenever the .aux file changes.
To see easily to which groups an entry belongs to, the entry table has a column dedicated to groups. For each entry, a set of color bars is displayed. The number of bars and their colors depend on the groups to which the entry belongs to.
By hovering the mouse on this column, you can see the list of groups to which an entry belongs to.
The "groups" column is displayed by default. Using the menu File → Preferences, tab Entry table, you can:
remove the "groups" column by clicking on the bin icon next to the item "Groups".
add the "groups" column by selecting the "Groups" item in the drop-down menu, and clicking on the + button located to the right of the drop-down menu.
Preferences for tab Entry table
When viewing the contents of selected group(s), a search can be performed within these contents using the regular search facility.
General preferences for groups can be accessed using File → Preferences, tab Groups.
Preferences for tab Groups
When selecting multiple groups, you can choose to:
display only entries belonging to all selected groups (intersection)
display all entries belonging to one or more of the selected groups (union). This is the default option.
The checkbox "Automatically assign new entry go selected grouping" makes it possible to automatically assign new entries to selected groups. If checked (default), upon selection of one or more groups, all the new entries created will be assigned to the selected groups. This works both for entries created from the menu button or entries pasted from the clipboard. If unchecked, new entries are not assigned to groups automatically.
If checked (default), the number of entries in each group is displayed in the group name, at the right of the group pane.
The character separating two keywords can be set in this field. The default keyword separator is a comma (,).
Groups are saved as a @COMMENT block in the .bib-file and are shared among all users (future versions of JabRef might support user-dependent groups).
Group definitions are database-specific.
Groups interface and first steps
Creating a group and adding entries to it
Display union or intersection of groups
Group tree. Creating and removing groups
Group dialog window
Name
Description
Icon and color
Hierarchical context
Independent group
Intersection between a group and its supergroup
Union between a group and its subgroups
Nesting (sub)groups
Mixing refining groups with including groups
Types of groups
Explicit selection
This method of grouping requires that all entries have a unique citation key. In case of missing or duplicate citation keys, the assignment of the affected entries cannot be correctly restored in future sessions.
Searching for a keyword in a field
Using a free-form search expression
Specified keywords
Using the cited entries of a LaTeX document
Group color bars in the entry table
Groups and searching
Preferences about groups
View
Automatically assign new entry to selected grouping
Display count of items in group
Be careful, this can slow down JabRef when a library has numerous groups.
Keyword separator
Groups in the library file
macOS:
/Applications/JabRef.app/Contents/MacOS/JabRef\
Do not use JabRef\JabRef.exe or bin/JabRef
The following documentation is for Windows, but works equally well on Linux and macOS:
In some cases, you have to specify --console to ensure that output is written to the console.
You can always specify one or more Bib(la)TeX files to load by simply listing their filenames.
Take care to specify all options before your list of file names.
Ensure that the first file name is not misunderstood as being an argument for an option; this simply means that if a boolean option like -n or -l immediately precedes a file name, add the word true as an argument.
For instance, the command line will correctly load the file original.bib, export it in docbook format to filetoexport.xml, and suppress the GUI:
The word true prevents the file name from being interpreted as an argument to the -n option.
Displays a summary of the command line options, including the list of available import and export formats.
(or --nogui)
Suppresses the JabRef window (i.e. no GUI - Graphic User Interface - is displayed).
It causes the program to exit immediately once the command line options have been processed. This option is useful for performing file conversion operations from the command line or a script.
(or --import filename[,import format] or --importToOpen filename[,import format])
Import or load the file filename.
If only the filename is specified (or if the filename is followed by a comma and a * character), JabRef will attempt to detect the file format automatically. This works for BibTeX files, and also for all files in a supported import format. If the filename is followed by a comma and the name of an import format, the given import filter will be used.
Use the -h option to get the list of available import formats.
If an export option is also specified, the import will always be processed first, and the imported or loaded file will be used by the export filter. If the GUI is not suppressed (using the -n option), any imported or loaded file will show up in the main window.
If --importToOpen is used, the content of the file will be imported into the opened tab.
Note: The -i option can be specified only once, and for one file only.
(or --output filename[,export format])
Export or save a file imported or loaded by the same command line.
If a file is imported using the -i option, that file will be exported. If no -i option is used, the last file specified (and successfully loaded) will be exported.
If only filename is specified, it will be exported in BibTeX format. If the filename is followed by a comma and an export format, the given export filter will be used.
A custom export filter can be used, and will be preferred if the export name matches both a custom and a standard export filter.
If the GUI is not suppressed (using the -n option), any export operation will be performed before the JabRef window is opened, and the imported database will show up in the window.
Note: The -o option can be specified only once, and for one file only.
XMP is an ISO standard for the creation, processing and interchange of standardized and custom metadata for digital documents and data sets.
The first option is to export all entries, which are included in the entries.bib file to the specified export.xmp file. The second argument, separated by comma, is the type of exporter used by JabRef.
The second option is to export every entry in the entries.bib in a single .xmp file. Therefore, the file name is replaced by the keyword split without a file ending! JabRef generates individual .xmp files at the path location. The file name is a combination of the identifier provided by JabRef and the cite key of the entry.
Import or load code directly from the BibTeX file. This only works for BibTeX files, and does not support files of other import formats. If it detects this command line option, the JabRef CLI will take in its following argument as a BibTeX string that represents the BibTeX article file being read in for import (usually a filename). JabRef then passes on this information to a helper function that will parse the BibTex string into entries and return the resulting BibTex entries to the JabRef CLI.
If the GUI is not suppressed (using the -n option), any imported or loaded BibTeX file will show up in the main window.
Note: The -importBibtex option can be specified only once, and for one file only.
Save to a new file all the database entries matching the given search term.
If the filename is followed by a comma and an export format, the given export filter will be used. Otherwise, the default format html-table (with Abstract and BibTeX, provided by tablerefsabsbib) is used.
Note: In addition it is also possible to search for entries within a time frame such as Year=1989-2005 (instead of only searching for entries of a certain year as in Year=2005).
Note: Search terms containing blanks need to be bracketed by quotation marks, as in (author=bock or title|keywords="computer methods")and not(author=sager)
Exports information stored in the database as Metadata to linked files. The metadata is stored as XMP metadata and as an embedded bib file. The entries can be selected by citekey. Individual pdfs can be selectec by the path to the pdf (either as given in the database or as an absolute or relative path to the pdf file itself). The keyword all may be specified to write metadata on all pdfs in the database.
As -writeMetadatatoPdf, but only write XMP metadata.
As -writeMetadatatoPdf, but only embedd a bib file.
(or --fetch=FetcherName:QueryString)
Query a Web fetcher and import the entries.
Pass both the name of a fetcher and your search term or paper id (e.g. --fetch=Medline:cancer), and the given fetcher will be run. Some fetchers will still display a GUI window if they need feedback from you.
The fetchers listed in the Web search panel can be run from the command line. To get the list of available fetchers, run --fetch without parameters.
When you compile a LaTeX document (e.g. infile.tex), an .aux file is created (infile.aux). Among other things, it contains the list of entries used in your document. JabRef can extract the references used from the base-BibTeX-file to a new .bib file (outfile.bib). This way, you will have a subdatabase containing only the entries used in the .tex file.
(or --automaticallySetFileLinks)
Automatically set file links.
(or --generateCitationKeys)
Regenerate all keys for the entries of a Bib(la)TeX file.
(or --prexp filename)
Export user preferences to an XML file. After exporting, JabRef will start normally.
(or --primp filename)
Import user preferences from an XML file (exported using the -x option, or through the GUI). After importing, JabRef will start normally.
(or --prdef key)
Reset preferences (key1, key2,..., or all).
(or --blank)
Do not open any files at startup
(or --version)
Display the version number of JabRef.
Show debug level messages. The log files are stored in an internal file. See FAQs for Windows, Linux, macOS depending on your OS where to find it.
Show info and error messages in the console.
As developer, you pass arguments to the app using gradle's --app switch. Enclose the arguments in quotes. For instance --args="--debug" turns on debug mode.
You can then view the event log in JabRef as follows:
Basics
This description applies since JabRef 5.0, because JabRef comes with a pre-bundled Java-Runtime Environment
Write BibTexEntry as metadata to PDF: -w CITEKEY1[,CITEKEY2][,CITEKEYn] | PDF1[,PDF2][,PDFn] | all
Write BibTexEntry as XMP metadata to PDF: -writeXMPtoPdf CITEKEY1[,CITEKEY2][,CITEKEYn] | PDF1[,PDF2][,PDFn] | all
Write BibTexEntry as XMP metadata to PDF: -embeddMetadataInPdf CITEKEY1[,CITEKEY2][,CITEKEYn] | PDF1[,PDF2][,PDFn] | all
Fetch entries from Web: -f=FetcherName:QueryString
Subdatabase from .aux file: -a infile[.aux],outfile[.bib] base-BibTeX-file
Set file links: -asfl
Regenerate keys: -g
Export preferences: -x filename
Import preferences: -p filename
Reset preferences: -d key
No files at startup: -b
Version: -v
Debug mode: --debug
Display output in the console: --console
Development
About BibTeX and its fields
The data format of JabRef is Bib(La)TeX
JabRef is is a program for working with BibTeX and biblatex databases. JabRef program uses no separate internal file format but directly works with BibTeX and biblatex. That means, your BibTeX/biblatex file is kept as is when opening in JabRef and saving again: You normally load and save your libraries directly in the BibTeX/biblatex.bib format. In addition, you can also import and export bibliography libraries in a number of other formats into JabRef.
JabRef helps you work with your BibTeX libraries, but there are still rules to keep in mind when editing your entries, to ensure that your library is treated properly by the BibTeX program.
JabRef's conventions
Fields in the header of a bib file
JabRef stores the encoding of the file and (in case a shared SQL database is used) the ID of the shared library in the header of the bib file.
Encoding
% Encoding: <encoding>: States the encoding of a BibTeX file. E.g., % Encoding: UTF-8
To enable auto save, JabRef adds % DBID: <id> to the header. This helps JabRef identifying the SQL database where the file belongs. E.g., % DBID: 2mvhh73ge3hc5fosdsvuoa808t.
An entry consists of entrytype, citekey, fields and field content. The BibTeX and Biblatex standards define a wide range of entrytypes and fields, which should give much leeway. Users that have further needs will be able to edit their entries and come up with custom entrytypes, fields and citekeys, as long as the syntax is honored.
There is a lot of different fields in BibTeX, and some additional fields that you can set in JabRef.
The following fields are recognized by the default bibliography styles:
bibtexkey A unique string used to refer to the entry in LaTeX documents. Note that when referencing an entry from LaTeX, the key must match case-sensitively with the reference string. Some characters should not be used in bibtexkey as they are not compatible or not recommended:
{ } ( ) , \ " - # ~ ^ : '
address Usually the address of the publisher or other type of institution. For major publishing houses, you may omit the information entirely or give simply the city. For small publishers, on the other hand, you can help the reader by giving the complete address.
BibLaTeX defines more fields. It gets especially interesting in the context of date handling. See the for detais.
date The date of the publication. Can also include date ranges (e.g., 2014-04-07/2014-04-10).
BibTeX is extremely popular, and many people have used it to store information in non-standard fields. The information in these non-standard fields may be ignored by BibTeX.
Here is a list of some of the more common non-standard fields ("*" = not directly supported by JabRef):
affiliation The authors affiliation.
abstract An abstract of the work.
doi The Digital Object Identifier, a permanent identifier given to documents.
To help in managing your bibliography, and extend the features of BibTeX, JabRef defines some specific fields:
You can create new fields by .
Generally, you can use LaTeX commands inside of fields containing text. BibTeX will automatically format your reference lists, and those fields that are included in the lists will be (de)capitalized according to your bibliography style. To ensure that certain characters remain capitalized, enclose them in braces, like in the word {B}elgium.
An institution name should be inside {} brackets.
If the institution name also includes its abbreviation, this abbreviation should be also in {} brackets.
- long manual explaining the workings of BibTeX, the BibTeX format, and the available entry types with required and optional fields.
(large file > 6000 publications)
Searching within the library
The search bar is located in the icon bar.
To make the cursor jump to the search field, you can:
annote An annotation. It is not used by the standard bibliography styles, but may be used by others that produce an annotated bibliography.
author This field should contain the complete author list for your entry. The names are separated by the word and, even if there are more than two authors. Each name can be written in two equivalent forms:
Donald E. Knuth or Knuth, Donald E.
Eddie van Halen or van Halen, Eddie
The second form should be used for authors with more than two names, to differentiate between middle names and last names.
booktitle Title of a book, part of which is being cited. For book entries, use the title field instead.
chapter A chapter (or section or whatever) number.
crossref The library key of the entry being cross referenced.
edition The edition of a book--for example, ``Second''. This should be an ordinal, and should have the first letter capitalized, as shown here; the standard styles convert to lower case when necessary.
editor This field is analogue to the author field. If there is also an author field, then the editor field gives the editor of the book or collection in which the reference appears.
howpublished How something strange has been published. The first word should be capitalized.
institution The sponsoring institution of a technical report.
journal The name of a journal or magazine. The name of a journal can be abbreviated using a "string". To define such string, use the string editor.
key Used for alphabetizing, cross referencing, and creating a label when the ``author'' information is missing. This field should not be confused with the key that appears in the \cite command and at the beginning of the library entry.
month The month in which the work was published or, for an unpublished work, in which it was written. You should use the standard three-letter abbreviation of the English names (jan, feb, mar, apr, may, jun, jul, aug, sep, oct, nov, dec).
note Any additional information that can help the reader. The first word should be capitalized.
number
The number of a journal, magazine, technical report, or of a work in a series. An issue of a journal or magazine is usually identified by its volume and number; the organization that issues a technical report usually gives it a number; and sometimes books are given numbers in a named series.
organization The organization that sponsors a conference or that publishes a manual.
pages One or more page numbers or range of numbers, such as 42--111 or 7,41,73--97 or 43+ (which indicates page 43 and following pages). The standard styles convert a single dash (as in 7-33) to the double dash used in TeX to denote number ranges (as in 7--3).
publisher The publisher's name.
school The name of the academic institution where a thesis was written.
series The name of a series or set of books. When citing an entire book, the title field gives its title and an optional series field gives the name of a series or multi-volume set in which the book is published.
title The title of the work. The capitalization may depend on the bibliography style and on the language used. For words that have to be capitalized (such as a proper noun), enclose the word (or its first letter) in braces.
type The type of a technical report - for example, "Research Note".
volume The volume of a journal or multivolume book.
year The year of publication or, for an unpublished work, the year it was written. Generally it should consist of four numerals, such as 1984, although the standard styles can handle any year whose last four nonpunctuation characters are numerals, such as "(about 1984)". This field is required for most entry types.
eid The Electronic identifier is for electronic journals that also appear in print. This number replaces the page number, and is used to find the article within the printed volume. Sometimes also called citation number.
contents A table of contents
copyright Copyright information.
ISBN The International Standard Book Number.
ISSN The International Standard Serial Number. Used to identify a journal.
keywords Key words used for searching or possibly for annotation.
language The language the document is in.
location A location associated with the entry, such as the city in which a conference took place.
LCCN The Library of Congress Control Number. I've also seen this as lib-congress.
mrnumber The number of Mathematical Reviews.
price The price of the document.
size The physical dimensions of a work.
URL The WWW Uniform Resource Locator that points to the item being referenced.
To find the search history, you can right click in the search field. Only ten recent searches will be displayed in the sub-menu. You can find clear history button under your search history.
At the right of the search text field, 2 buttons allow for selecting some settings:
Whether or not the search query is case sensitive.
In a normal search, the program searches your library for all occurrences of the words in your search string, once you entered it. Only entries containing all words will be considered matches. To search for sequences of words, enclose the sequences in double-quotes. For instance, the query progress "marine aquaculture" will match entries containing both the word "progress" and the phrase "marine aquaculture".
All entries that do not match are hidden, leaving for display the matching entries only.
To stop displaying the search results, just clear the search field, press Esc or click on the "Clear" (X) button.
In order to only search for content within specific fields and/or to include logical operators in the search expression, a special syntax is available in which these can be specified. Both the field specification and the search term support regular expressions.
To search for entries whose author contains miller, enter: author = miller. The = sign is actually a shorthand for contains. Searching for an exact match is possible using matches or ==.
If the search term contains spaces, enclose it in quotes. Do not use spaces in the field specification! E.g to search for entries with the title "image processing", type: title = "image processing"
To search for entries with the title or the keyword "image processing", type: title|keywords = "image processing". To search for entries without the title or the keyword "image processing", type: title|keywords != "image processing" It is also possible to chain search expressions. In general, you can use and, or, not, and parentheses as intuitively expected:
(author = miller or title|keywords = "image processing") and not author = brown and != author = blue
Logical Operator / Symbol
Explanation
XY
X followed by Y
X|Y
Either X or Y
(X)
The selection of field types to search (required, optional, all) is always overruled by the field specification in the search expression. If a field is not given, all fields are searched. For example, video and year == 1932 will search for entries with any field containing video and the field year being exactly 1932.
JabRef defines the following pseudo fields:
Pseudo field
Purpose
Example
anyfield
Search in any field
anyfield contains fruit: search for entries having one of its fields containing the word fruit. This is identical to just writing apple. It may be more useful as anyfield matches apple, where one field must be exactly apple for a match.
anykeyword
Regular expressions (RegEx for short) define a language for representing patterns matching text, for example when searching. There are different types of RegEx languages. JabRef uses regular expressions as defined in Java. For extensive advanced information about Java's RegEx patterns, please have a look at the Java documentation and at the Java tutorial.
By default, regular expressions do not account for upper/lower casing. Hence, while the examples below are all in lower case, they match also upper- and mixed case strings.
If casing is important to your search, activate the case-sensitive button.
. means: any character
+ means: one or more times
author != .+ returns entries with empty or no author field.
^ means: the beginning of a line
[a-zA-Z] means: a through z or A through Z, inclusive (range)
$ means: the end of a line
X{n} means: X, exactly n times
owner != ^[a-zA-Z]{3}$ returns empty and non-three-letter owners
\b means: word boundary
\B means: not a word boundary
keywords = \buv\b matches uv but not lluvia (it does match uv-b however)
author = \bblack\b matches black but neither blackwell nor blacker
author == black does not match john black, but author = \bblack\b does.
author = \bblack\B matches blackwell and blacker, but not black.
? means: none or one copy of the preceding character.
{n,m} means: at least n, but not more than m copies of the preceding character.
[ ] defines a character class
title =neighbou?r matches neighbour and neighbor, and also neighbours and neighbors, and neighbouring and neighboring, etc.
title = neighbou?rs?\b matches neighbour and neighbor, and also neighbours and neighbors, but neither neighbouring nor neighboring.
author = s[aá]nchez matches sanchez and sánchez.
abstract = model{1,2}ing matches modeling and modelling.
abstract = modell?ing also matches modeling and modelling.
year == 200[5-9]|201[0-1]specifies the range of years 2005-2011 (200[5-9] specifies years 2005-2009;| means "or"; 201[0-1] specifies years 2010-2011).
author = (John|Doe)matches entries written by either John or Doe.
author = (John|Doe).+(John|Doe)matches entries written by both John or Doe.
If a special character (i.e. ()[]{}\^-=$!|?*+. ) is included in your search string, it has to be escaped with a backslash, such as \} for }.
It means that to search for a string including a backslash, two consecutive backslashes (\\) have to be used: abstract = xori{\\c{c}}o matches xoriço.
The character " has a special meaning: it is used to group words into phrases for exact matches. So, if you search for a string that includes a double quotation, the double quotation character has to be replaced with the hexadecimal character 22 in ASCII table \x22.
Neither a simple backslash \", nor a double backslash \\" will work as an escape for ". Neither author = {\"o}quist with regular expression disabled, nor author = \{\\\"O\}quist with regular expression enabled, will find anything, even if the name {\"o}quist exists in the library.
Hence, to search for {\"o}quist as an author, you must input author = \{\\\x22o\}quist, with regular expressions enabled (Note: the \, {, _ and the } are escaped with a backslash; see above).
Quantifier
Explanation
X?
X, once or not at all
X*
X, zero or more times
X+
Quantifier
Explanation
X??
X, once or not at all
X*?
X, zero or more times
X+?
Quantifier
Explanation
X?+
X, once or not at all
X*+
X, zero or more times
X++
Search history
Screenshot of the search bar
Search settings
Simple search
Search using regular expressions
Make sure that the button "regular expressions" is activated
General syntax
Search within specific Fields
Search for terms containing spaces
Search using parentheses, and, or and not
Regular Expression search and Field Types
Pseudo fields
Advanced use of regular expressions
Regular expressions and casing
Searching for entries with an empty or missing field
Searching for a given word
Searching with optional spelling
Searching for strings with a special character (()[]{}\^-=$!|?*+.)
Searching for strings with double quotation marks (")
Q: I use JabRef in my work. Should I mention JabRef in my publications?
A: You are not obliged to cite JabRef, but we would greatly appreciate it if you do.
@Article{jabref,
author = {Oliver Kopp and Carl Christian Snethlage and Christoph Schwentker},
title = {{JabRef}: {BibTeX}-based literature management software},
journal = {TUGboat},
issn = {0896-3207},
issue = {138},
volume = {44},
number = {3},
pages = {441--447},
doi = {10.47397/tb/44-3/tb138kopp-jabref},
year = {2023},
}
A: You can try resetting the settings. Depending on your operating system, you may need to pass the command line arguments -d all -n to JabRef.
(E.g. in Windows this means jabref-X.Y.exe -d all -n, where X.Y means the version number of JabRef. If this does not help, run regedit and delete the folder HKEY_CURRENT_USER\SOFTWARE\JavaSoft\Prefs\net\sf\jabref. Be careful with regedit, as you can easily corrupt the basic Windows configuration.)
A: Don't panic. No data should be damaged in your bib library. Since version 5.0 the columns in the main entry table are stored differently internally. You can reset the preferences by command line. See above.
A: Check your configuration. Disable some or all of following preferences:
disable fulltext index (File → Preferences → Linked files → Fulltext Index → ...)
disable time stamps (File → Preferences → General → Time Stamp → ...)
disable field formatters (Library → Library Properties → Saving → Save actions → ...)
Any preference that has the potential to affect all your entries at once is worth inspecting.
We collect performance related issues .
A: We are collecting all publications we hear about at .
A: Yes. In File → Preferences → General, set "Default Encoding" to UTF8 and select an alternative user interface language in "Language" if required.
A: In File → Preference → Single Instance, ensure that "Enforce single JabRef Instance (and allow remote operations) using port [6050]" is checked. Note that 6050 is the default port and can be changed if desired.
A: Paste the DOI in the table of entries, and JabRef will create the corresponding entry. Additionally, in Library → New entry you can select the type of the identifier in the field "ID type" and enter the identifier in "ID". A click on "Generate" should create the correct entry. If this does not work, try a web search. For more details, see .
A: There are several reasons why JabRef cannot find your identifier online. For example, your DOI is not listed in the if you are using the CrossRef fetcher. Another reason could be that the search result for your DOI on returns invalid BibTeX which is unable to be read by JabRef. Try a instead.
A: To add this translator field to all entry types, you can use File → Preferences → Custom editor tabs and add a translator field under one of JabRef's general field tabs (see s). To add this translator field to a specific entry type, edit the specific entry type(s) (File → Customize entry types) and add a translator field under required fields or optional fields, as you like (see ).
A: Open File → Preferences. In the “File” panel, you will find an option called “Do not wrap the following fields when saving”. This option contains a semicolon-separated list of field names. Any field you add to this list will always be stored without introduction of line breaks.
A: Yes, you can use the parameter --importToOpen bibfile of the .
A: You need to override the default file directory for this specific library. In Library → Library properties you can override the Default file directory setting. There, you can either enter the path in General file directory (for it to be valid for all users of the file) or in User-specific file directory (for it to be valid for you only). If you simply enter “.” (a dot, without the quotes), the file directory will be the same as the .bib file directory. To place your files in a subdirectory called subdir, you can enter “./subdir” (without the quotes). Files will automatically be linked with relative paths if the files are placed in the default file directory or in a directory below it. More details on the .
A: In Library → Library properties you can choose a library-specific directory in the field “General file directory”. If you want to set a directory only for you (so that other users should use the default directory), use the field “User-specific file directory”.
A: Use File → Export. As “Filter” choose “OpenOffice/LibreOffice CSV”.
