Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
ArXiv is a repository of scientific preprints in the fields of mathematics, physics, astronomy, computer science, quantitative biology, statistics, and quantitative finance (Wikipedia).
To fetch entries from arXiv, choose Search → Web search, and the search interface will appear in the side pane. Select ArXiv.org in the dropdown menu. Enter the words of