A: Select the entries and go to Library → Manage keywords. There you can manage keywords appearing in all selected entries or in any selected entry. New keywords are added to all selected entries. More details about .
In File → Preferences, tab External programs, button "Manage external file types", you can add arbitrary types. See the .
A: Use curly braces to tell BibTeX to keep your author field as-is: {European Commission}. In BibLaTeX, you can use label = {EC} to have EC05 as a label for a publication of the European Commission in the year 2005.
A: Take a look at “Bibliographies and citations” at the . For German readers, there is the .
A: Your JabRef library is already a file in Bib(La)TeX format. To export a specific subset of your library, select the entries to be exported and then choose File → Export → Save selected as plain BibTeX....
A: Paste the Bib(la)Tex code of a reference into the table of entries, and JabRef will create the new corresponding entry.
A: Drag & drop a PDF onto the table of entries (between two existing entries). JabRef will analyze the PDF and create a new entry. More details about
A: Use : with one click, JabRef browser extension identifies and extracts bibliographic information on websites and sends them to JabRef.
A: JabRef can fetch the DOI for you: select the entries and go to Lookup → Search document identifier online → DOI.
A: JabRef can fetch the PDFs for you: select the entries and to Lookup → Search full text documents online.
A: Upon compilation, LaTeX generates a file with the extension ".aux". This file contains the keys of the cited references (among other things). Using this AUX file, JabRef can extract the relevant entries. Choose the menu Tools → New sublibrary based on AUX file... , then select the AUX file.
A: In Library → Library properties, you will find a section named "Save actions". After enabling this feature, you can choose which actions should be performed for each field upon saving. That should help you keep your library tidy. More details about , , and .
A: Google scholar is blocking "automated" crawls which generate too much traffic in a short time. JabRef already uses a two-step approach (with the prefetched list before crawling the actual BibTeX data) to circumvent this. However, after too many crawls JabRef is being blocked. To solve this issue, see the section in the Google Scholar database.
A: You have to start vim with the option --servername (such as vim --servername MyVimServer). If you get the Unknown option argument message, it means your version of vim does not include the clientserver feature (you can check with vim --version). In such a case, you have to install another version of vim.
A: In JabRef 3.0 plugin support was removed because the development team cannot keep up plugin support anymore. Nevertheless, plugins can be integrated in JabRef. See for the current status and discussion. Please contact the author of the respective plugin and ask them to port their plugin into JabRef's code.
A: Enter XYZ in the search field located at the upper left-hand corner of the preference window.
A: This error message has been observed on systems that use . System calls to inotify_init and inotify_add_watch set errno to EMFILE when inotify has reached its limit. The most common reason is that inotify is running too many instances. To solve this problem, contact your system administrator and request that they increase the limits defined in /proc/sys/fs/inotify/max_user_* files.
A: JabRef opens the pdf document with the application Gnome has set by default: Evince. If you want JabRef to open another application (Okular or other), in your file explorer, right-click on whatever pdf file > properties > Open With > choose your application > Set as default at the bottom right corner. From now on, both when you double-click a pdf file in your file explorer or when you ask JabRef to open it via its document viewer, your chosen application will be used.
A: JabRef automatically recognizes a change in the bib file on disk and notifies the user of it. This is cool for network drives.
If you use version control, a few advices are given for a smoother .
In addition, we have .
A: You can either choose to or to .
A: JabRef uses https to connect to external catalogs to fetch bibliographic data. The concrete port used depends on the external service. Mostly, the standard port 443 is used. When connecting to a SQL database, the standard port for PostgreSQL and MySQL is used. JabRef offers a local interface used by the browser plugin. For that, JabRef uses a proprietary, text-based protocol offered on the configurable port 6050.
A: After consulting and checking whether your question has been please head over to the .
A: See .
Customize the citation key generator
The pattern used in the auto generation of citation labels can be set for each of the standard entry types in File → Preferences, tab Citation key generator. A detailed description can be found in the .
The key pattern can contain any text you wish, in addition to field markers that indicate that a specific field of the entry should be inserted at that position of the key. A field marker generally consists of the field name (in upper case letters) enclosed in square braces, e.g., [TITLE]. If the field is undefined in an entry at the time of key generation, no text will be inserted by the field marker. A field enclosed in square braces can be further changed by appending one or more of the separated by :, e.g., [TITLE:abbr].
For an entry with the title An awesome paper on JabRef
disable count of items in group (File → Preferences → Groups → ...)
Sort the maintable columns from A-Z (low to highest), not from Z-A. See issue 8977.
Q: I have tried the latest version of JabRef. Since then, the library entries are no longer displayed in any old version. What should I do?
Q: I have a huge library. What can I do to mitigate performance issues?
Q: Are there any publications dealing with JabRef?
Q: Does JabRef support non-English languages or UTF8 in general?
Q: If I double click a BibTeX file in the file browser, JabRef always opens a new window. Can JabRef open the libraries in the same window just in a different tab?
Q: I have a DOI/ISBN/ePrint/etc. Is it possible to create an entry directly out of this identifier?
Q: Why can't JabRef find any DOI/ISBN/ePrint/etc.?
Q: I miss a field translator, lastfollowedon, etc. How can I add such fields?
Q: How do I prevent JabRef from introducing line breaks in certain fields (such as “title”) when saving the .bib file?
Q: Is it possible to append entries from a BibTeX file, e.g. from my web browser to the currently opened library?
Q: How do I link external files with paths relative to my .bib file, so I can move my library along with its files to another directory?
Q: Can I use a bib-file specific PDF directory?
Q: How do I export my bibliography entries into a simple text file, so I can import them into a spreadsheet (in LibreOffice, OpenOffice, MS Office, etc.)?
Q: How do I add and remove keywords of multiple entries?
Q: When linking a file, I cannot set the correct type. How do I add new types?
Q: When an organization is provided as author, my BibTeX style doesn't recognize it. For instance, why is “European Commission” converted to “Commission, E.”?
Q: Is there a FAQ on BibTeX?
Q: How do I export a subset of my library to BibTeX (or BibLaTeX) format?
Q: I have the Bib(La)TeX code of a reference. How to add it to my library as a new entry?
Q: I have the PDF of a publication. How to make it a new entry of my library?
Q: I am looking at a publication in my web browser. How to make it a new entry of my library?
Q: I am missing the DOI of some of my publications. Can JabRef help?
Q: I am missing the PDF of some of my publications. Can JabRef help?
Q: How do I export a subset corresponding to my LaTeX file?
Q: When I modify my library, I would like that JabRef performs entry cleaning automatically. How to do this?
Q: Search on Google scholar does not work anymore. Why?
Q: JabRef does not push to vim, although I have configured the right path and server name. What is going on?
Q: My plugins stopped working. Why?
Q: In the preferences, I want to change the option XYZ. How to find it?
Q: "Unable to monitor file changes. Please close files and processes and restart. You may encounter errors if you continue with this session."
Q: "I'm using JabRef with Linux (Gnome desktop version) and each time I want to see a pdf document in JabRef, the document viewer Evince is opened. I would prefer to open it with Okular."
Q: How does JabRef support me in sharing my Bib(La)TeX libraries?
Q: How to do collaborative work on a library?
Q: Which network protocols and ports are used by JabRef?
Q: My question is not answered here. What can I do?
Q: There is a mistake in this FAQ, a dead link, or I have written a better/new explanation for a question! What can I do?
Several special field markers are offered, which extract only a specific part of a field. Feel free to suggest new special field markers.
[auth]: The last name of the first author
[authFirstFull]: Get the von part and last name of the first author
[authForeIni]: The forename initial of the first author
[auth.etal]: The last name of the first author, and the last name of the second author if there are two authors or .etal if there are more than two.
[authEtAl]: The last name of the first author, and the last name of the second author if there are two authors or EtAl if there are more than two. This is similar to auth.etal. The difference is that the authors are not separated by . and in case of more than 2 authors EtAl instead of .etal is appended.
[auth.auth.ea]: The last name of the first two authors, separated by .. If there are more than two authors, adds .ea.
[authors]: The last name of all authors.
[authorsN]: The last name of up to N authors. If there are more authors, EtAl is appended
[authIniN]: The beginning of each author's last name, using at most N characters in total.
[authN]: The first N characters of the first author's last name.
[authN_M]: The first N characters of the Mth author's last name.
[authorIni]: The first 5 characters of the first author's last name, and the last name initial of the remaining authors.
[authshort]: The last name if one author is given; the first character of up to three authors' last names if more than one author is given. A plus character is added, if there are more than three authors
[authorsAlpha]: Corresponds to the BibTeX style “alpha”,
One author: The first three letters of the last name
Two to four authors: The first letter of the last name of each author
[authorLast]: The last name of the last author.
[authorLastForeIni]: The forename initial of the last author.
Note: If there is no author (as in the case of an edited book), then all of the above [auth...] markers will use the editor(s) (if any) as a fallback. Thus, the editor(s) of a book with no author will be treated as the author(s) for label-generation purposes. If you do not want this behavior, i.e. you require a marker which expands to nothing if there is no author, use pureauth instead of auth in the above codes. For example, [pureauth], or [pureauthors3].
The name of institutions and companies often contain spaces and words that have a specific meaning in the author field, e.g., and. The full name should be enclosed in braces ({}) to prevent the name from being miss-parsed for these cases. Names enclosed in braces are often abbreviated while generating citation keys to avoid creating excessively long keys. For example, when using [authors], author = {European Union Aviation Safety Agency} is abbreviated to Agency, whereas author = {{European Union Aviation Safety Agency}} is abbreviated to EUASA.
[edtr]: The last name of the first editor
[edtrIniN]: The beginning of each editor's last name, using at most N characters
[editors]: The last name of all editors
[editorLast]: The last name of the last editor
[editorIni]: The first 5 characters of the first editor's last name, and the last name initials of the remaining editors
[edtrN]: The first N characters of the first editor's last name
[edtrN_M]: The first N characters of the Mth editor's last name
[edtr.edtr.ea]: The last name of the first two editors, separated by .. If there are more than two editors, adds .ea
[edtrshort]: The last name if one editor is given; the first character of up to three editors' last names if more than one editor is given. A plus character is added, if there are more than three editors
[edtrForeIni]: The forename initial of the first editor
[editorLastForeIni]: The forename initial of the last editor
[shorttitle]: The first 3 words of the title, ignoring any function words (see below). For example, An awesome paper on JabRef becomes AwesomePaperJabref
[shorttitleINI]: The first 3 words of the title, abbreviated.
[veryshorttitle]: The first word of the title, ignoring any function words (see below). For example, An awesome paper on JabRef becomes Awesome
[camel]: Capitalize and concatenate all the words of the title. For example, An awesome paper on JabRef becomes AnAwesomePaperOnJabref
[camelN]: Capitalize and concatenate no more than the first N words of the title. For example, An awesome paper on JabRef plus four more words becomes:
AnAwesomePaperOnJabref with [camel5], and
[title]: Capitalize all the significant words of the title, and concatenate them. For example, An awesome paper on JabRef becomes AnAwesomePaperonJabref
[fulltitle]: The title with unchanged capitalization.
JabRef considers the following words to be function words: "a", "about", "above", "across", "against", "along", "among", "an", "and", "around", "at", "before", "behind", "below", "beneath", "beside", "between", "beyond", "but", "by", "down", "during", "except", "for", "for", "from", "in", "inside", "into", "like", "near", "nor", "of", "off", "on", "onto", "or", "since", "so", "the", "through", "to", "toward", "under", "until", "up", "upon", "with", "within", "without", "yet".
[entrytype]: The type of the entry, e.g., Article, InProceedings, etc
[firstpage]: The number of the first page of the publication (Caution: this will return the lowest number found in the pages field, i.e. for 7,41,73--97 it will return 7.)
[pageprefix]: The non-digit prefix of pages (like L for L7) or "" if no non-digit prefix exists (like "" for 7,41,73--97)
[keywordN]: Keyword number N from the “keywords” field, assuming keywords are separated by commas or semicolons
[keywordsN]: Up to N keywords from the "keywords" field
[lastpage]: The number of the last page of the publication (See the remark on firstpage)
[shortyear]: The last 2 digits of the publication year
In addition to the special field markers, most BibTeX, biblatex, and JabRef field names can be accessed by their capitalized name directly. If you regularly use a field name not on this list, you are encouraged to add it.
[AUTHOR]: Ada Lovelace and Charles Babbage becomes AdaLovelaceandCharlesBabbage
[DATE]: 2020-09-25
[DAY]: 02 becomes 2
[GROUPS]: The groups or subgroups in JabRef. Subgroup AppleTrees and group Trees becomes AppleTreesTrees
[MONTH]: 03 becomes March
[YEAR]: 2020
Note: You can use any field present in the entry. However, multi-line fields like comment or abstract can produce unexpected results, and their use is discouraged. The customize entry types section contains more information about fields and their customization.
A field name (or one of the above pseudo-field names) may optionally be followed by one or more modifiers.
Generally, modifiers are applied in the order they are specified. In the following, we present a list of the most common modifiers alongside a short explanation:
:abbr: Abbreviates the text produced by the field name or special field marker. Only the first character and subsequent characters following white space will be included. For example:
[journal:abbr] would from the journal name Journal of Fish Biology produce JoFB
[title:abbr] would from the title An awesome paper on JabRef produce AAPoJ
[camel:abbr] would from the title An awesome paper on JabRef produce AAPOJ
:lower: Forces the text inserted by the field marker to be in lowercase.
[auth:lower] expands the last name of the first author in lowercase
:upper: Forces the text inserted by the field marker to be in uppercase.
[auth:upper] expands the last name of the first author in uppercase
:capitalize: Changes the first character of each word to uppercase, all other characters are converted to lowercase. For example, an example title will be converted to An Example Title
:titlecase: Changes the first character of all normal words to uppercase, all function words (see above) are converted to lowercase. Example: example title with An function Word will be converted to Example Title with an Function Word
:truncateN: Truncates the string after the N:th character and trims any trailing whitespaces. For example, [fulltitle:truncate3] will convert A Title to A T.
:sentencecase: Changes the first character of the first word to uppercase, all remaining words are converted to lowercase. Example: an Example Title will be converted to An example title
:regex("pattern", "replacement"): Applies regular expression pattern matching and replacement. For example,
[auth.etal:regex("\\.etal","EtAl"):regex("\\.","And")] will extract the last name of the first author, and the last name of the second author, if there are two authors or .etal if there are more than two. The first regex() replaces .etal with EtAl
:(x): The string between the parentheses will be inserted if the field marker preceding this modifier resolves to an empty value. The placeholder x may be any string. For instance, the marker [VOLUME:(unknown)] will return the entry's volume if set, and the string unknown if the entry's VOLUME field is not set.
Formatters are primarily used as save actions, but their key value can be used as a modifier. All available actions can be found in the list of save actions.
Regular expressions (or RegEx for short) match patterns within a string. In other words, they are a way to search for (or replace) text within a closed off sequence of characters. They can enhance citation key patterns by altering modifiers even further (e.g. via :regex("pattern", "replacement")). Another use case for them is to replace existing key patterns.
Keep in mind, Jabref uses a Java flavored regular expressions engine (there are multiple engines) and therefore treats \ and some other special meta-characters as escape characters. If you want to include any backslash into your RegEx, you have to use \\ instead of \.
In addition to using regular expression replacement as modifiers of the field markers within citation key patterns, regular expression matching and replacement can be done after the key patterns have been applied. In this case, the regular expression and replacement string are entered in the separate text fields above the citation key patterns section. If the replacement string is empty, then matches of the regular expression will be removed from the generated key.
The regex (?<=.{12}+).+ with an empty replacement string will cut the length of all citation keys to 12.
The citation key generator preferences contain an option for removing unwanted characters. Add or remove characters to the right of "Remove the following characters:" to control which characters are included in the citation keys.
Removing - from this list will allow it to be used while generating citation keys.
If you have not defined a key pattern for a certain entry type, the Default pattern will be used. You can change the default pattern - its setting is above the list of entry types in the Citation key generator section of the Preferences dialog.
The default key pattern is [auth][year], and this could produce keys like e.g. Yared1998 If the key is not unique in the current database, it is made unique by adding one of the letters a-z until a unique key is found. Thus, the labels might look like:
Yared1998Yared1998aYared1998b
Note: In order for your changes to be retained, you must hit "enter" on your keyboard before clicking on the "Save" button.
To change the citation key pattern to [authors][camel] for all libraries without individual settings, execute the following steps:
Open the preferences
Navigate to "Citation key generator"
Change the default pattern to [authors][camel]
Press "Enter" (forgetting to do this is a leading cause of puzzlement)
Click "Save"
To change the citation key patterns for a single library to [auth][shortyear],
Make sure the library is open and selected in the JabRef main window
From the "Library" menu, open the "Citation key pattern" setting
Set the pattern for the desired entry types, and press the apply button.
tests if the search term is not contained in the field (equivalent to not ... contains ...)
Search among the keywords
anykeyword matches apple: search for entries which have the word apple among its keywords. However, as this also matches pineapple, it may be more useful in searches of the type anykeyword matches apple, which will not match apples or pineapple
key
Search for citation keys
citationkey == miller2005: search for an entry whose citation key is miller2005
entrytype
Search for entries of a certain type
entrytype = thesis: search entries whose type (as displayed in the entrytype column) contains the word thesis (which would be phdthesis and mastersthesis)
X, one or more times
X{n}
X, exactly n times
X{n,}
X, at least n times
X{n,m}
X, at least n but not more than m times
X, one or more times
X{n}?
X, exactly n times
X{n,}?
X, at least n times
X{n,m}?
X, at least n but not more than m times
X, one or more times
X{n}+
X, exactly n times
X{n,}+
X, at least n times
X{n,m}+
X, at least n but not more than m times
More than four authors: The first letter of the first three authors' last name. A + is added at the end if it is not in the list of unwanted characters.
AnAwesome with [camel2].
. The second
regex()
replaces any
.
between entries with two authors with
And
.
Custom export filters
JabRef allows you to define and use your own export filters, in the same way as the standard export filters are defined. An export filter is defined by one or more layout files, which with the help of a collection of built-in formatter routines specify the format of the exported files. Your layout files must be prepared in a text editor outside of JabRef.
The custom export format of JabRef is an alternative to the Citation Style Language, which is an XML-based format to describe bibliographic rendering.
The only requirement for a valid export filter is the existence of a file with the extension .layout. To add a new custom export filter, open the dialog box File → Preferences, go to the section Custom export formats, and click on Add. A new dialog box will appear, allowing you to specify a name for the export filter (which will appear as one of the choices in the File type dropdown menu of the file dialog when you use the File → Export menu choice in the JabRef window), the path to the .layout file, and the preferred file extension for the export filter (which will be the suggested extension in the file dialog when you use the export filter). Note that if you intend to use the custom export filter also for "Copy...->Export to Clipboard" in the maintable, the extension must be one of the following: txt, rtf, rdf, xml, html, htm, csv, or ris.
To see examples of how export filters are made, look for the package containing the layout files for the standard export filters on our download page.
Regarding tool support, there is the to quickly create export filters.
Let us assume that we are creating an HTML export filter. While the export filter only needs to consist of a single .layout file, which in this case could be called html.layout, you may also want to add two files called html.begin.layout and html.end.layout. The former contains the header part of the output, and the latter the footer part. JabRef will look for these two files whenever the export filter is used, and if found, either of these will be copied verbatim to the output before or after the individual entries are written.
Note that these files must reside in the same directory as html.layout, and must be named by inserting .begin and .end, respectively. In our example export filter, these could look like the following:
The file html.layout provides the default template for exporting one single entry. If you want to use different templates for different entry types, you can do this by adding entry-specific .layout files. These must also reside in the same directory as the main layout file, and are named by inserting .entrytype into the name of the main layout file. The entry type name must be in all lowercase. In our example, we might want to add a template for book entries, and this would go into the file html.book.layout. For a PhD thesis we would add the file html.phdthesis.layout, and so on. These files are similar to the default layout file, except that they will only be used for entries of the matching type. Note that the default file can easily be made general enough to cover most entry types in most export filters.
Layout files are created using a simple markup format where commands are identified by a preceding backslash. All text not identified as part of a command will be copied verbatim to the output file.
An arbitrary word preceded by a backslash, e.g. \author, \editor, \title or \year, will be interpreted as a reference to the corresponding field, which will be copied directly to the output.
Often there will be a need for some preprocessing of the field contents before output. This is done using a field formatter - a java class containing a single method that manipulates the contents of a field.
A formatter is used by inserting the \format command followed by the formatter name in square braces, and the field command in curly braces, e.g.:
\format[ToLowerCase]{\author}
You can also specify multiple formatters separated by commas. These will be called sequentially, from left to right, e.g.
\format[ToLowerCase,HTMLChars]{\author}
will cause the formatter ToLowerCase to be called first, and then HTMLChars will be called to format the result. You can list an arbitrary number of formatters in this way.
The argument to the formatters, withing the curly braces, does not have to be a field command. Instead, you can insert normal text, which will then be passed to the formatters instead of the contents of any field. This can be useful for some fomatters, e.g. the CurrentDate formatter (described below).
Some formatters take an extra argument, given in parentheses immediately after the formatter name. The argument can be enclosed in quotes, which is necessary if it includes the parenthesis characters. For instance, \format[Replace("\s,_")]{\journal} calls the Replace formatter with the argument \s,_ (which results in the "journal" field after replacing all whitespace by underscores).
See below for a list of built-in export formatters.
Some static output might only make sense if a specific field is set. For instance, say we want to follow the editor names with the text (Ed.). This can be done with the following text:
However, if the editor field has not been set - it might not even make sense for the entry being exported - the (Ed.) would be left hanging. This can be prevented by instead using the \begin and \end commands:
The \begin and \end commands make sure the text in between is printed if and only if the field referred in the curly braces is defined for the entry being exported.
A conditional block can also be dependent on more than one field, and the content is only printed when simple boolean conditions are satisfied. Three boolean operators are provided:
AND operator : &, &&
OR operator : |, ||
For example, to output text only if both year and month are set, use a block like the following: \begin{year&&month}Month: \format[HTMLChars]{\month}\end{year&&month}
which will print "Month: " plus the contents of the month field, but only if also the year field is defined.
As an example for the usage of the NOT operator, consider the following:
\begin{!year}\format[HTMLChars]{(no year)}\end{!year}
Here, "no year" is printed as output text if no year field is defined.
Note: Use of the \begin and \end commands is a key to creating layout files that work well with a variety of entry types.
If you wish to separate your entries into groups based on a certain field, use the grouped output commands. Grouped output is very similar to conditional output, except that the text in between is printed only if the field referred in the curly braces has changed value.
For example, let's assume I wish to group by keyword. Before exporting the file, make sure you have sorted your entries based on keyword. Now use the following commands to group by keyword:
Authors : this formatter provides formatting options for the author and editor fields; for detailed information, see below. It deprecates a range of dedicated formatters provided in versions of JabRef prior to 2.7.
CreateBibORDFAuthors : formats authors for according to the requirements of the Bibliographic Ontology (bibo).
To accommodate for the numerous citation styles, the Authors formatter allows flexible control over the layout of the author list. The formatter takes a comma-separated list of options, by which the default values can be overridden. The following option/value pairs are currently available, where the default values are given in curly brackets.
AuthorSort = [ {FirstFirst} | LastFirst | LastFirstFirstFirst ]
specifies the order in which the author names are formatted.
FirstFirst : first names are followed by the surname.
LastFirst : the authors' surnames are followed by their first names, separated by a comma.
LastFirstFirstFirst
AuthorAbbr = [ FullName | LastName | {Initials} | InitialsNoSpace | FirstInitial | MiddleInitial ]
specifies how the author names are abbreviated.
FullName : shows full author names; first names are not abbreviated.
LastName : show only surnames, first names are removed.
Initials
AuthorPunc = [ {FullPunc} | NoPunc | NoComma | NoPeriod ]
specifies the punctuation used in the author list when AuthorAbbr is used
FullPunc : no changes are made to punctuation.
NoPunc : all full stops and commas are removed from the author name.
NoComma
AuthorSep = [ {Comma} | And | Colon | Semicolon | Sep=<string> ]
specifies the separator to be used between authors. Any separator can be specified, with the Sep=<string> option. Note that appropriate spaces need to be added around string.
AuthorLastSep = [ Comma | {And} | Colon | Semicolon | Amp | Oxford | LastSep=<string> ]
specifies the last separator in the author list. Any separator can be specified, with the LastSep=<string> option. Note that appropriate spaces need to be added around string.
AuthorNumber = [ {inf} | <integer> ]
specifies the number of authors that are printed. If the number of authors exceeds the maximum specified, the authorlist is replaced by the first author (or any number specified by AuthorNumberEtAl), followed by EtAlString.
AuthorNumberEtAl = [ {1} | <integer> ]
specifies the number of authors that are printed if the total number of authors exceeds AuthorNumber. This argument can only be given after AuthorNumber has already been given.
EtAlString = [ { et al.} | EtAl=<string> ]
specifies the string used to replace multiple authors. Any string can be given, using EtAl=<string>
If an option is unspecified, the default value (shown in curly brackets above) is used. Therefore, only layout options that differ from the defaults need to be specified. The order in which the options are defined is (mostly) irrelevant. So, for example,
\format[Authors(Initials,Oxford)]{\author}
is equivalent to
\format[Authors(Oxford,Initials)]{\author}
As mentioned, the order in which the options are specified is irrelevant. There is one possibility for ambiguity, and that is if both AuthorSep and AuthorLastSep are given. In that case, the first applicable value encountered would be for AuthorSep, and the second for AuthorLastSep. It is good practise to specify both when changing the default, to avoid ambiguity.
Given the following authors, "Joe James Doe and Mary Jane and Bruce Bar and Arthur Kay" ,the Authors formatter will give the following results:
Authors(), or equivalently, Authors(FirstFirst,Initials,FullPunc,Comma,And,inf,EtAl= et al.)
J. J. Doe, M. Jane, B. Bar and A. Kay
Authors(LastFirstFirstFirst,MiddleInitial,Semicolon)
Doe, Joe J.; Mary Jane; Bruce Bar and Arthur Kay
Authors(LastFirst,InitialsNoSpace,NoPunc,Oxford)
Doe JJ, Jane M, Bar B, and Kay A
Authors(2,EtAl= and others)
J. J. Doe and others
Most commonly available citation formats should be possible with this formatter. For even more advanced options, consider using the Custom Formatters detailed below.
This formatter iterates over all file links, or all file links of a specified type, outputting a format string given as the first argument. The format string can contain a number of escape sequences indicating file link information to be inserted into the string.
This formatter can take an optional second argument specifying the name of a file type. If specified, the iteration will only include those files with a file type matching the given name (case-insensitively). If specified as an empty argument, all file links will be included.
After the second argument, pairs of additional arguments can be added in order to specify regular expression replacements to be done upon the inserted link information before insertion into the output string. A non-paired argument will be ignored. In order to specify replacements without filtering on file types, use an empty second argument.
The escape sequences for embedding information are as follows:
\i : This inserts the iteration index (starting from 1), and can be useful if the output list of files should be enumerated.
\p : This inserts the file path of the file link.
\f
For instance, an entry could contain a file link to the file "/home/john/report.pdf" of the "PDF" type with description "John's final report". Using the WrapFileLinks formatter with the following argument:
\format[WrapFileLinks(\i. \d (\p))]{\file}
would give the following output:
John's final report (/home/john/report.pdf)
If the entry contained a second file link to the file "/home/john/draft.txt" of the "Text file" type with description 'An early "draft"', the output would be as follows:
John's final report (/home/john/report.pdf)
An early "draft" (/home/john/draft.txt)
If the formatter was called with a second argument, the list would be filtered. For instance:
If we wanted this output to be part of an XML styled output, the quotes in the file description could cause problems. Adding two additional arguments to translate the quotes into XML characters solves this:
If none of the available formatters can do what you want to achieve, you can add your own by implementing the net.sf.jabref.export.layout.LayoutFormatter interface. If you insert your class into the net.sf.jabref.export.layout.format package, you can call the formatter by its class name only, like with the standard formatters. Otherwise, you must call the formatter by its fully qualified name (including package name). In any case, the formatter must be in your classpath when running JabRef.
From JabRef 2.2, it is possible to define custom name formatters using the BibTeX-sty-file syntax. This allows ultimate flexibility, but is a cumbersome to write
You can define your own formatter in the preference tab "Name Formatter" using the following format and then use it with the name given to it as any other formatter
<case1>@<range11>@<format>@<range12>@<format>@<range13>...@@ <case2>@<range21>@... and so on.
This format first splits the task to format a list of author into cases depending on how many authors there are (this is since some formats differ depending on how many authors there are). Each individual case is separated by @@ and contains instructions on how to format each author in the case. These instructions are separated by a @.
Cases are identified using integers (1, 2, 3, etc.) or the character * (matches any number of authors) and will tell the formatter to apply the following instructions if there are a number of less or equal of authors given.
Ranges are either <integer>..<integer>, <integer> or the character * using a 1 based index for indexing authors from the given list of authors. Integer indexes can be negative to denote them to start from the end of the list where -1 is the last author.
For instance with an authorlist of "Joe Doe and Mary Jane and Bruce Bar and Arthur Kay":
1..3 will affect Joe, Mary and Bruce
4..4 will affect Arthur
* will affect all of them
The <format>-strings use the BibTeX formatter format:
The four letters v, f, l, j indicate the name parts von, first, last, jr which are used within curly braces. A single letter v, f, l, j indicates that the name should be abbreviated. If one of these letters or letter pairs is encountered JabRef will output all the respective names (possibly abbreviated), but the whole expression in curly braces is only printed if the name part exists.
For instance if the format is "{ll} {vv {von Part}} {ff}" and the names are "Mary Kay and John von Neumann", then JabRef will output "Kay Mary" (with two space between last and first) and "Neuman von von Part John".
I give two examples but would rather point you to the BibTeX documentation.
Small example: "{ll}, {f.}" will turn "Joe Doe" into "Doe, J."
Large example:
To turn:
"Joe Doe and Mary Jane and Bruce Bar and Arthur Kay"
into
"Doe, J., Jane, M., Bar, B. and Kay, A."
you would use
1@*@{ll}, {f}.@@2@1@{ll}, {f}.@2@ and {ll}, {f}.@@*@1..-3@{ll}, {f}., @-2@{ll}, {f}.@-1@ and {ll}, {f}.
NOT operator : !
CreateDocBookAuthors
: formats the author field in DocBook style.
CreateDocBookEditors : formats the editor field in DocBook style.
CurrentDate : outputs the current date. With no argument, this formatter outputs the current date and time in the format "yyyy.MM.dd hh:mm:ss z" (date, time and time zone). By giving a different format string as argument, the date format can be customized. For example \format[CurrentDate]{yyyy.MM.dd} will give the date only, e.g. 2005.11.30.
DateFormatter : formats a date. With no argument, the date is given in ISO-format (yyyy-MM-dd), which is also the expected format of the input. The argument may contain yyyy, MM, and dd in any combination. For example \format[DateFormatter(MM/yyyy)]{\date} will output 07/2016 if the date field contains 2016-07-15.
Default : takes a single argument, which serves as a default value. If the string to format is non-empty, it is output without changes. If it is empty, the default value is output. For instance, \format[Default(unknown)]{\year} will output the entry's year if set, and "unknown" if no year is set.
DOIStrip : strips any prefixes from the DOI string.
DOICheck : provides the full url for a DOI link.
EntryTypeFormatter : camel case of entry types, so "inbook" -> "InBook".
FileLink(filetype) : if no argument is given, this formatter outputs the first external file link encoded in the field. To work, the formatter must be supplied with the contents of the "file" field.
This formatter takes the name of an external file type as an optional argument, specified in parentheses after the formatter name. For instance, \format[FileLink(pdf)]{\file} specifies pdf as an argument. When an argument is given, the formatter selects the first file link of the specified type. In the example, the path to the first PDF link will be output.
FirstPage : returns the first page from the "pages" field, if set. For instance, if the pages field is set to "345-360" or "345--360", this formatter will return "345".
FormatChars : This formatter converts LaTeX character sequences their equicalent unicode characters and removes other LaTeX commands without handling them.
FormatPagesForHTML : replaces "--" with "-".
FormatPagesForXML : replaces "--" with an XML en-dash.
GetOpenOfficeType : returns the number used by the OpenOffice.org bibliography system (versions 1.x and 2.x) to denote the type of this entry.
HTMLChars : replaces TeX-specific special characters (e.g. {\"{a}} or {\sigma}) with their HTML representations, and translates LaTeX commands \emph, \textit, \textbf, \texttt, \underline, \textsuperscript, \textsubscript, \sout into HTML equivalents.
HTMLParagraphs : interprets two consecutive newlines (e.g. \n \n) as the beginning of a new paragraph and creates paragraph-html-tags accordingly.
IfPlural : outputs its first argument if the input field looks like an author list with two or more names, or its second argument otherwise. E.g. \format[IfPlural(Eds.,Ed.)]{\editor} will output "Eds." if there is more than one editor, and "Ed." if there is only one.
JournalAbbreviator : The given input text is abbreviated according to the journal abbreviation lists. If no abbreviation for input is found (e.g. not in list or already abbreviated), the input will be returned unmodified. For instance, when using \format[JournalAbbreviator]{\journal}, "Physical Review Letters" gets "Phys. Rev. Lett."
LastPage : returns the last page from the "pages" field, if set. For instance, if the pages field is set to "345-360" or "345--360", this formatter will return "360".
NoSpaceBetweenAbbreviations : LayoutFormatter that removes the space between abbreviated First names. Example: J. R. R. Tolkien becomes J.R.R. Tolkien.
NotFoundFormatter : Formatter used to signal that a formatter hasn't been found. This can be used for graceful degradation if a layout uses an undefined format.
Number : outputs the 1-based sequence number of the current entry in the current export. This formatter can be used to make a numbered list of entries. The sequence number depends on the current entry's place in the current sort order, not on the number of calls to this formatter.
Ordinal : replaces numbers with ordinals so 1 is replaced with 1st etc.
RemoveBrackets : removes all curly brackets "{" or "}".
RemoveBracketsAddComma : removes all curly brackets "{" or "}". The closing curly bracket is replaced by a comma.
RemoveLatexCommands : removes LaTeX commands like \em, \textbf, etc. If used together with HTMLChars or XMLChars, this formatter should be called last.
RemoveTilde : replaces the tilde character used in LaTeX as a non-breakable space by a regular space. Useful in combination with the NameFormatter discussed in the next section.
RemoveWhitespace : removes all whitespace characters.
Replace(regexp,replacewith) : does a regular expression replacement. To use this formatter, a two-part argument must be given. The parts are separated by a comma. To indicate the comma character, use an escape sequence: ,
The first part is the regular expression to search for. Remember that any commma character must be preceded by a backslash, and consequently a literal backslash must be written as a pair of backslashes. A description of Java regular expressions can be found at vogella's repository.
The second part is the text to replace all matches with.
RisAuthors : to be documented.
RisKeywords : to be documented.
RisMonth : to be documented.
RTFChars : replaces TeX-specific special characters (e.g. {^a} or {"{o}}) with their RTF representations, and translates LaTeX commands \emph, \textit, \textbf into RTF equivalents.
ShortMonth : formats the month field to use 3 letter BibTeX strings (jan, feb, mar, apr, ...).
ToLowerCase : turns all characters into lower case.
ToUpperCase : turns all characters into upper case.
WrapContent : This formatter outputs the input value after adding a prefix and a postfix, as long as the input value is non-empty. If the input value is empty, an empty string is output (the prefix and postfix are not output in this case). The formatter requires an argument containing the prefix and postix separated by a comma. To include the comma character in either, use an escape sequence (,).
WrapFileLinks : See below.
XMLChars : replaces TeX-specific special characters (e.g. {^a} or {"{o}}) with their XML representations.
: the first author is formatted as LastFirst, the subsequent authors as FirstFirst.
: all first names are abbreviated.
InitialsNospace : as Initials, with any spaces between initials removed.
FirstInitial : only first initial is shown.
MiddleInitial : first name is shown, but all middle names are abbreviated.
: all commas are removed from the author name.
NoPeriod : all full stops are removed from the author name.
: This inserts the name of the file link's type.
\x : This inserts the file's extension, if any.
\d : This inserts the file link's description, if any.
Some field names in the XML format differ from the field names in the BibTeX/BibLaTeX format and can therefore be not directly mapped between the formats. Therefore this help file provides a list of all field mappings.
BibTeX/biblatex entry type
XML entry type
The field mapping for import and export is mostly the same, but there are some differences, as not all field exists in both formats. Additionally, some fields have to be treated differently during import/export.
BibTeX/BibLaTeX
XML field
The following fields are BibTeX/biblatex only fields, they have no representation in office XML. In the resulting XML file, they are represented with the prefix BIBTEX_
BibTeX/biblatex only fields
XML representation
The XML field SourceType contains the associated entry type from the first table, while the original BibTeX/BibLaTex entrytype is preserved in the field BIBTEX_ENTRY.
The following fields are XML-only fields, they have no BibTeX/biblatex representation: In the resulting bib database they are represented with the prefix msbib-.
BibTeX/BibLaTex represenation
XML field
The following fields are treated as follows during export:
BibTeX/biblatex representation
XML field
The following fields are treated as follows during import:
BibTeX/biblatex representation
XML field
OpenOffice/LibreOffice integration
This feature offers an interface for inserting citations and formatting a Bibliography in an OpenOffice or LibreOffice Writer document from JabRef.
Throughout this help document, whenever the name OpenOffice is used, it can be interchanged with LibreOffice.
To communicate with OpenOffice, JabRef must first connect to a running OpenOffice instance. You need to start OpenOffice and enter your document before connecting from JabRef.
JabRef needs to know the location of your OpenOffice executable (soffice.exe on Windows, and soffice on other platforms), and the directory where several OpenOffice jar files reside. If you connect by clicking the Connect button, JabRef will try to automatically determine these locations. If this does not work, you need to connect using the Manual connect button, which will open a window asking you for the needed locations.
Authors/Editors (single author/editor is enclosed in curly braces)
Corporate
author (if entry type is patent)
Inventor
book
Book
inbook
BookSection
booklet
BookSection
incollection
BookSection
article
JournalArticle
inproceedings
ConferenceProceedings
conference
ConferenceProceedings
proceedings
ConferenceProceedings
collection
ConferenceProceedings
techreport
Report
manual
Report
mastersthesis
Report
phdthesis
Report
unpublished
Report
patent
Patent
misc
Misc
electronic
ElectronicSource
online
InternetSite
periodical
ArticleInAPeriodical
bibtexkey
Tag
title
Title
year
series
BIBTEX_Series
abstract
BIBTEX_Abstract
keywords
msbib-numberofvolume
NumberVolumes
msbib-periodical
PeriodicalTitle
msbib-day
booktitle
ConferenceName
journal
JournalName
journaltitle
organization
ConferenceName
journaltitle
Journal
location
Field mappings
BibTeX/BibLaTeX only fields
MS-Bib only fields
Special Export treatment
Special Import treatment
Year
BIBTEX_KeyWords
Day
JournalName
City, StateProvince, CountryRegion
After the connection has been established, you can insert citations by selecting one or more entries in JabRef and using the Push to OpenOffice button in the dropdown menu of JabRef's toolbar, or by using the appropriate button in the OpenOffice panel in the side pane. This will insert citations for the selected entries at the current cursor position in the OpenOffice document, and update the bibliography to contain the full reference.
Note: JabRef does not use OpenOffice's built-in bibliography system, because of the limitations of that system. A document containing citations inserted from JabRef will not generally be compatible with other reference managers such as Bibus and Zotero.
Two different types of citations can be inserted - either a citation in parenthesis, "(Author 2007)", or an in-text citation, "Author (2007)". This distinction is only meaningful if author-year citations are used instead of numbered citations, but the distinction will be preserved if you switch between the two styles.
If you modify entries in JabRef after inserting their citations into OpenOffice, you will need to synchronize the bibliography. By default, Automatically sync bibliography when inserting citations is enabled. This can be disabled by clicking the Settings button and unchecking Automatically sync bibliography when inserting citations. The Sync OO bibliography button will update all entries of the bibliography, provided their citation keys have not been altered (JabRef encodes the citation key into the reference name for each citation to keep track of which citation key the original JabRef entry has).
To customize the citation style you need to select a style file, or use one of the default styles. The style defines the format of citations and the format of the bibliography. You can use standard JabRef export formatters to process fields before they are sent to OpenOffice. Through the style file, the intention is to give as much flexibility in citation styles as possible. You can switch style files at any time, and use the Update button to refresh your bibliography to follow the new style.
By clicking the Select style button you can bring up a window that allows selection of either the default style or an external style file. If you want to create a new style based on the default, you can click the View button to bring up the default style contents, which can be copied into a text editor and modified.
To choose an external style file, you have two options. Either you can choose a style file directly, or you can set a style file directory. If you do the latter, you will see a list of styles from that directory (and subdirectories), and can choose one from that list.
To edit an already loaded custom style file or to reload changes that you made to a style file, click on Select style to bring up the style selection window, then right-click the currently loaded file to bring up a menu that allows you to choose either "Edit" or "Reload".
CAUTION: Please take care that your style file is saved using UTF-8 for character encoding. If you use another character encoding (even other unicode encodings such as UTF-16 or UTF-32), JabRef will not be able to process your style file.
Here is an example style file:
(Note that the layout for each entry type must be constrained to a single line in the style file - above, the lines are broken up to improve readability.)
Regarding tool support, there is the Export-Filter-Editor for Jabref to quickly create a style file.
The PROPERTIES section describes global properties for the bibliography. The following table describes the available properties:
Property
Type
Default value
Description
IsNumberEntries
boolean
false
Determines the type of citations to use. If true, number citations will be used. If false, author-year citations will be used.
The CITATION section describes the format of the citation markers inserted into the text.
The following table gives a brief description of all the available citation properties. Properties that are not given in the style file will keep their default value.
Property
Type
Default value
Description
AuthorField
string
author/editor
Field containing author names. Can specify fallback field, e.g. author/editor
If numbered entries are used, the BracketBefore and BracketAfter properties are the most important - they define which characters the citation number is wrapped in. The citation is composed as follows: [BracketBefore][Number][BracketAfter] where [Number] is the number of the citation, determined according to the ordering of the bibliography and/or the position of the citation in the text. If a citation refers to several entries, these will be separated by the string given in the property CitationSeparator (for instance, if CitationSeparator=;, the citation could look like [2;4;6]). If two or more of the entries have a series of consecutive numbers, the numbers can be grouped (for instance [2-4] for 2, 3 and 4 or [2;5-7] for 2, 5, 6 and 7). The property GroupedNumbersSeparator (default -) determines which string separates the first and last of the grouped numbers. The integer property MinimumGroupingCount (default 3) determines what number of consecutive numbers is required before entries are grouped. If MinimumGroupingCount=3, the numbers 2 and 3 will not be grouped, while 2, 3, 4 will be. If MinimumGroupingCount=0, no grouping will be done regardless of the number of consecutive numbers.
If numbered entries are not used, author-year citations will be created based on the citation properties. A parenthesis citation is composed as follows: [BracketBefore][Author][YearSeparator][Year][BracketAfter] where [Author] is the result of looking up the field or fields given in the AuthorField property, and formatting a list of authors. The list can contain up to MaxAuthors names - if more are present, the list will be composed as the first author plus the text specified in the property EtAlString. If the property MaxAuthorsFirst is given, it overrides MaxAuthors the first time each citation appears in the text.
If several, slash-separated, fields are given in the AuthorField property, they will be looked up successively if the first field is empty for the given entry. In the example above, the "author" field will be used, but if empty, the "editor" field will be used as a backup.
The names in the author list will be separated by the text given by the AuthorSeparator property, except for the last two names, which will be separated by the text given by AuthorLastSeparator. If the property AuthorLastSeparatorInText is given, it overrides the former for citations of the in-text type. This makes it possible to get citations like (Olsen & Jensen, 2008) and Olsen and Jensen (2008) for the same style.
[Year] is the result of looking up the field or fields given in the [YearField] property.
An in-text citation is composed as follows: [Author][InTextYearSeparator][BracketBefore][Year][BracketAfter] where [Author] and [Year] are resolved in exactly the same way as for the parenthesis citations.
If two different cited sources have the same authors and publication year, and author-year citations are used, their markers will need modification in order to be distinguishable. This is done automatically by appending a letter after the year for each of the publications; 'a' for the first cited reference, 'b' for the next, and so on. For instance, if the author "Olsen" has two cited papers from 2005, the citation markers will be modified to (Olsen, 2005a) and (Olsen, 2005b). In the bibliography layout, the placement of the "uniquefier" letter is indicated explicitly by inserting the virtual field uniq.
If several entries that have been "uniquefied" are cited together, they will be grouped in the citation marker. For instance, of the two entries in the example above are cited together, the citation marker will be (Olsen, 2005a, b) rather than Olsen, 2005a; Olsen, 2005b). The grouped uniquefier letters (a and b in our example) will be separated by the string specified by the UniquefierSeparator property.
Author-year citations referring more than one entry will by default be sorted chronologically. If you wish them to be sorted alphabetically, the citation property MultiCiteChronological should be set to false..
The LAYOUT section describes how the bibliography entry for each entry type in JabRef should appear. Each line should start with either the name of an entry type, or the word default, followed by a '='. The default layout will be used for all entry types for which an explicit layout hasn't been given.
The remainder of each line defines the layout, with normal text and spaces appearing literally in the bibliography entry. Information from the entry is inserted by adding \field markers with the appropriate field name (e.g. \author for inserting the author names). Formatting information for the field can be included here, following JabRef's standard export layout syntax. Refer to JabRef's documentation on custom export filters for more information about which formatters are available and tooling hints.
If author-year citations are used, you have to explicitly specify the position of the "uniquefier" letter that is added to distinguish similar-looking citations. This is done by including a marker for the virtual field uniq, typically right after the year (as shown in the example style file). The uniq field is automatically set correctly for each entry before its reference text is laid out.
To indicate formatting in the bibliography, you can use the HTML-like tag pairs <b> </b>, <i> </i>, <sup> </sup> and <sub> </sub> to specify bold text, italic text, superscript and subscript, respectively.
If you are using numbered citations, the number for each entry will be automatically inserted at the start of each entry in the reference list. By default, the numbers will be enclosed in the same brackets defined for citations. The optional citation properties BracketBeforeInList and BracketAfterInList override BracketBefore and BracketAfter if set. These can be used if you want different types of brackets (or no brackets) in the reference list. Note that these need not be brackets as such - they can be any combination of characters.
Make sure to save your Writer document in OpenDocument format (odt). Saving to Word format will lose your reference marks.
Otherwise, try to use the external tool JabRef LibreOffice Converter. This LibreOffice extension converts the reference marks to code that can be saved.
There is currently no support for footnote based citations.
The cursor may be poorly positioned after inserting a citation.
Copy-pasting the example style file directly from this page can give an unparseable file. To avoid this, instead download the example file from the link in the download section.
Make sure that libreoffice-java-common is installed on Linux for LibreOffice 5, otherwise important libraries are missing.
The snap version of LibreOffice and JabRef may cause connection issues. Try to use the *deb versions instead.
Open Office 4 will only work running under a 32-bit Java JRE/JDK on Windows because there is no 64-bit version of OpenOffice yet.
Determines how the bibliography is sorted. If true, the entries will be sorted according to the order in which they are cited. If false, the entries will be sorted alphabetically by authors.
ReferenceParagraphFormat
string
Default
Gives the name of the paragraph format to be used for the reference list. This format must be defined in your OpenOffice document.
ReferenceHeaderParagraphFormat
string
Heading 1
Gives the name of the paragraph format to be used for the headline of the reference list. This format must be defined in your OpenOffice document.
Title
string
Bibliography
The text to enter as the headline of the reference list.
AuthorLastSeparator
string
&
Text inserted between the two last author names.
AuthorLastSeparatorInText
string
If specified, this property overrides AuthorLastSeparator for in-text citations such as Smith & Jones (2001).
AuthorSeparator
string
,
Text inserted between author names except the last two.
BracketAfter
string
]
The closing bracket of citations.
BracketAfterInList
string
]
The closing bracket for citation numbering in the reference list.
BracketBefore
string
[
The opening bracket of citations.
BracketBeforeInList
string
[
The opening bracket for citation numbering in the reference list.
CitationCharacterFormat
string
Default
If FormatCitations is set to true, the character format with the name given by this property will be applied to citations. The character format must be defined in your OpenOffice document.
CitationSeparator
string
;
Text inserted between items when a citation contains multiple entries, e.g. [Smith 2001; Jones 2002]
EtAlString
string
et al.
Text inserted after author names when not all authors are listed, e.g. [Smith et al. 2001]
FormatCitations
boolean
false
Determines whether formatting should be applied to citations. If true, a character format will be applied to the citations. The property CitationCharacterFormat controls which format should be applied, and the given format must be defined in your OpenOffice document. Any font settings and effects can be chosen within OpenOffice for your chosen character format.
GroupedNumbersSeparator
string
-
Text inserted between numbers when numbered citations are grouped, e.g. [4-6]
InTextYearSeparator
string
Single Space
Text inserted between author names and starting bracket before year in in-text citations.
ItalicEtAl
boolean
true
If true, the "et al." string in citation markers is italicized.
MaxAuthors
integer
3
The maximum number of authors to list in a citation that has appeared earlier in the document.
MaxAuthorsFirst
integer
3
The maximum number of authors to list in a citation when appearing for the first time.
MinimumGroupingCount
integer
3
The minimum number of consecutive entries a citation should contain before the numbers are grouped, e.g. [4-6] vs. [4; 5; 6].
MultiCiteChronological
boolean
true
If true, multiple entries in the same citation are sorted chronologically, otherwise they are sorted alphabetically.
PageInfoSeparator
string
;
For citations with extra information, e.g. page numbers, this string is inserted between the year (for author-year citations) or the citation number (for numbered citations) and the extra information. E.g. the text between 2001 and p. 301 in [Smith 2001; p. 301].
UniquefierSeparator
string
,
Text inserted between letters used to differentiate citations with similar authors and year. E.g. the text between a and b in [Smith 2001a, b].
YearField
string
year
The field to get publication year from.
YearSeparator
string
Single Space
Text inserted between author names and year in parenthesis citations such as [Smith 2001].
Searching externally using Online Services
Using online databases to search for references
JabRef is not intended to be a tool for mass download of citations. The purpose of the Web search is to easily gather a few entries directly from within JabRef. If you use the search functionality too extensively you might get blocked (for some time). To fetch entries from an online database, choose View → Web search, and the search interface will appear in the side panel. Select the database you want to search (e.g., arXiv) in the dropdown menu. Note that it might be necessary to scroll downwards to find certain fetchers. An example for this is provided in the image below. You may opt to download the abstracts along with the cite information for each entry, by checking the Include abstracts checkbox.Then enter the words of your query, and press Enter, or the Search button. The results are displayed in the import inspection dialog. Some online services support advanced search queries. These are described below at the respective fetcher.
However, it is still possible to import hundreds or even thousands of entries from these databases. The process depends a bit on the specifics of each database, but in general works as follows: Search the database in your browser, export the result in one of the supported file formats and then .
If you need to use an HTTP proxy server, you can configure JabRef to use a proxy using the "Network" preferences (File → Preferences → Network).
Since version :
JabRef searches the databases by using the specified keywords. One can use quotes (") to keep words togehter: An example is "process mining". It is also possible to restrict the search to dedicated fields:
Thereby, JabRef supports following fields:
field
meaning
One can usually combine different searches using the Boolean operators AND and OR. Thereby, the default operator is OR.
author:smith and author:jones: search for references with authors "smith" and "jones"
author:smith or author:jones: search for references with either author "smith" or author "jones"
author:smith and not title:processor
Technial note: The search syntax is adapted from . JabRef takes the Lucene syntax and transforms it to the syntax required by the supported databases.
The includes two databases ():
the ACM Digital Library is a text collection of every article published by the , including over 60 years of archives from articles, magazines and conference proceedings.
the Guide to Computing Literature that is a bibliographic collection from major publishers in computing with over one million entries.
is a repository of scientific preprints in the fields of mathematics, physics, astronomy, computer science, quantitative biology, statistics, and quantitative finance ().
The provides bibliographic information from all public libraries in Bavaria, Germany. The format used is , , which in turn is .
makes biodiversity literature openly available to the world as part of a global biodiversity community. It is the world’s largest open access digital library for biodiversity literature and archives ().
is a public search engine for scientific and academic papers primarily with a focus on computer and information science. However, CiteSeerX has been expanding into other scholarly domains such as economics, physics, and others ().
The is a public search engine for bibliographies of scientific literature in computer science.
is an open database with over 20 million free scholarly articles harvested from over 50,000 journals and open-access repositories around the globe. Sources for these articles include repositories run by renowned universities, governments, and scholarly societies. Unpaywall is integrated into thousands of existing search engines, library platforms, and information products, making articles easy to find, track, and use for your scholarly communication needs.
The Unpaywall database has a very simple structure: it has one record for each article with a Crossref DOI. It harvests from many sources to find Open Access content, and then matches this content to these DOIs using content fingerprints. So for any given DOI, we know about any OA versions that exist anywhere.
To fetch entries from Unpaywall indirectly through Crossref, choose Search → Web search, and the search interface will appear in the side pane. Select Crossref in the dropdown menu. To start a search, enter the words of your query, and press Enter or the Fetch button.
is a computer science bibliography website listing more than 3.1 million journal articles, conference papers, and other publications on computer science ().
is is a community-driven discovery service that indexes and provides access to scholarly, peer-reviewed open access books and helps users to find trusted open access book publishers.
is a database covering more than 10000 open access journals covering all areas of science, technology, medicine, social science, and humanities ().
It is possible to limit the search by adding a field name to the search, as field:text. The supported fields are:
key
description
is a freely accessible database that indexes the full text or metadata of scholarly literature across an array of publishing formats and disciplines. Google Scholar index includes most peer-reviewed online academic journals and books, conference papers, theses and dissertations, preprints, abstracts, technical reports, and other scholarly literature, including court opinions and patents ().
Google scholar can block "automated" crawls which generate too much traffic in a short time. To unblock your IP, doing a Google scholar search in your browser might help. You will be asked to show that you are not a robot (a CAPTCHA challenge). If no CAPTCHA appears, or JabRef is still blocked after performing a search in the browser, you can also change your IP address manually or wait for some hours to get unblocked again.
Thus, the Google Scholar fetcher is not the best way to obtain lots of entries at the same time. The might be an alternative to download the bibliographic data directly from the browser.
, the GBV Union Catalogue, is a multimaterial bibliographic database of seven German federal states. It covers 41.5 million records of books, conference proceedings, periodicals, dissertations, microfilms and electronic resources.
You can simply enter words / names / years you want to search for, or you can specify search fields.
Supported fields are:
field
description
Year ranges are not supported. In case a year range is provided, it is ignored. Otherwise, GVK returns no results.
queries can be combined with and. The use of and is optional, though.
in many cases you can use the truncation sign ?
marx kapital
author:grodke and title:db2
author:"Maas,jan?"
is a scholarly research database that indexes, abstracts, and provides full-text for articles and papers on computer science, electrical engineering and electronics. IEEEXplore comprises over 180 journals, over 1,400 conference proceedings, more than 3,800 technical standards, over 1,800 eBooks and over 400 educational courses ()
is an open access digital library for the field of high energy physics ().
The INSPIRE-HEP search function merely passes your search queries onto the INSPIRE-HEP web search, so you should build your queries in the same way. INSPIRE supports the fielded search too. See for advanced help.
The following list shows some of the field indicators that can be used:
field
description
is an online database with access to more than 12 million journal articles, books, and sources in 75 disciplines.
It is possible to limit the search by adding a field name to the search, such as field:"text". The supported fields are:
title: The title of the article
author: an author of the article
journal: journal title (sent as
is a searchable online bibliographic database. It contains all of the contents of the journal Mathematical Reviews (MR) since 1940 along with an extensive author database, links to other MR entries, citations, full journal entries, and links to original articles. It contains almost 3 million items and over 1.7 million links to original articles ().
is a bibliographic database of life sciences and biomedical information. It includes bibliographic information for articles from academic journals covering medicine, nursing, pharmacy, dentistry, veterinary medicine, and health care. MEDLINE also covers much of the literature in biology and biochemistry, as well as fields such as molecular evolution ().
The Medline syntax is completely different form the Lucene syntax. One cannot use fielded search there.
There are two ways of specifying which entries to download:
Enter one or more MEDLINE IDs (separated by comma/semicolon) in the text field.
Enter a set of names and/or words to search for. You can use the operators and and or and parentheses to refine your search expression. See for full description.
May \[au\] AND Anderson \[au\]
Anderson RM \[au\] HIV \[ti\]
Valleron \[au\] 1988:2000\[dp\] HIV \[ti\]
is an online database of over eight million astronomy and physics papers from both peer-reviewed and non-peer-reviewed sources. Abstracts are available free online for almost all articles, and full scanned articles are available in Graphics Interchange Format (GIF) and Portable Document Format (PDF) for older articles ().
is a free, AI-powered, research tool for scientific literature. Developed at the Allen Institute for AI, it uses advances in natural language processing to provide summaries for scholarly papers ().
(aka Springer Science+Business Media) is a global publishing company that publishes books, e-books, and peer-reviewed journals in science, technical and medical publishing. Springer also hosts a number of scientific databases, including SpringerLink, Springer Protocols, and SpringerImages ().
is an abstracting and reviewing service in pure and applied mathematics. Its database contains about 4 million bibliographic entries with reviews or abstracts currently drawn from about 3,000 journals and book series, and 180,000 books. The coverage starts in the 18th century and is complete from 1868 to the present by the integration of the "Jahrbuch über die Fortschritte der Mathematik" database ().
You cannot use the same query syntax as in the one-line search at zbmath.org; you have to stick with the Apache Lucence syntax. This means that your query can be composed of several terms, combined by the logical operators AND and OR. Queries are case-insensitive. Further operators that can be used are NOT for logical negation, * for a right wildcard, " " for exact phrase matches, and parentheses ( ) to group terms. Optionally, it is possible to add a field name in the form field:text to limit the search results. The supported fields are:
field
description
``: Searches for publications containing a term starting with algebra (e.g. algebra, algebras, algebraic, etc.) in any field.
: Searches for publications with the exact phrase Graph Theory in their title field.
: Searches for the document with zbl number
year
The year in which the work was published
year-range
The year range (e.g., 1999-2001) the work was published
doi
The document object identifier of the work
: search for author "smith" and omit references with "processor" in the title
publisher
The publisher of the journal
abstract
The abstract of the article
journal
The journal (converted to GVK's zti field)
year
The year of publication (converted to GVK's erj field)
thm
topics
slw
key words
txt
tables of content
num
numbers, e.g. ISBN
kon
names of conferences
ppn
Pica Production Numbers of the GVK
bkl
Basisklassifikation-numbers
spaces in person names are not supported yet. Please use the truncation sign ? after the first name for several given names. E.g. per Maas,jan?
collection
The collecion
fulltext
Search in the fulltext
k
search in keywords
pt
to Jstor)
pt: publication title
Valleron \[au\] AND 1987:2000\[dp\] AND (AIDS \[ti\] OR HIV\[ti\])
Anderson \[au\] AND Nature \[ta\]
Population \[ta\]
year
Year - sent in the py field
yearrange
Year range - sent in the py field
cc
MSC code
dt
document type (possible values are j for journal articles, b for books, a for book articles)
title:"Graph Theory" yearrange:2010-2020: Searches for documents containing the exact phrase Graph Theory in their title that are published between 2010 and 2020.
so:Combinatorica: Searches for documents published in the journal Combinatorica.
cc:"(05C|90C)": Searches for documents with MSC code in 05C or 90C.
la:"es | pt": Searches for documents written in Spanish or Portuguese.
sw:python: Searches for publications using the softwarepython.
en:arXiv: Searches for entries with a link to an arXiv preprint.
br:"Claude Berge": Searches for publications with biographical information on Claude Berge.
author
The author of the work
title
The title of the work
journal
title
The title of the article
doi
The DOI of the article
issn
all
all words. Not specifYing a search key results in an "all" search
title
title words (converted to GVK's tit field)
author
author
search author names
title
search in title
journal
author
Author, editor - sent in the au field
title
Author, editor - sent in the ti field
journal
Using a Proxy Server
Search Syntax
Examples
Supported databases
ACM Portal
arXiv
Bibliotheksverbund Bayern (BVB)
Biodiversity Heritage Library
CiteSeerX
Collection of Computer Science Bibliographies (CCSB)
Crossref / Unpaywalll
DBLP
DOAB
DOAJ
Google Scholar
Currently not working, because Google changed their API
Searches author, editors, etc. (converted to GVK's per field)
Here either the common abbreviation or the 5 letter CODEN abbreviation for a journal can be used. Volume and page can also be included, separated by commas. For instance, j Phys. Rev.,D54,1 looks in the journal Phys. Rev., volume D54, page 1.
Comparison of the Medline (txt), Medline (xml), and RIS format
The Medline (txt) format can be used by a simple text document. Here, you have to write the field names at the beginning of each line. The Medline (xml) format is a XML document. The field name has to be written between < and >. For further information visit https://www.nlm.nih.gov/bsd/licensee/elements_descriptions.html. Medline (txt) and Medline (xml) always take the type "article". RIS works similar to Medline (txt) with the difference that different fields are supported and the file extension is "ris".
In other sources, you might encounter "MedlinePlain" as a synonym for "Medline (txt)" and "Medline" as a synonym for "Medline (XML)".
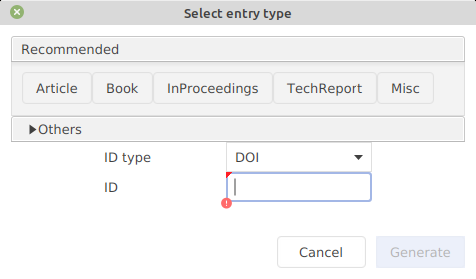
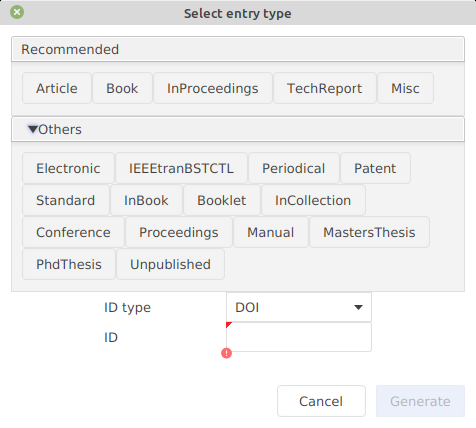
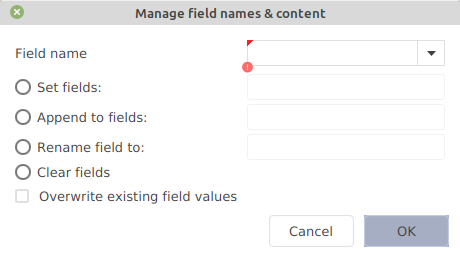
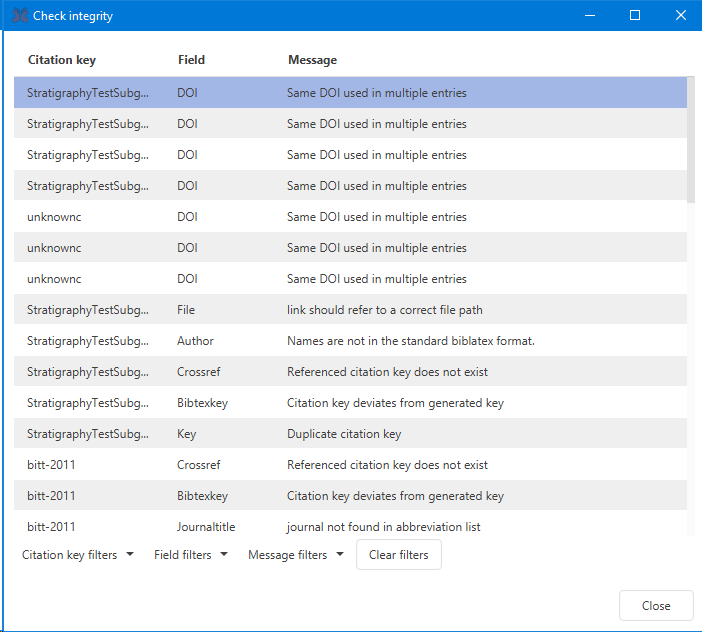
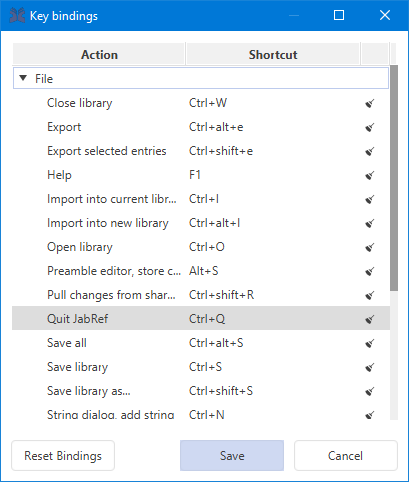
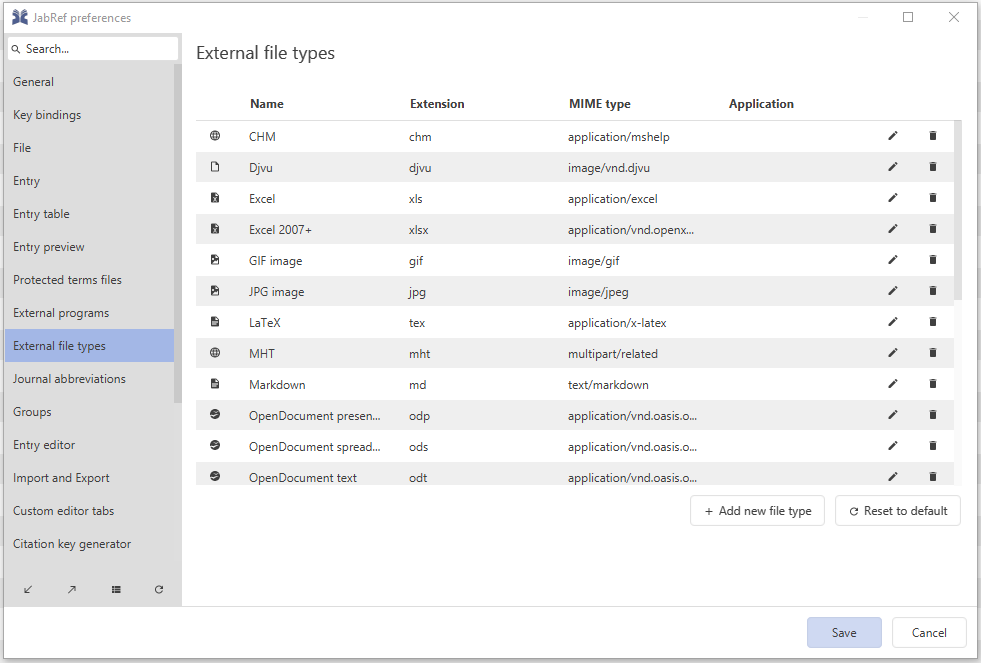

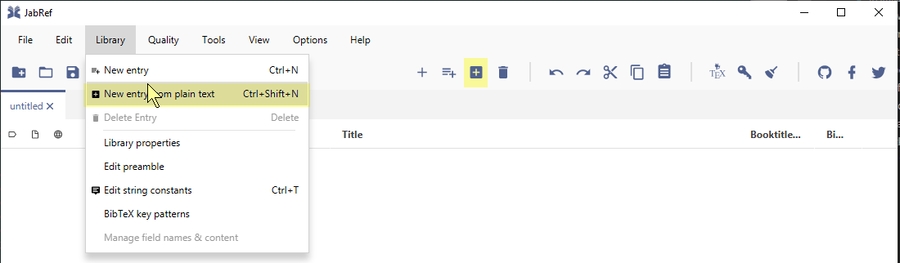
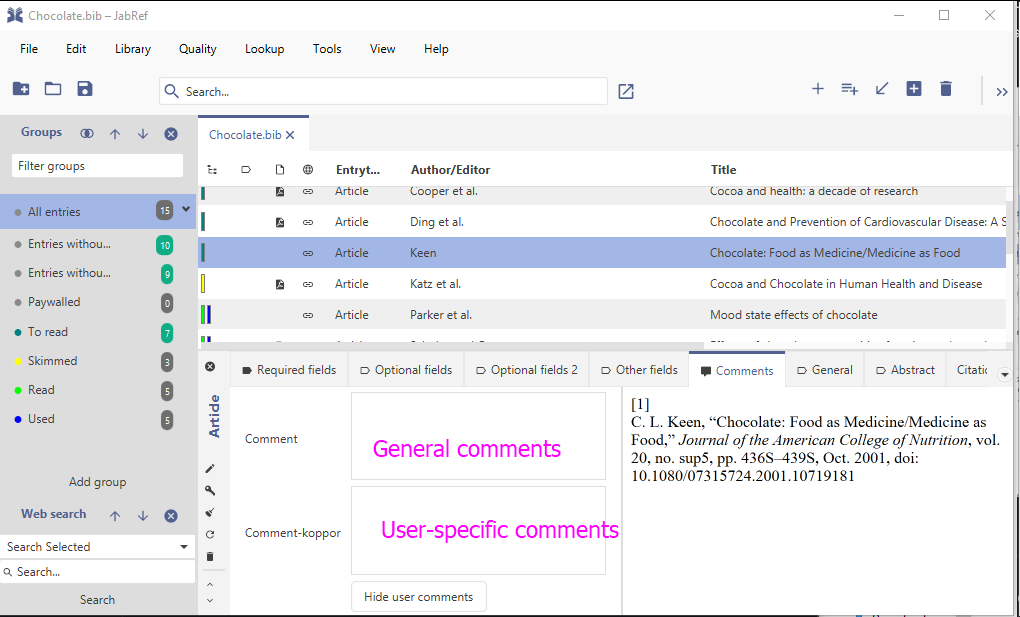
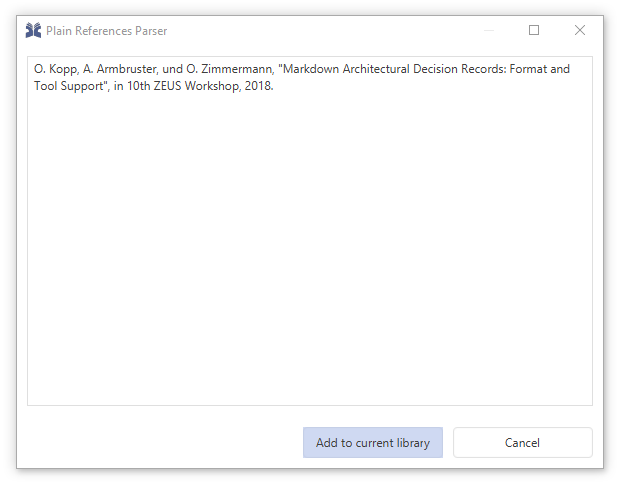
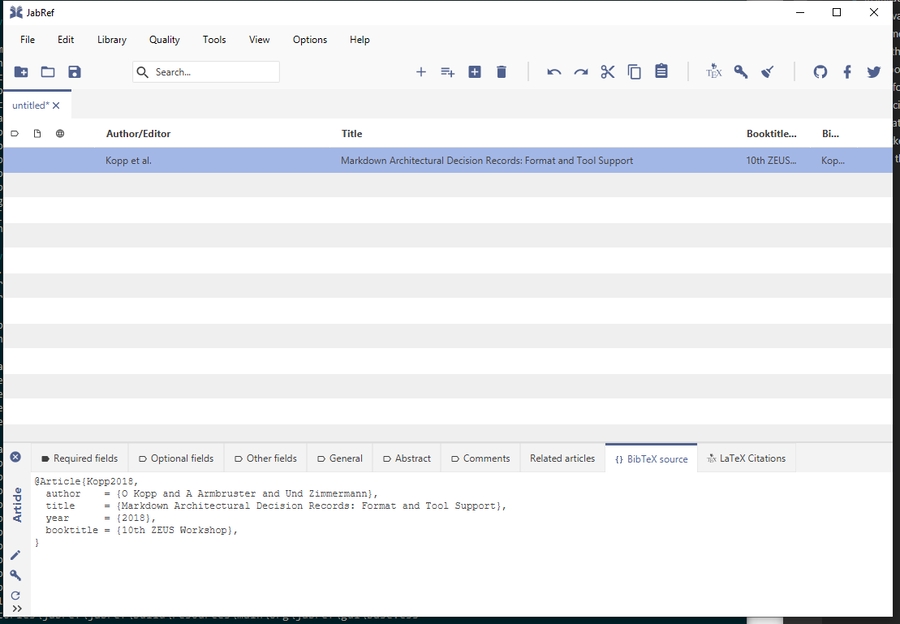
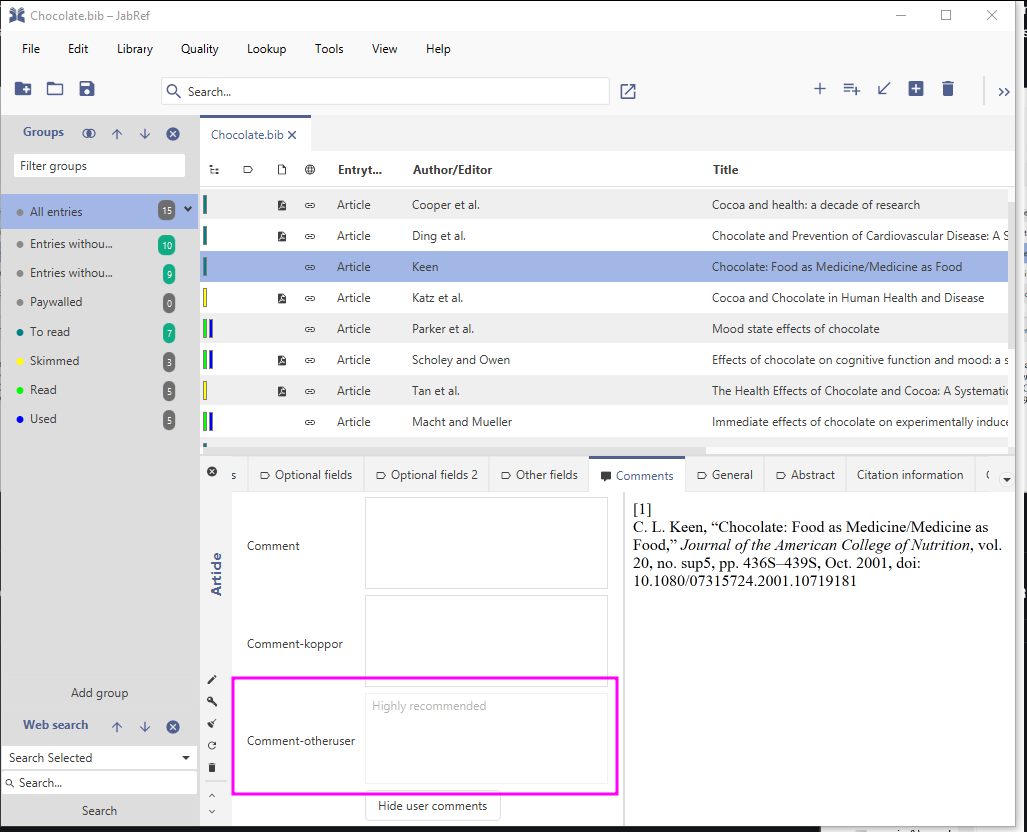
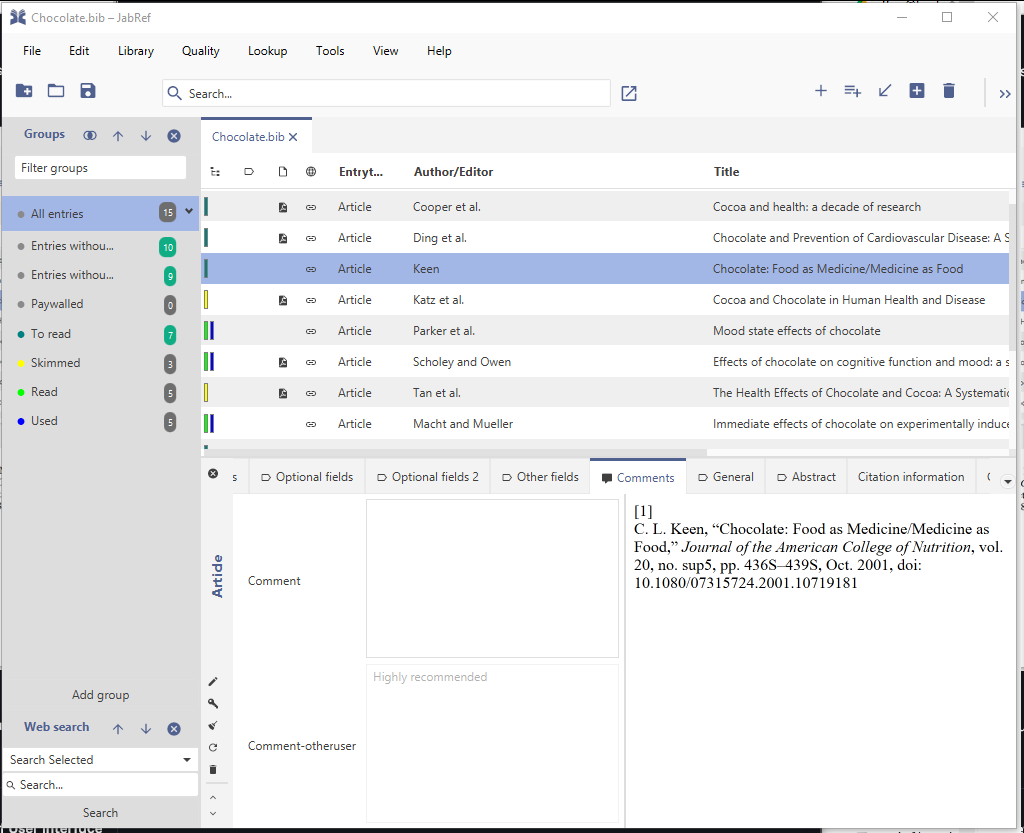
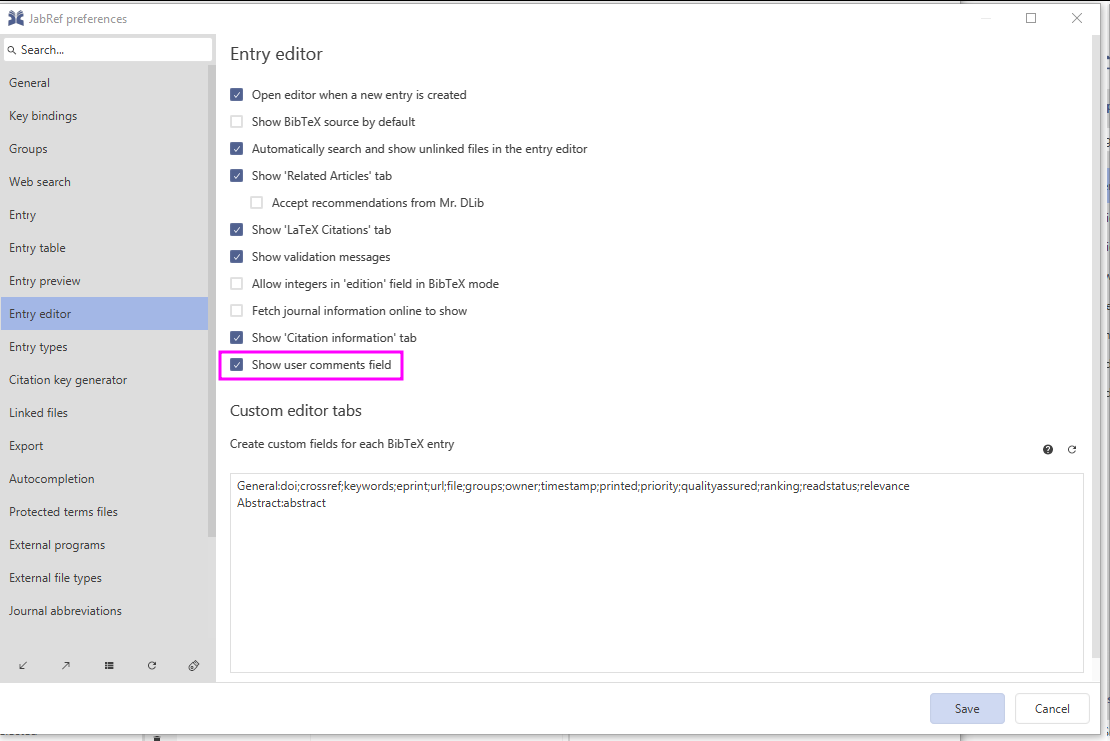
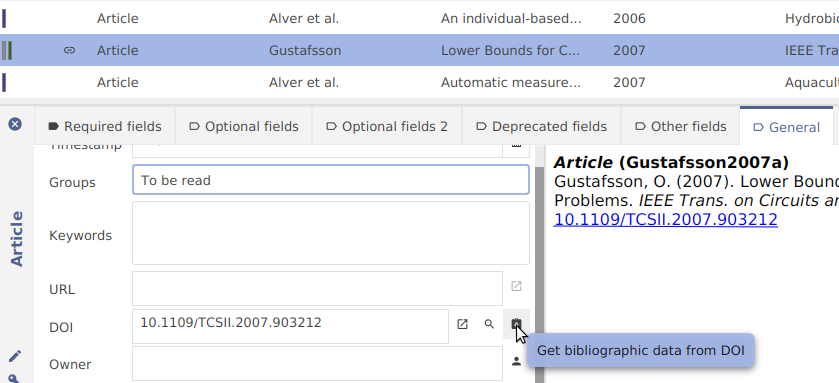
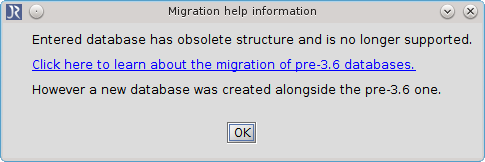
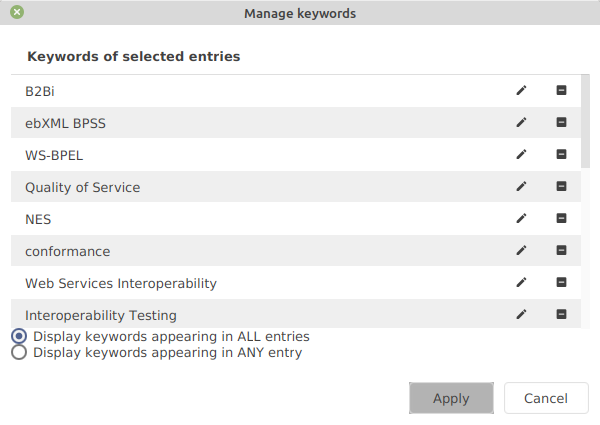
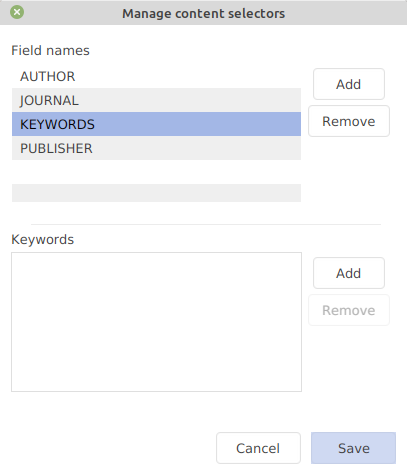

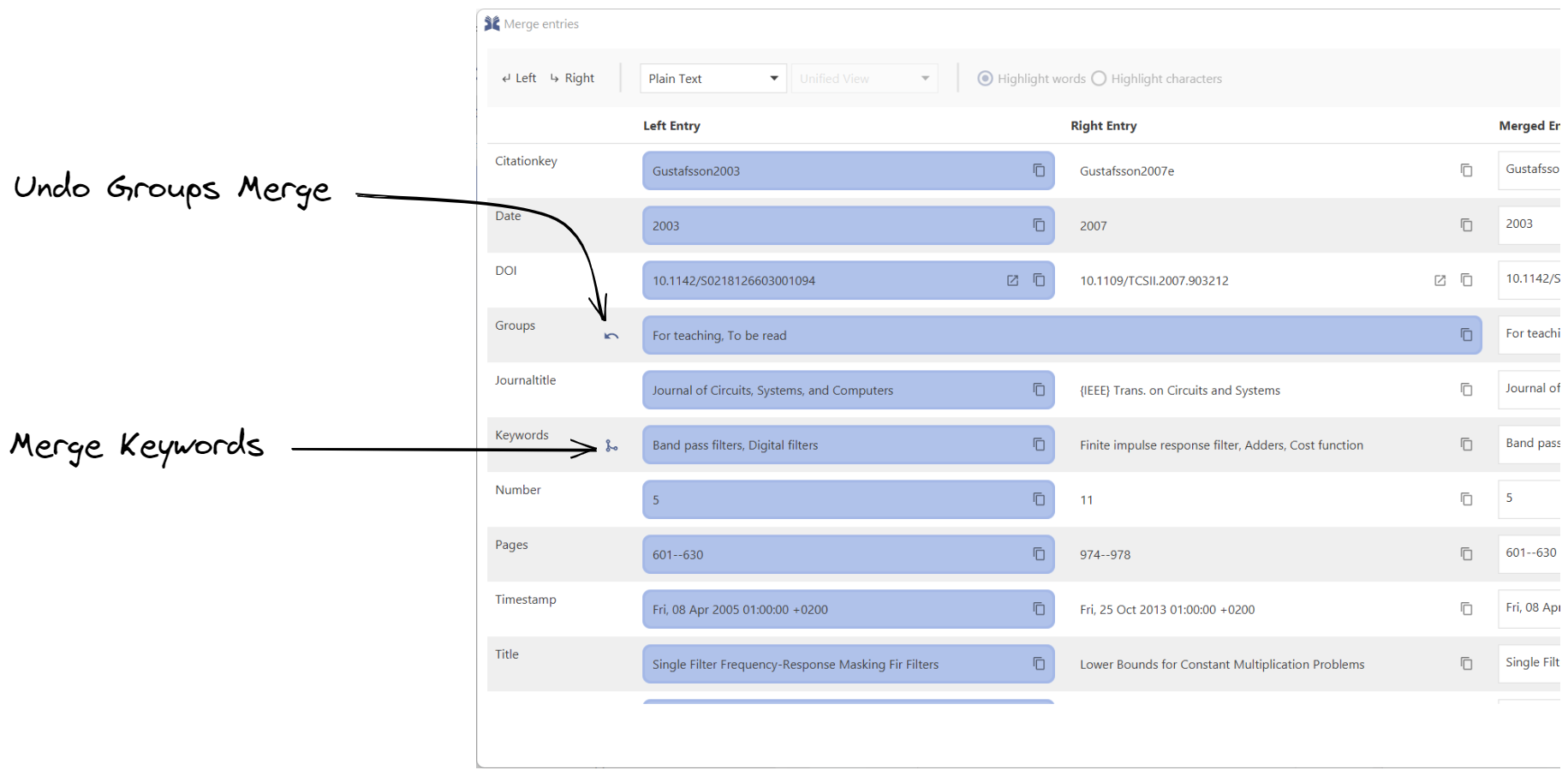
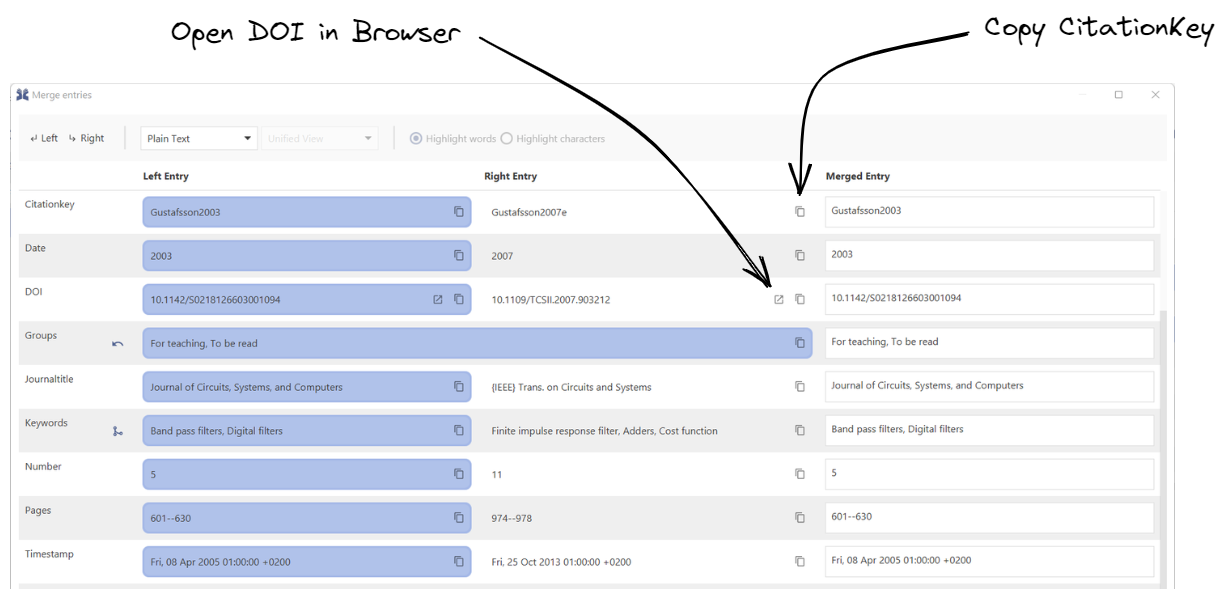
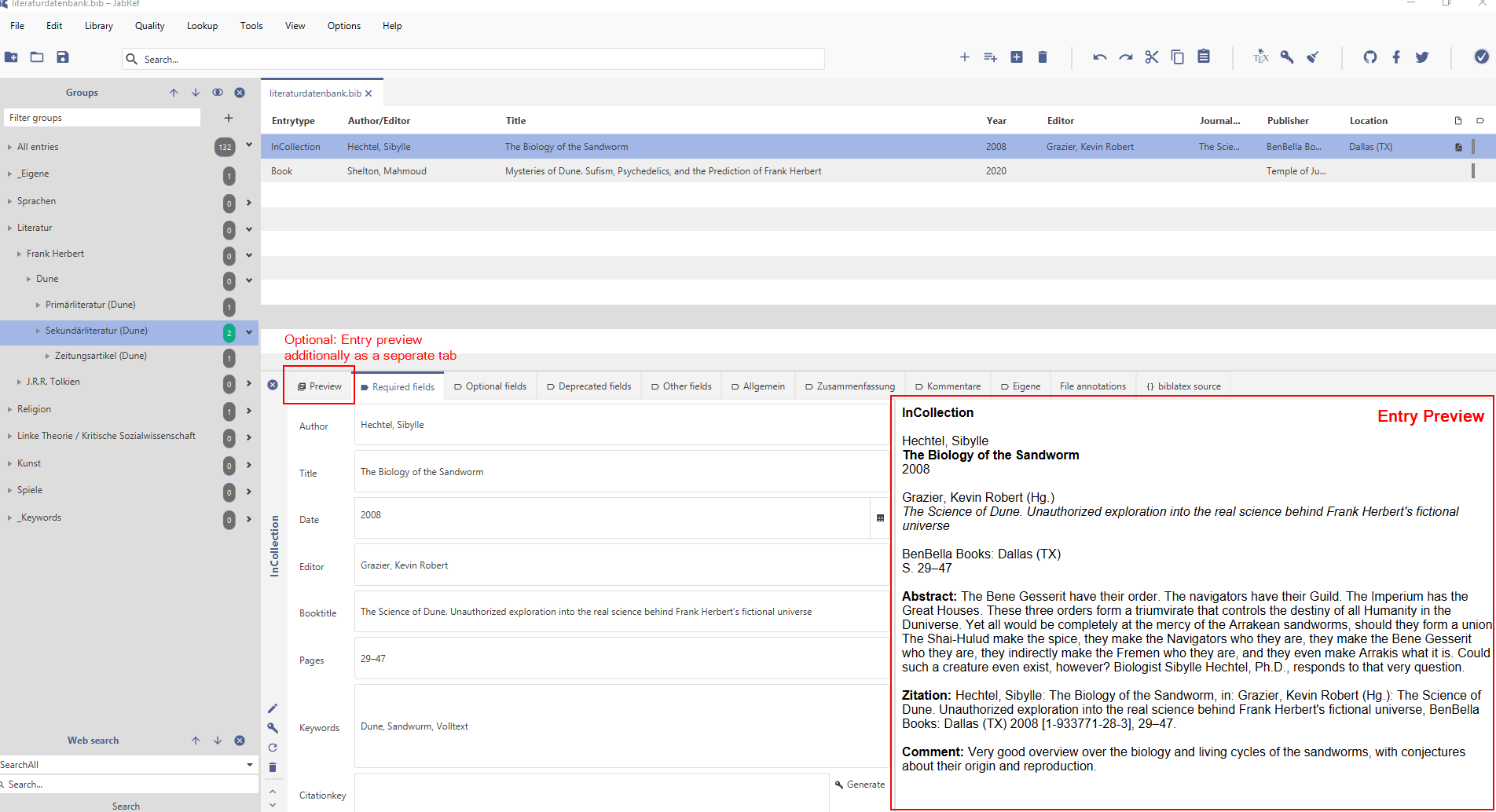
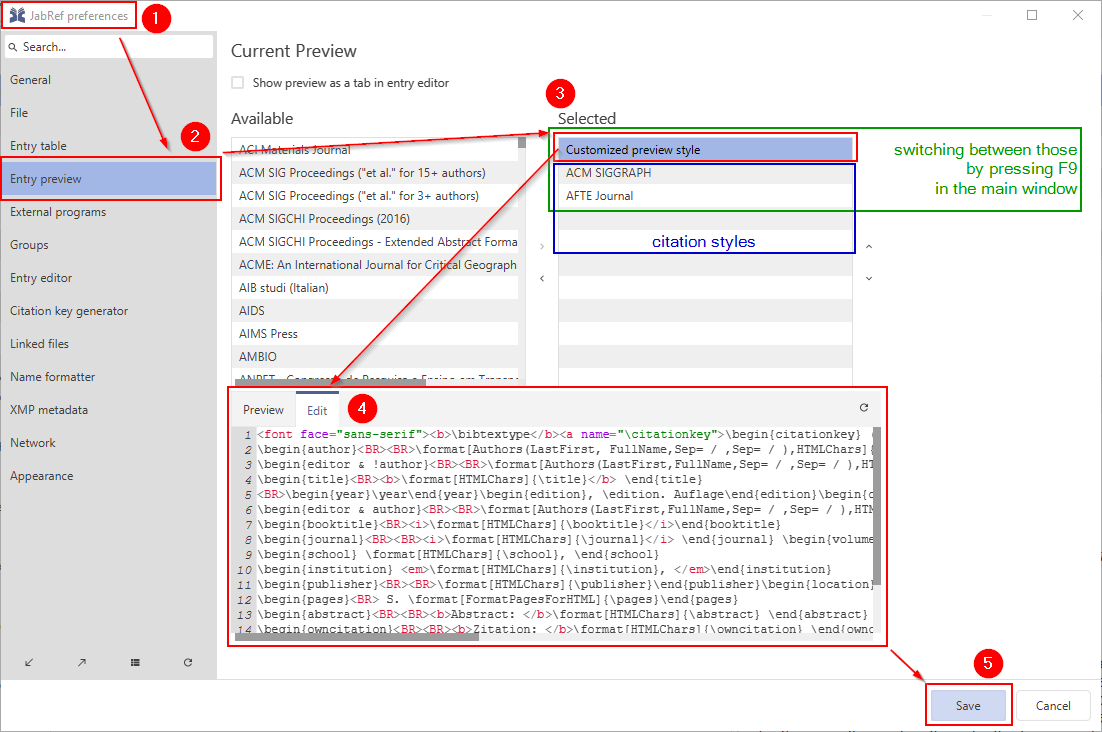
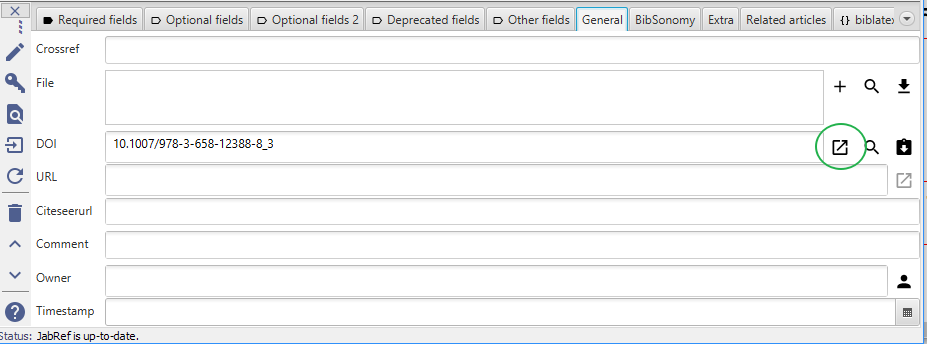
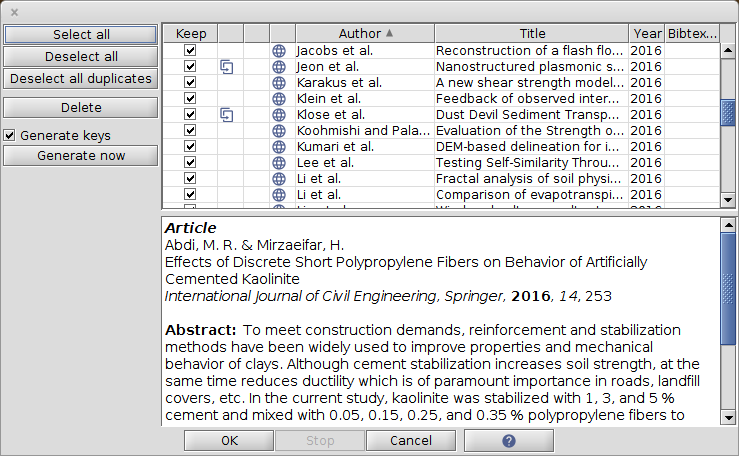
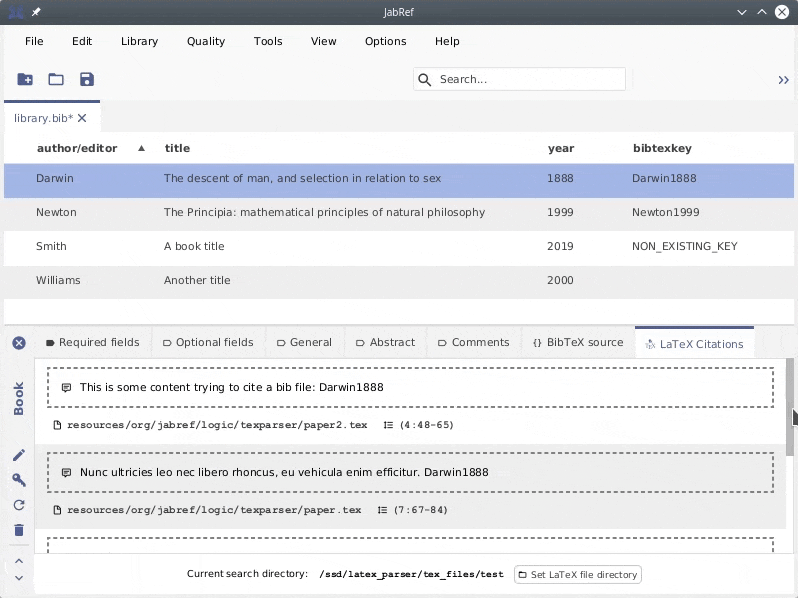
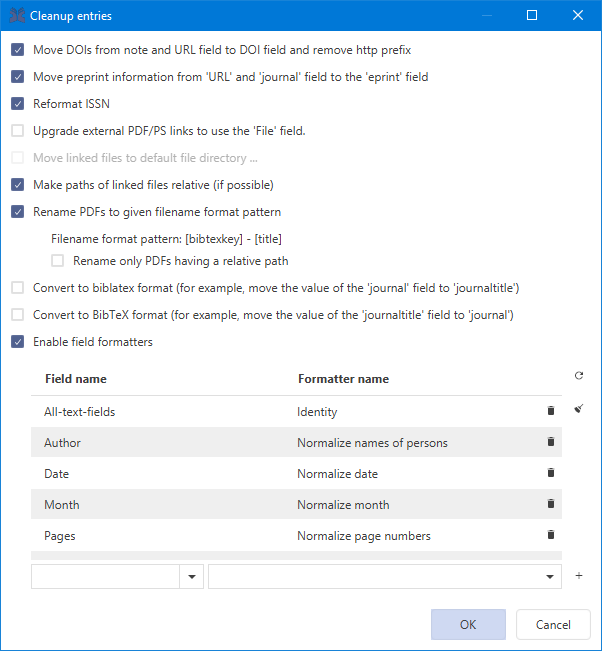
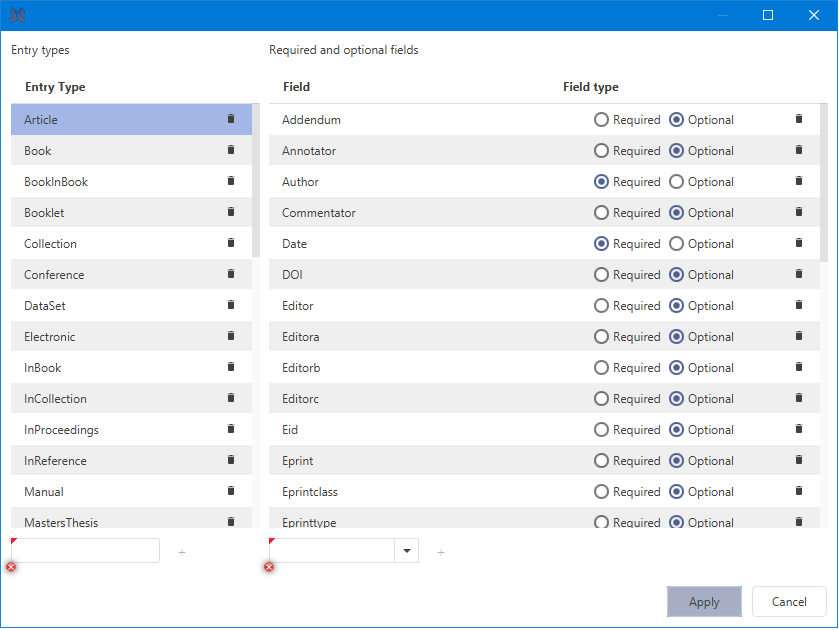
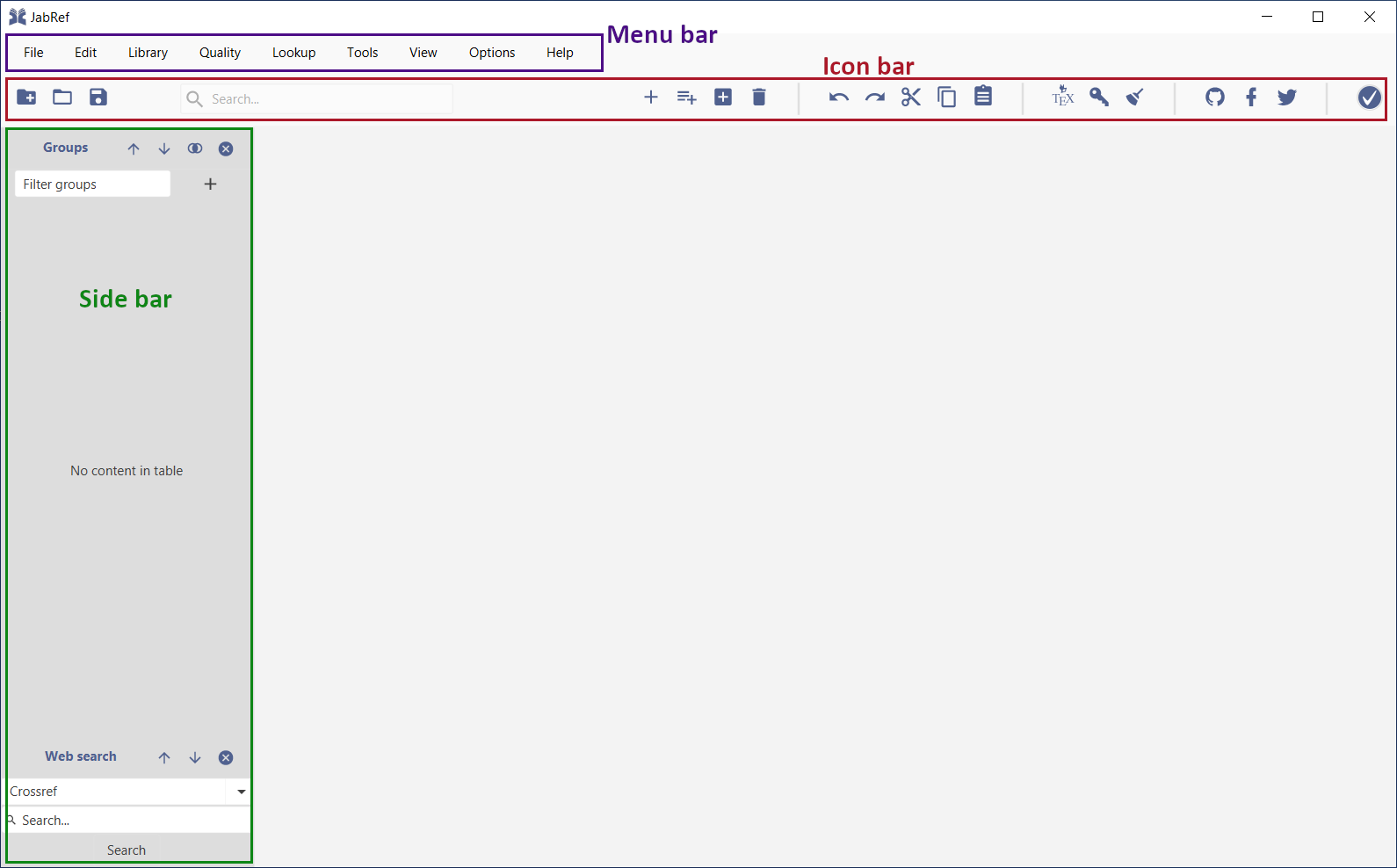
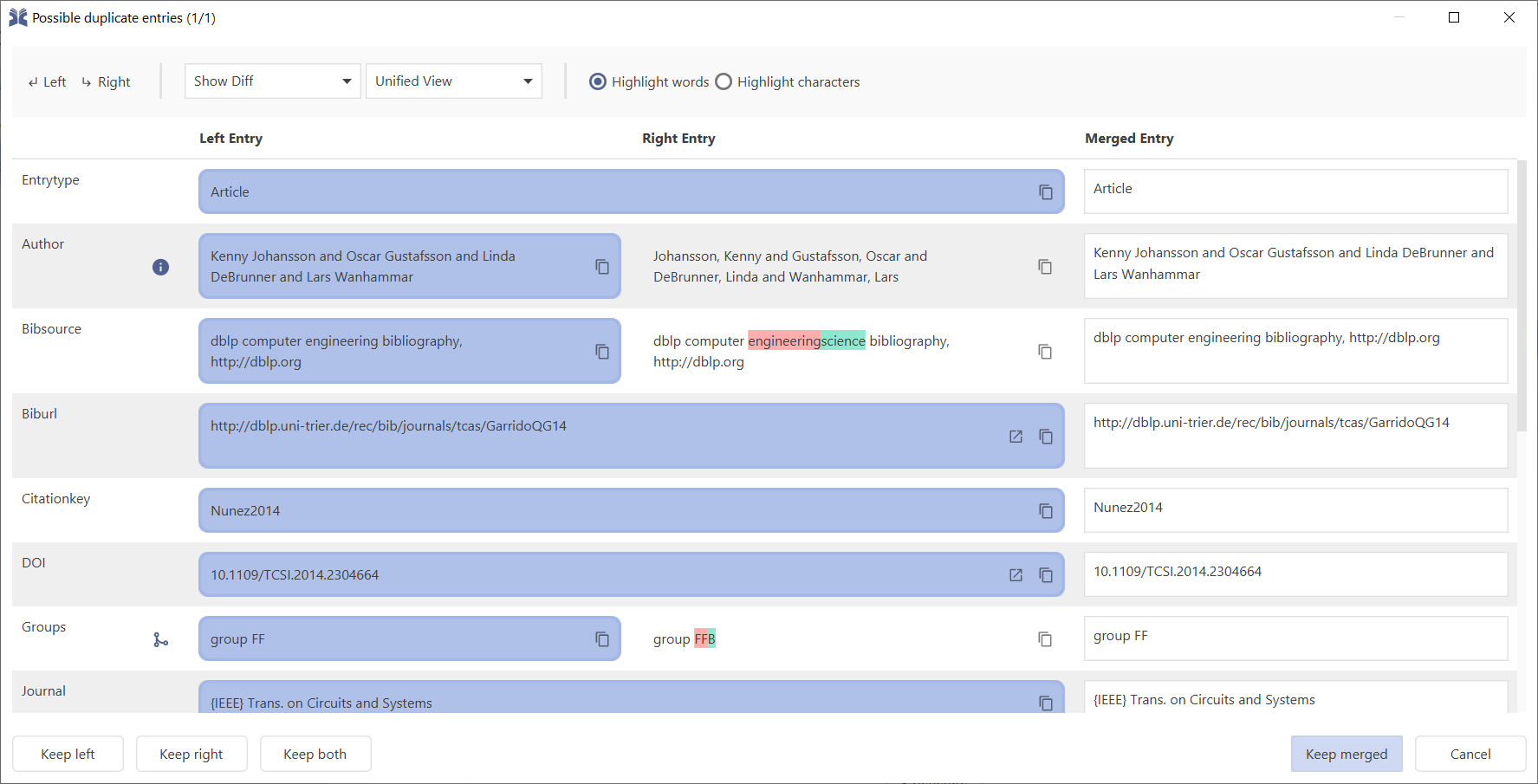
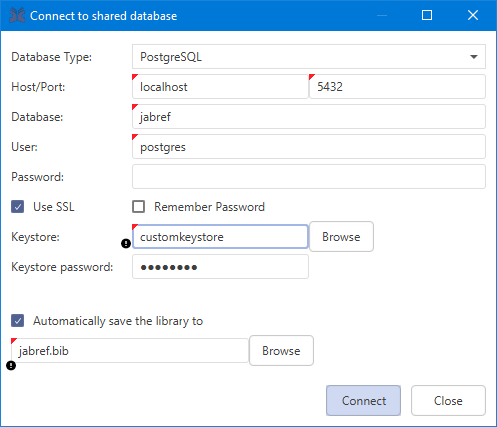
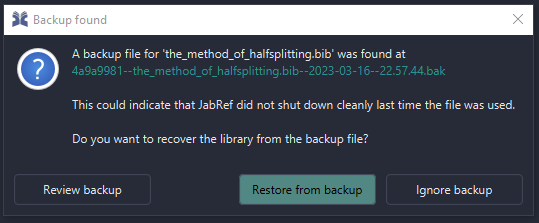
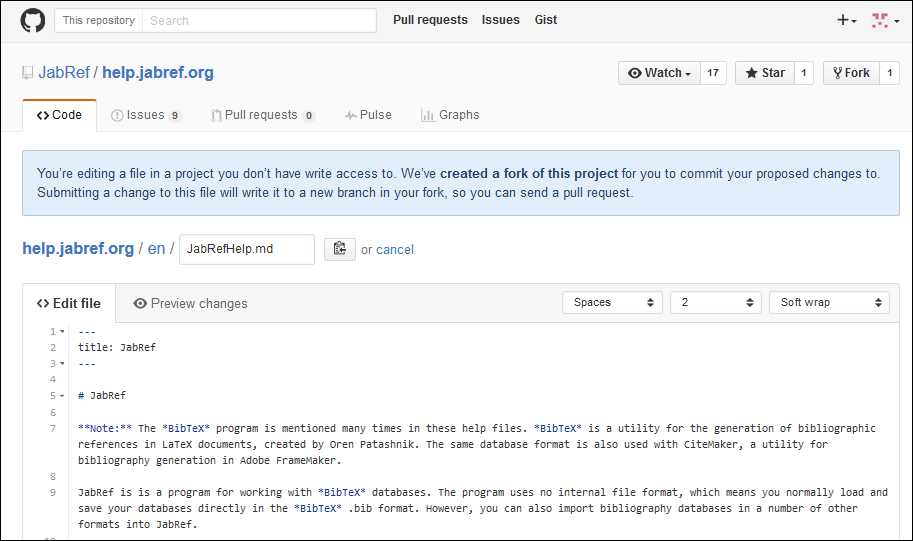
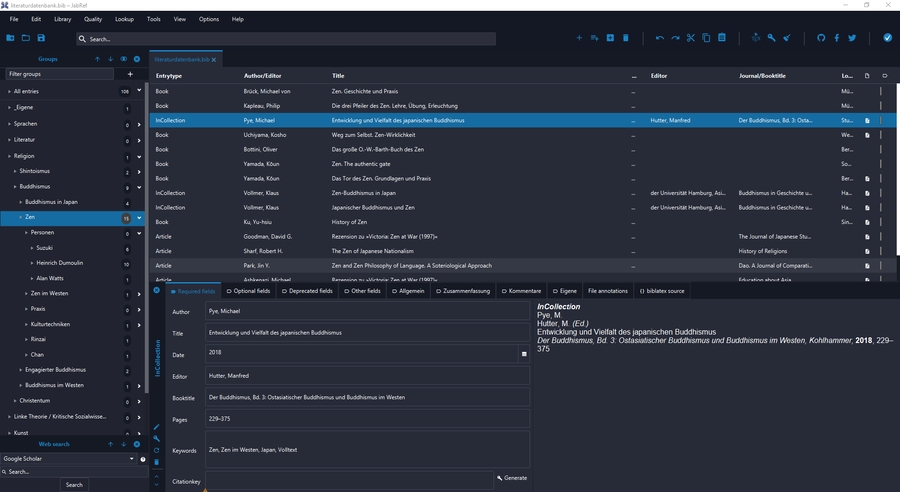

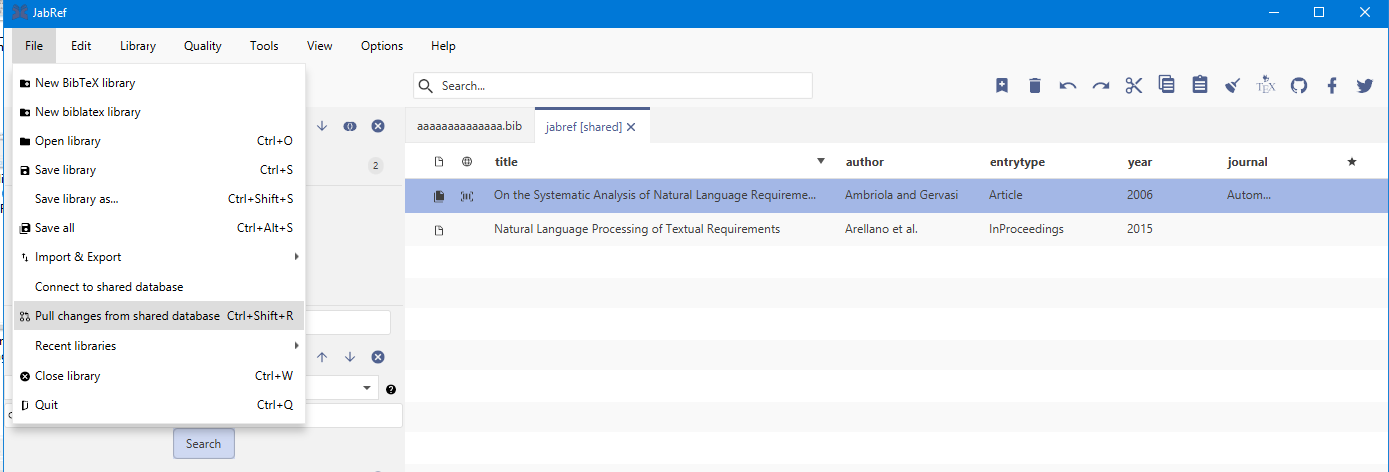
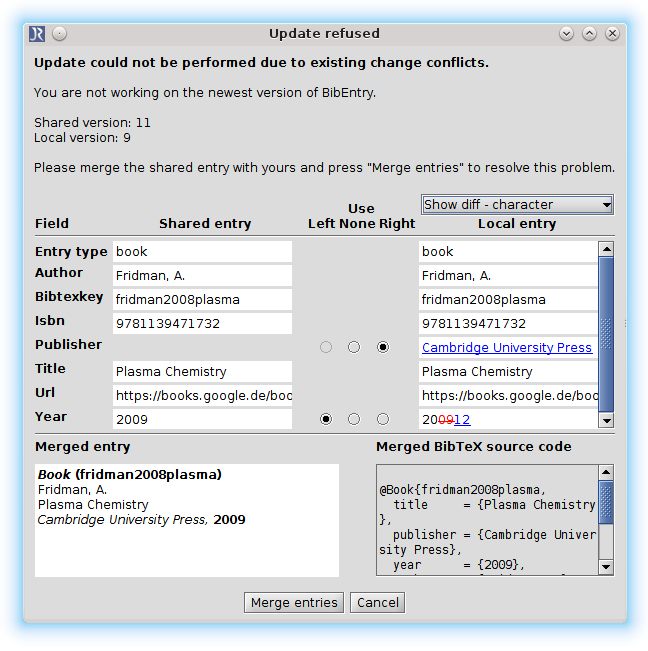
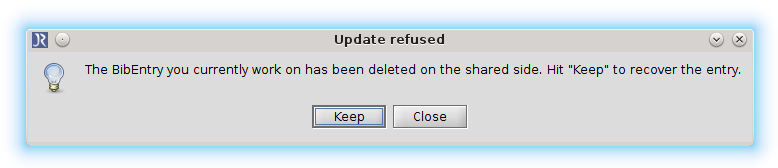
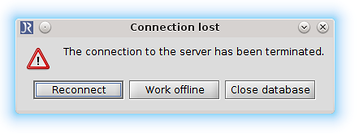

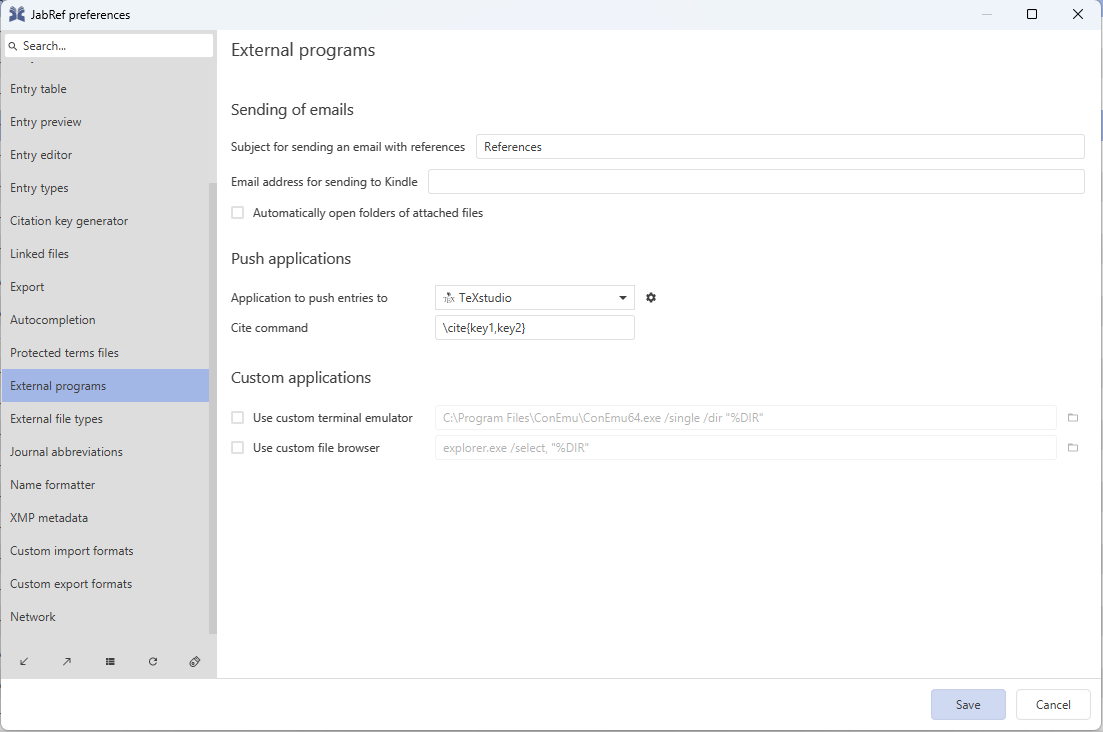

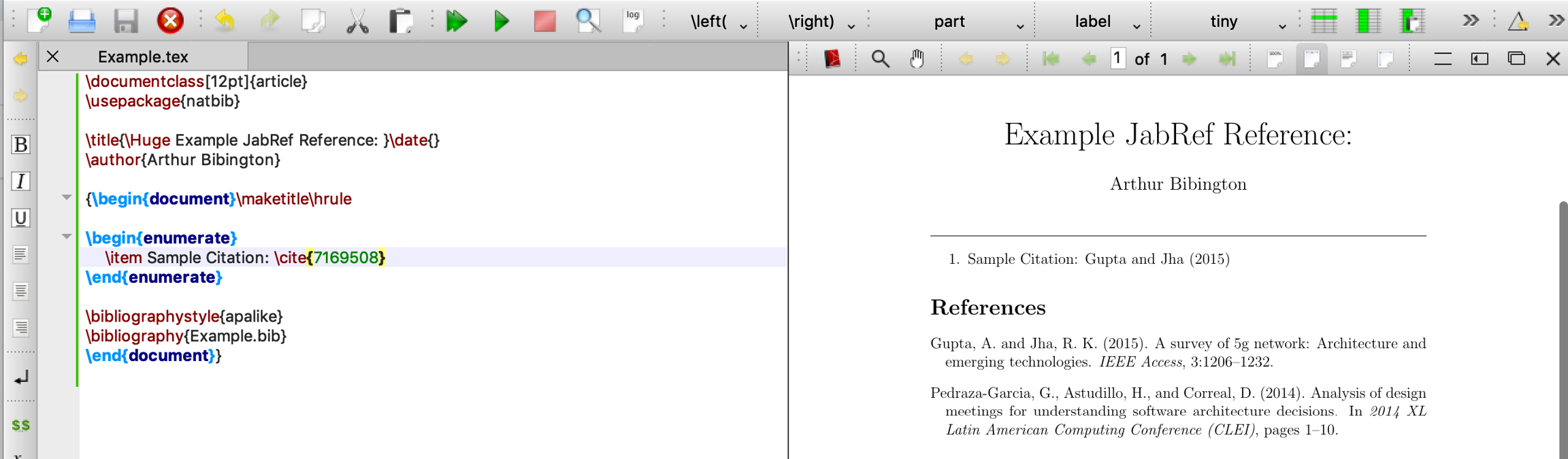
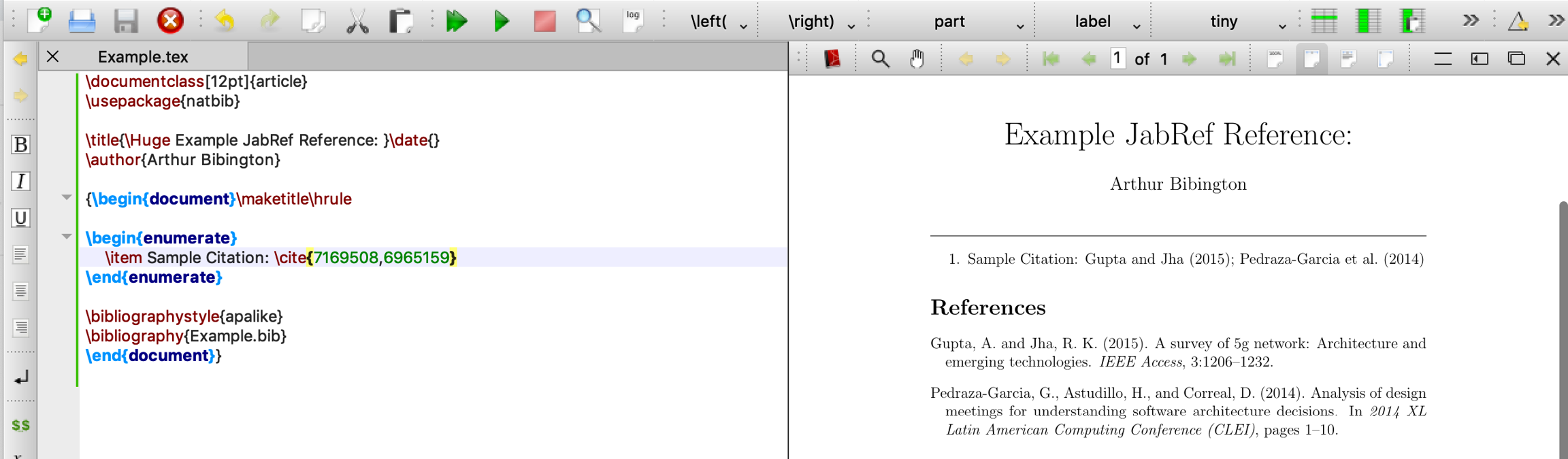
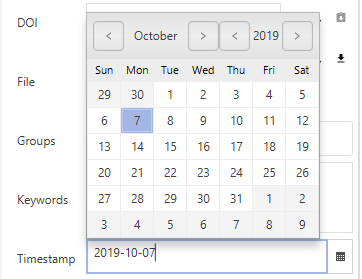
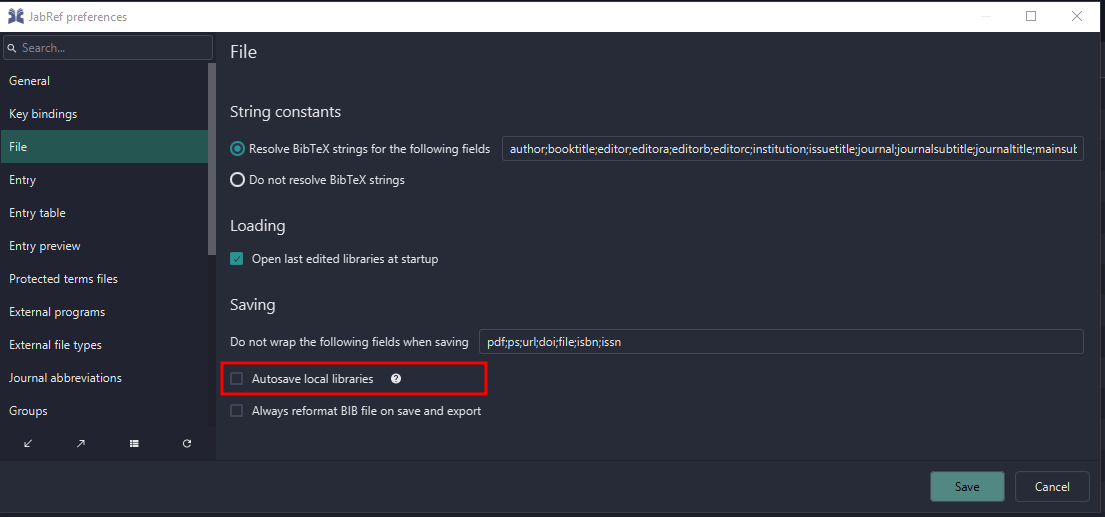
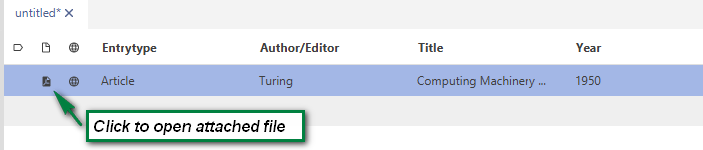
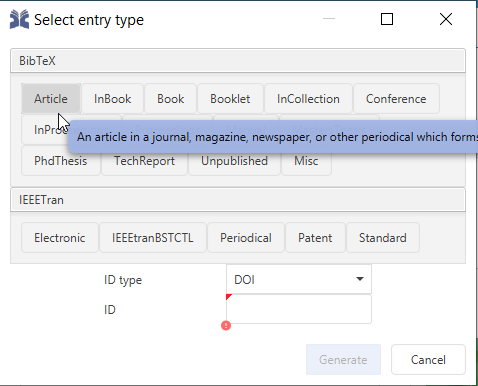
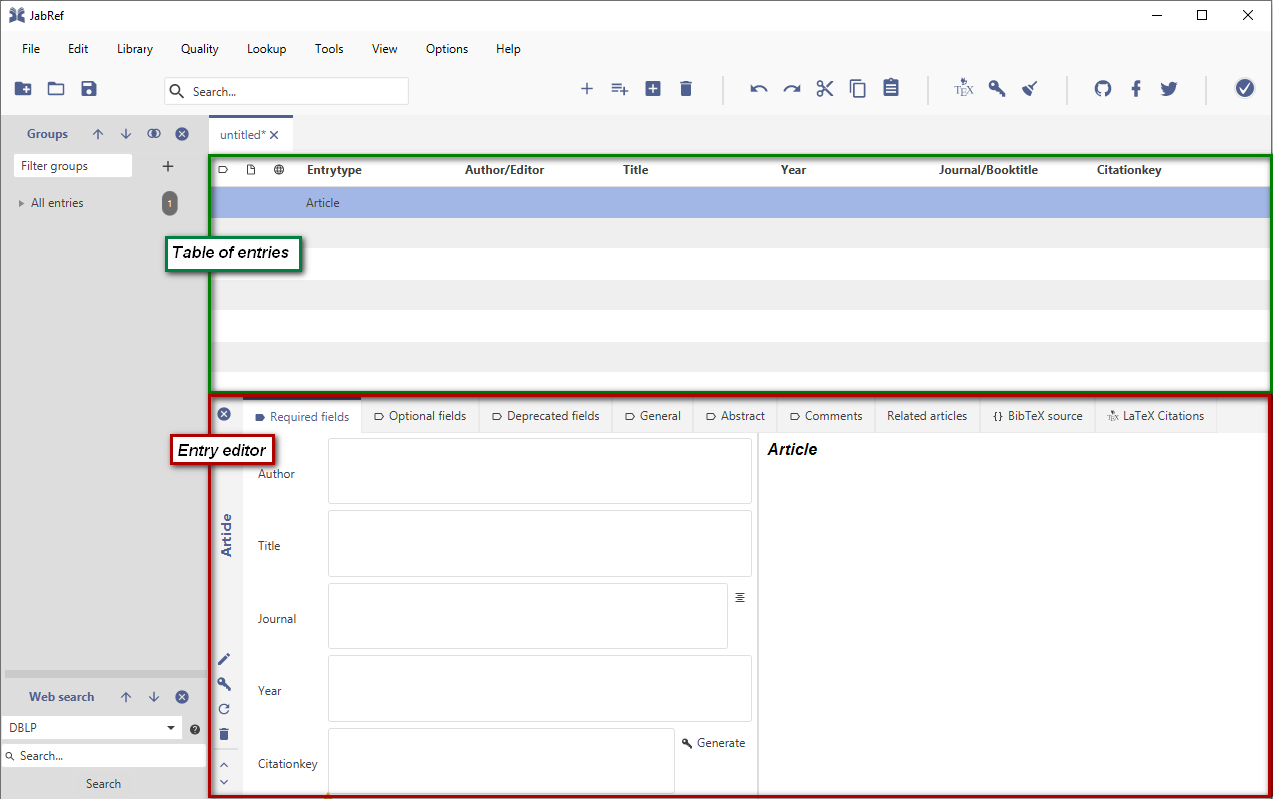
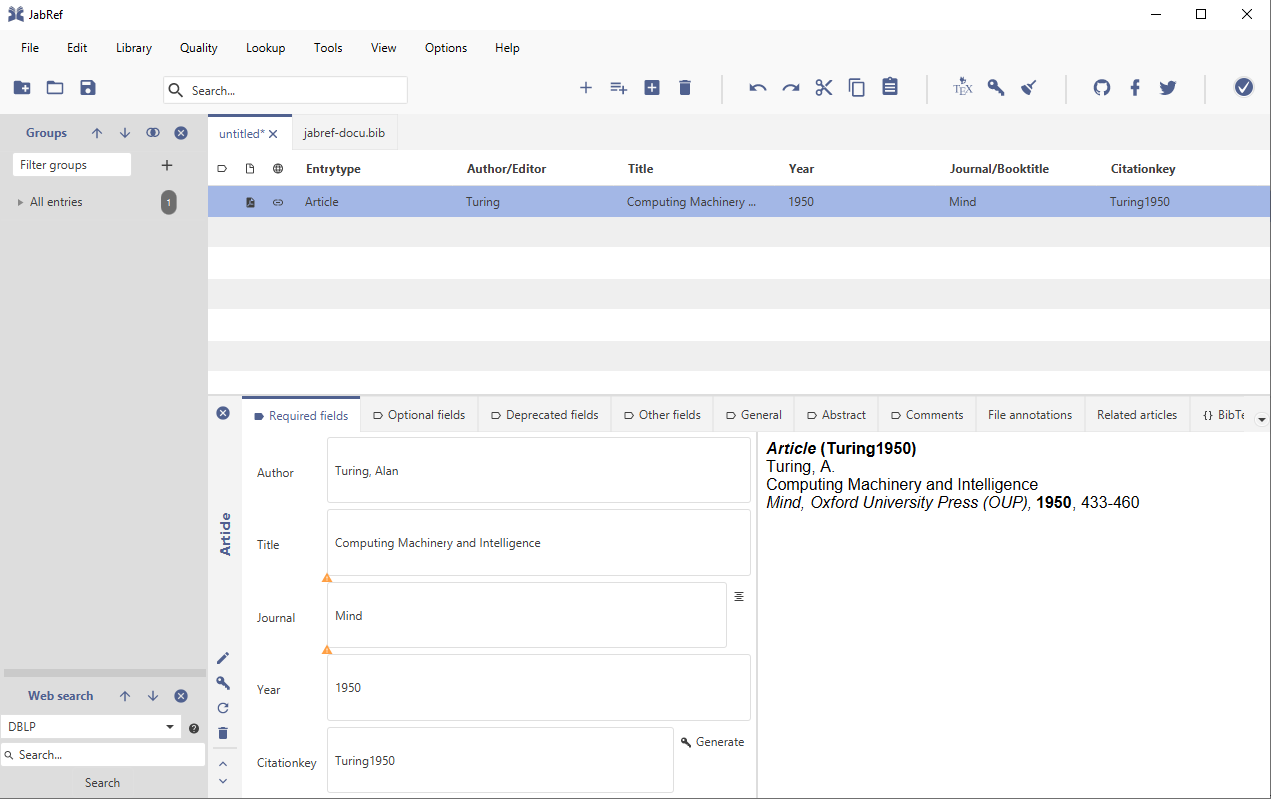
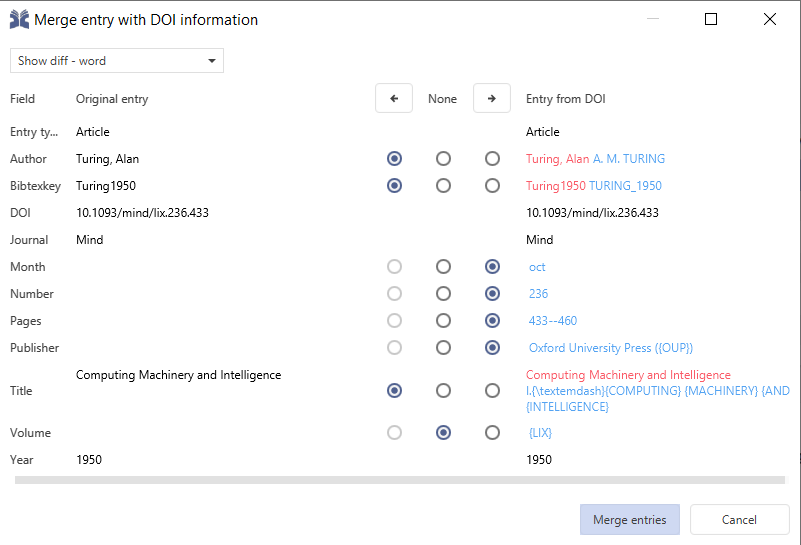
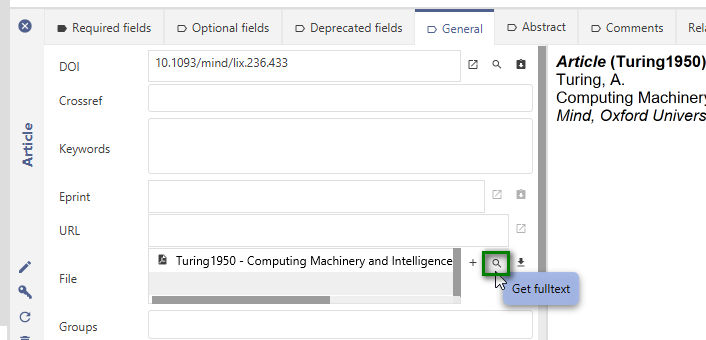
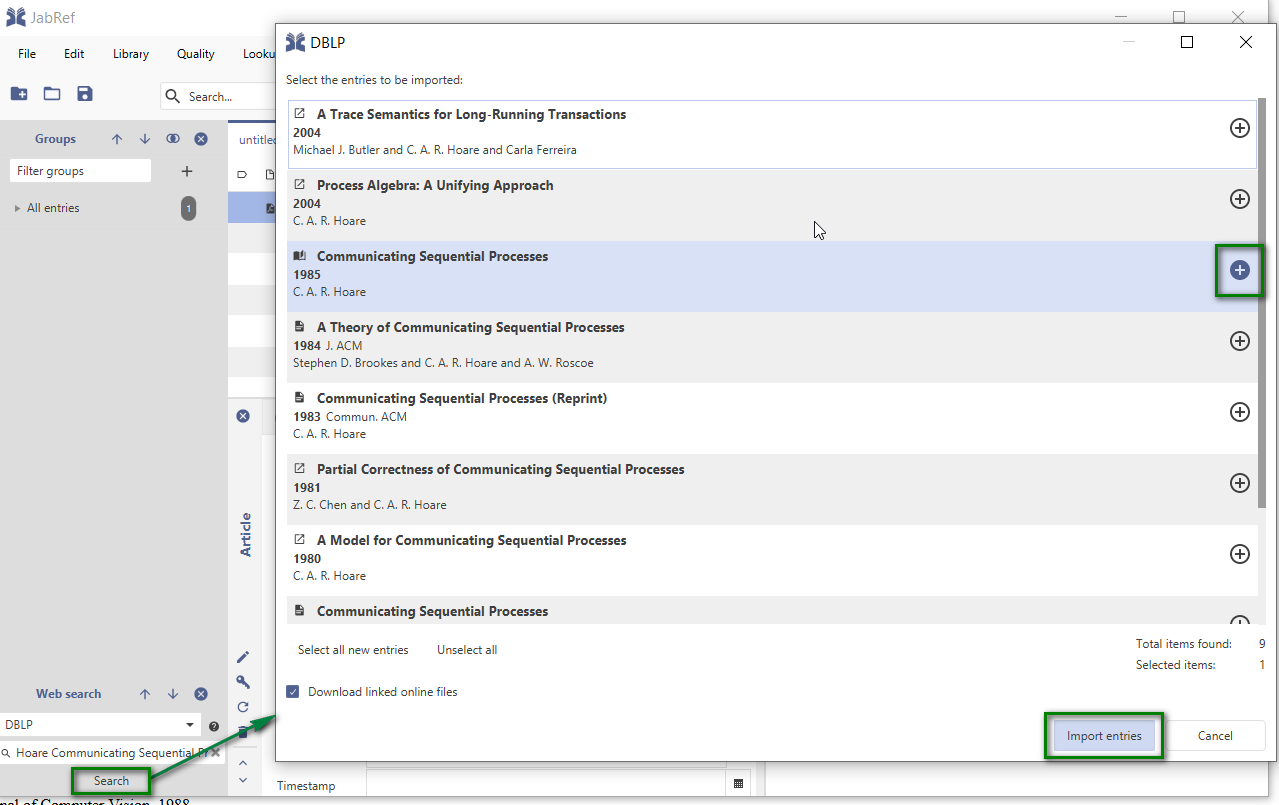
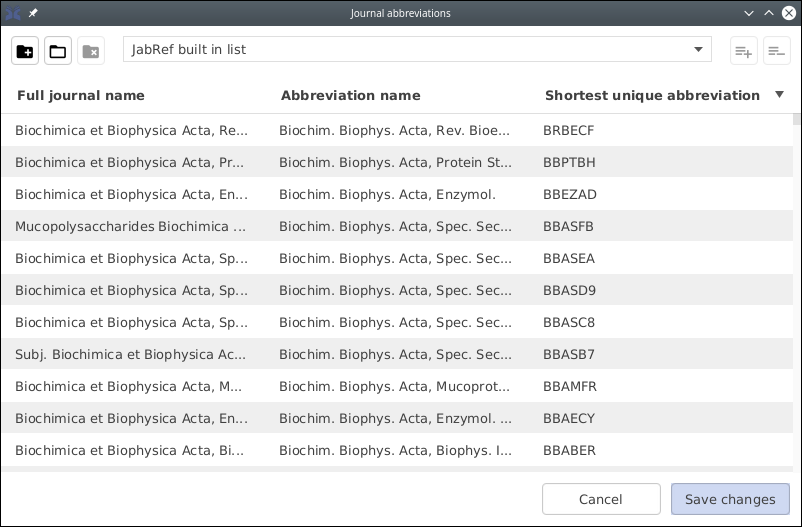
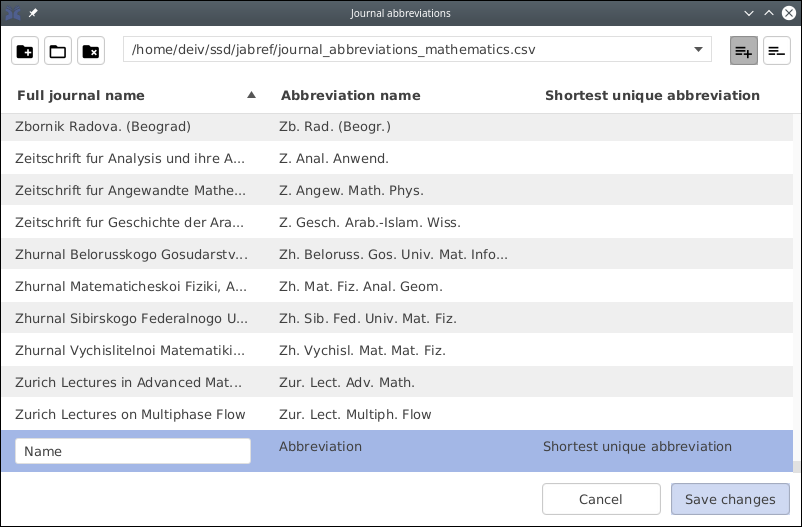
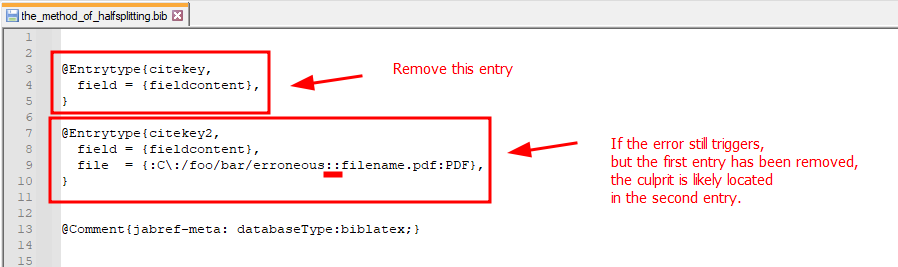

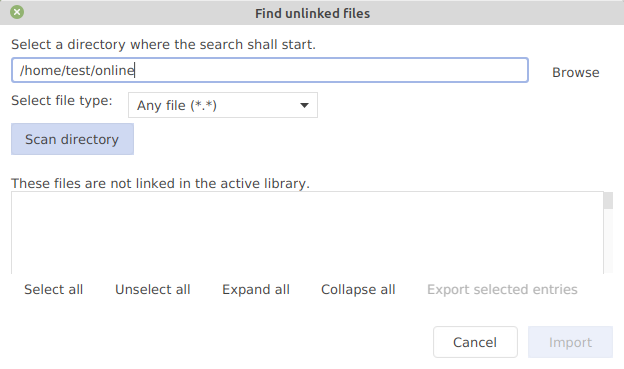
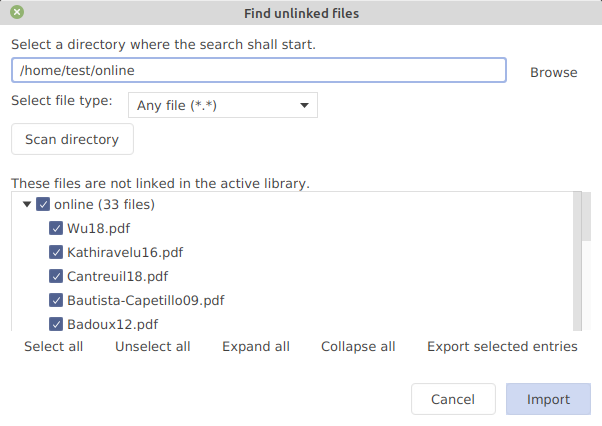
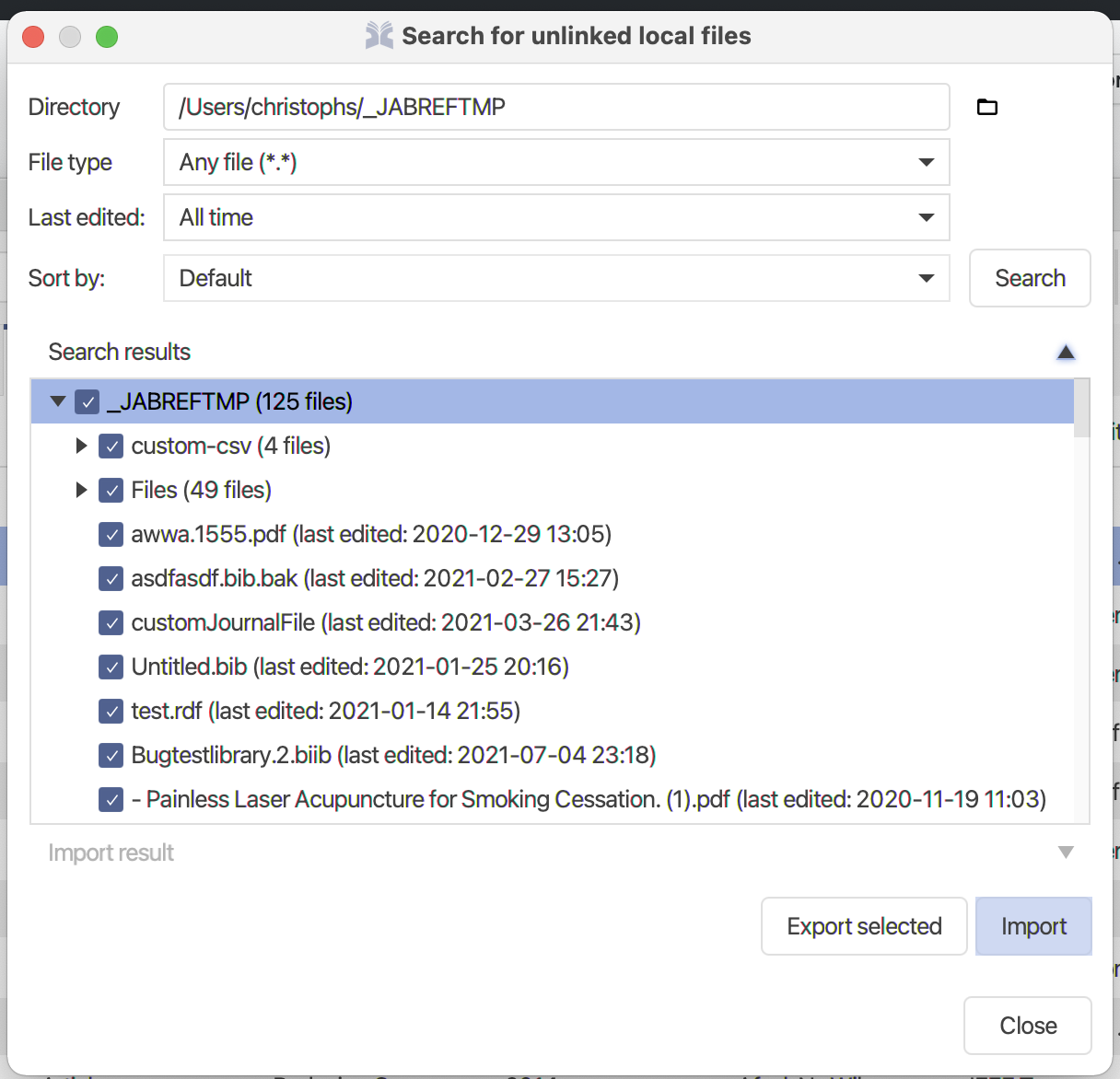
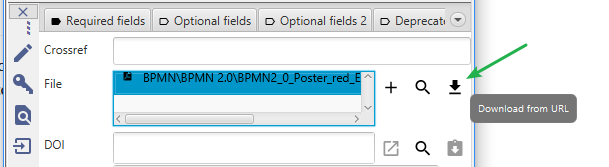

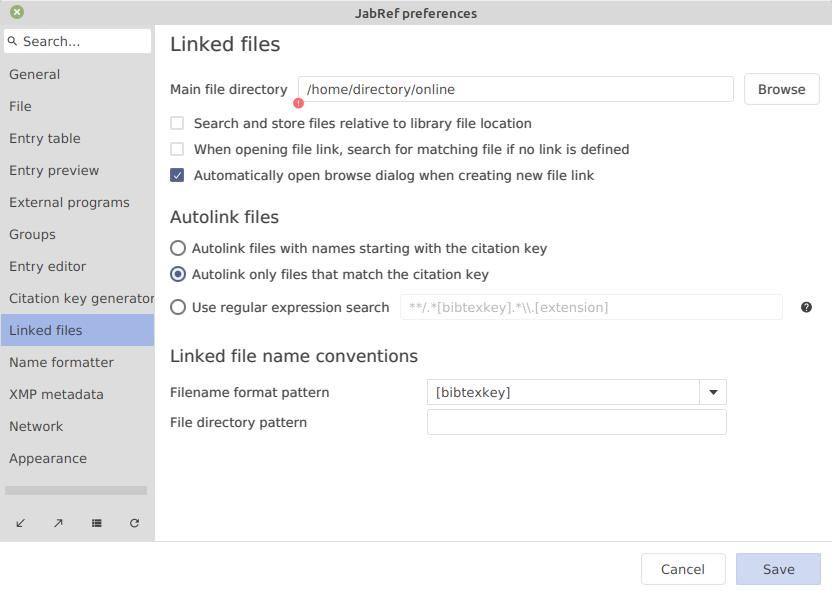
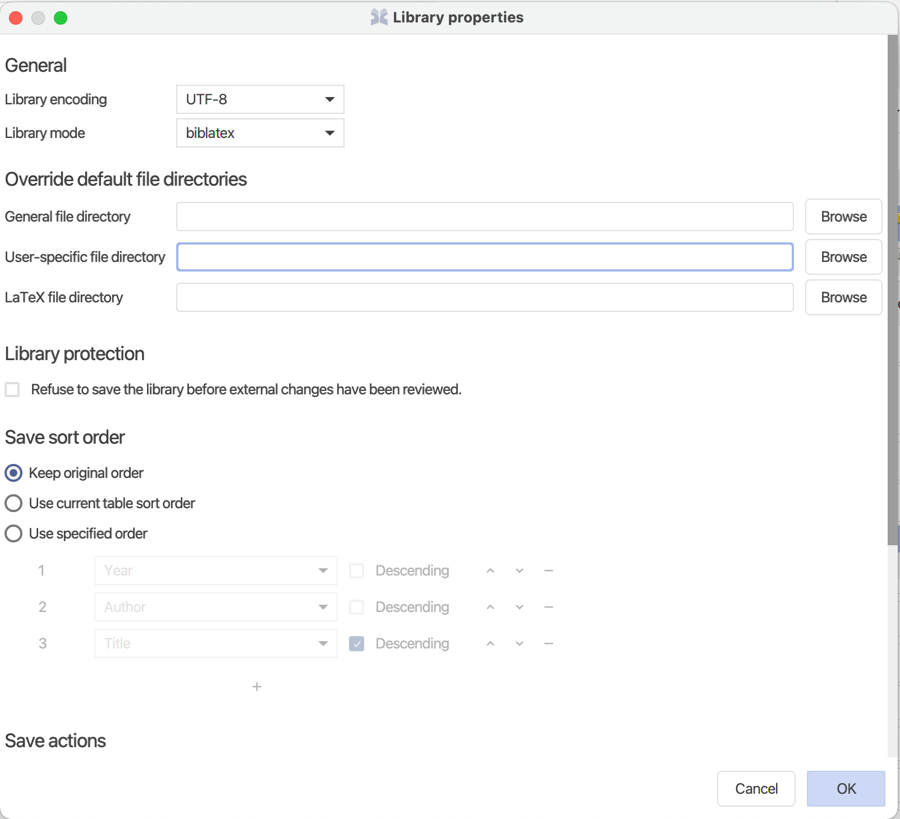

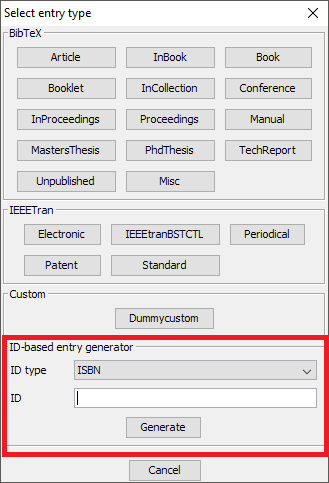
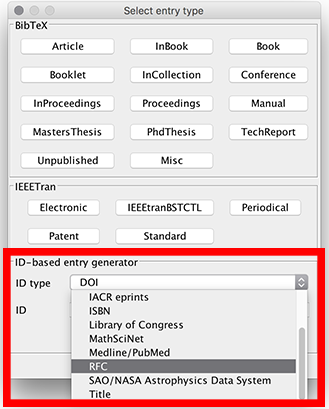
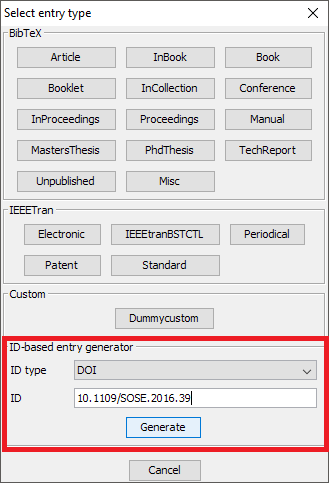
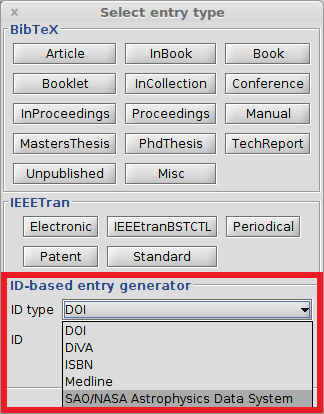
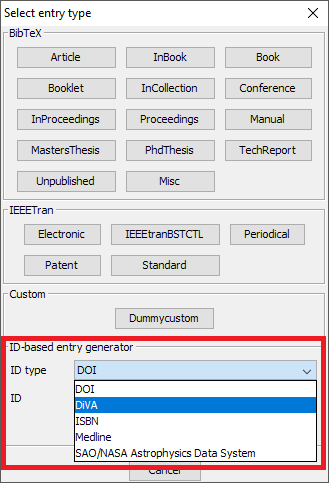
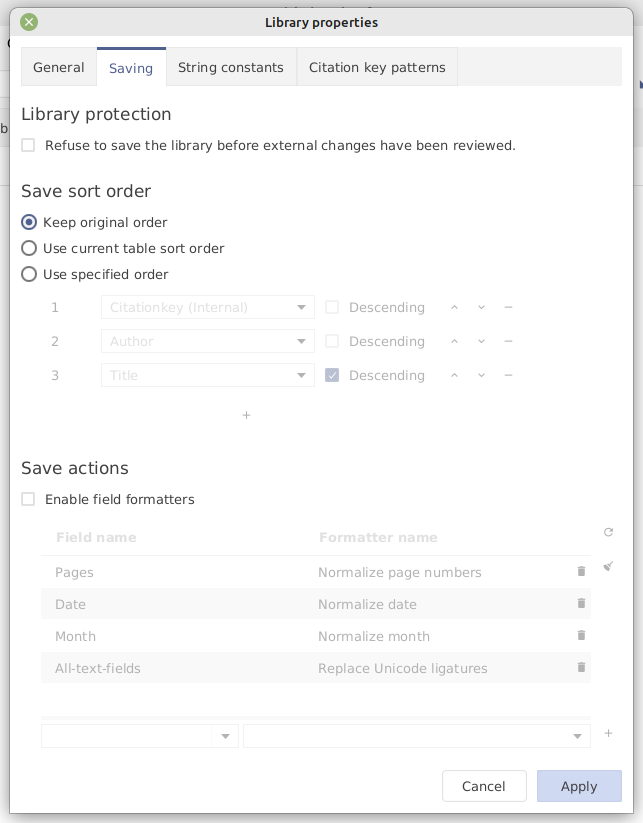




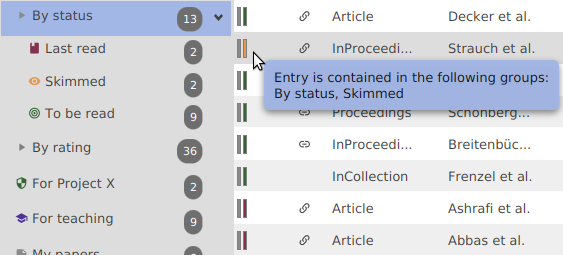

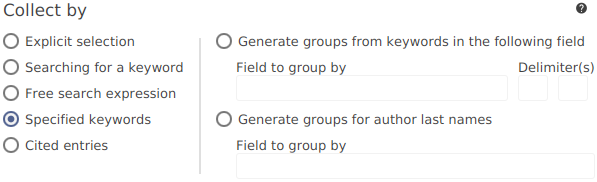
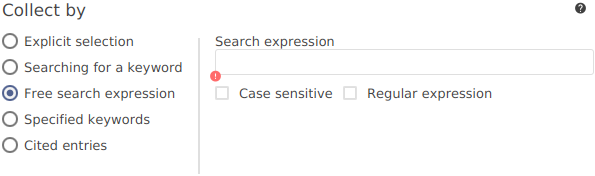
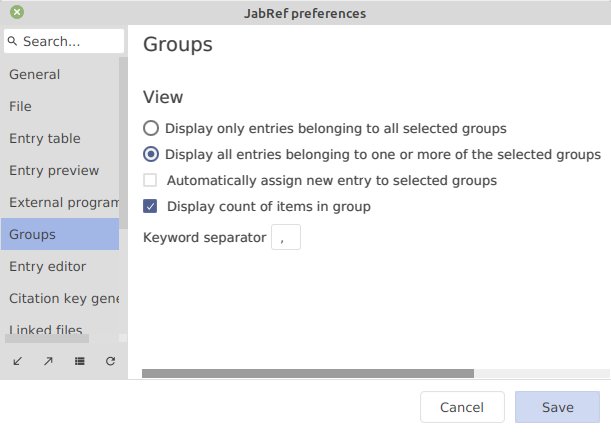
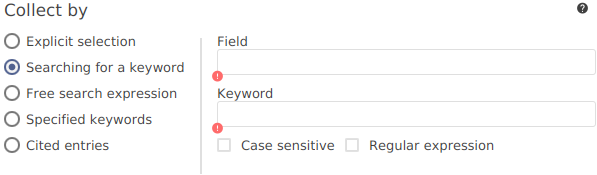
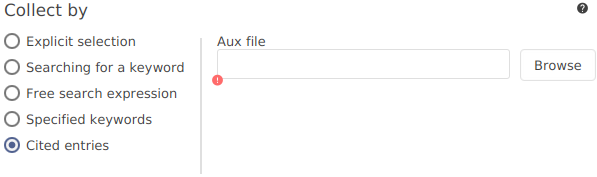


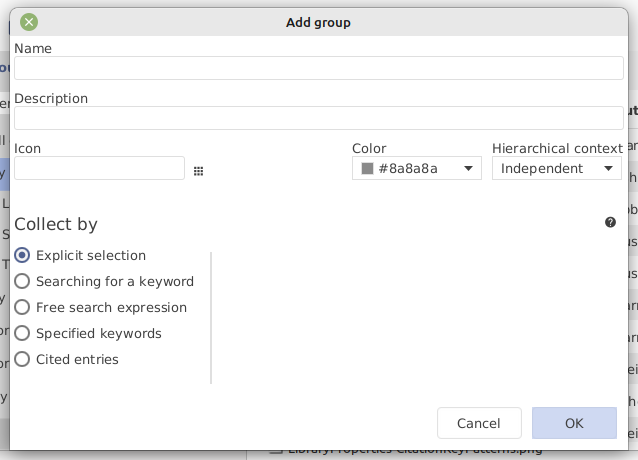
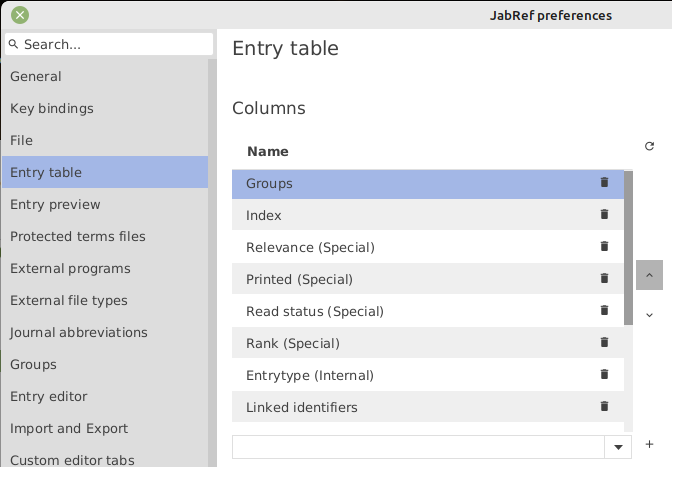
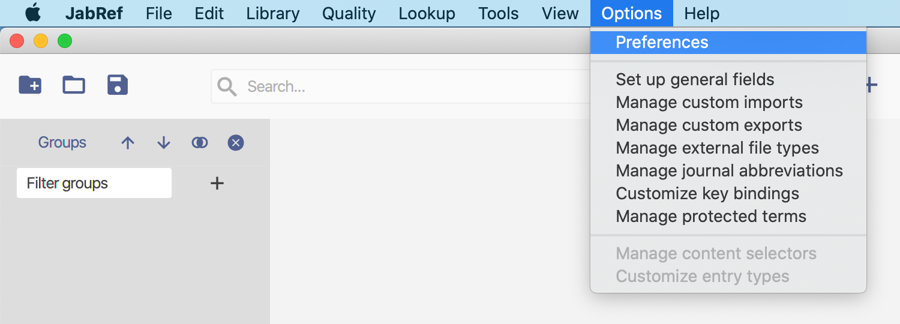
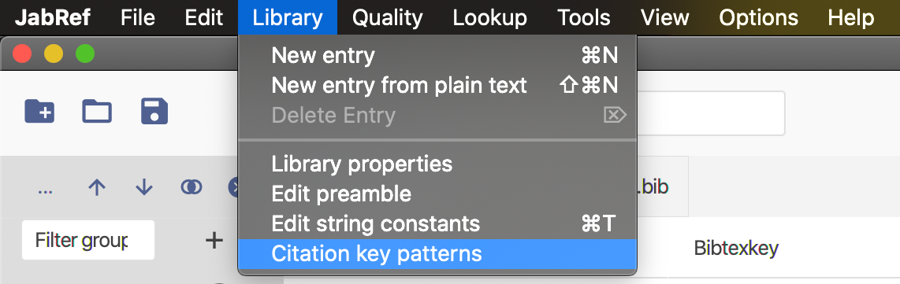
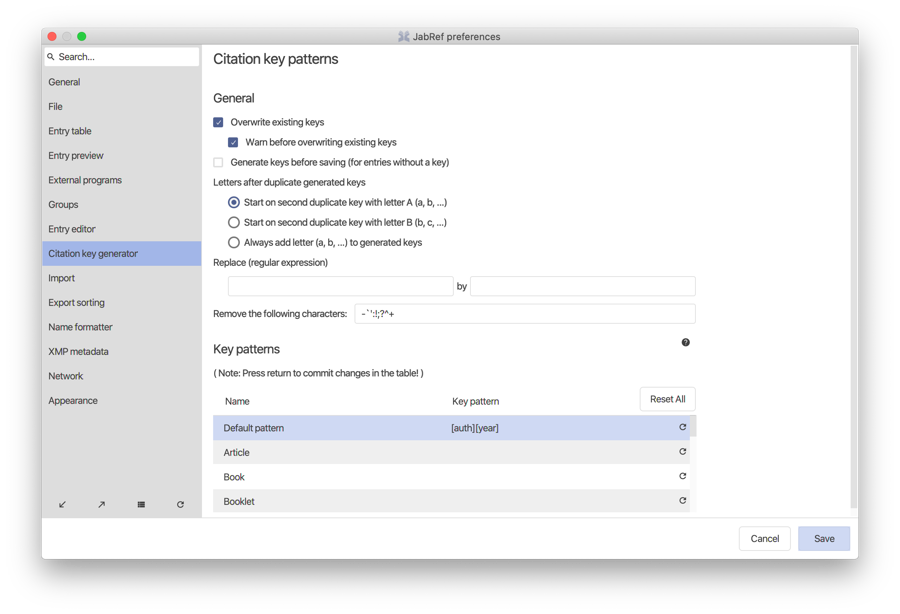



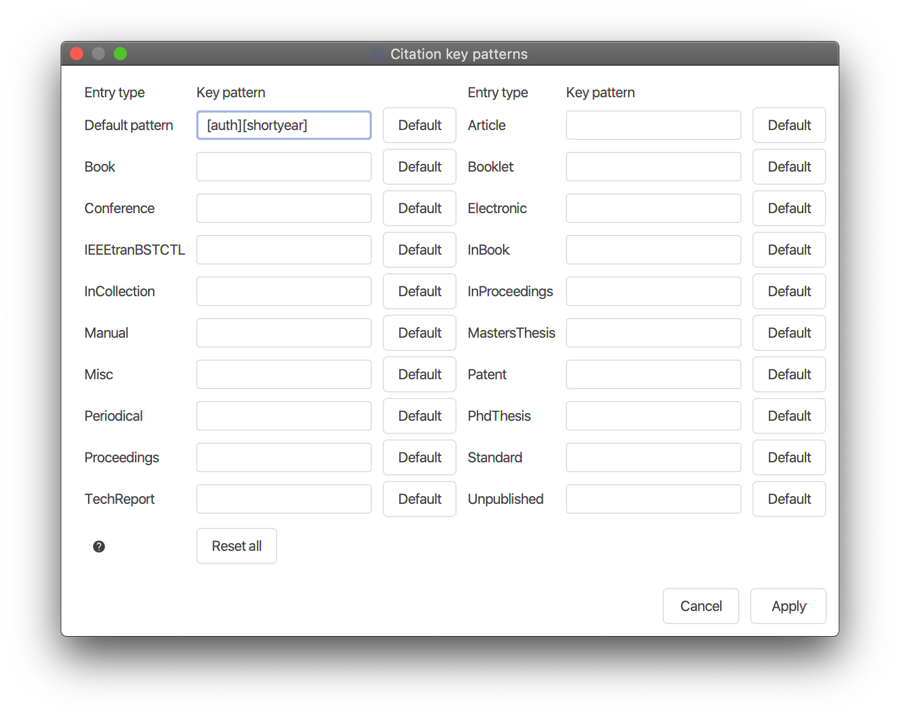
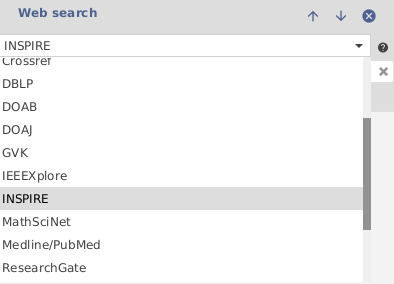
{kind=link}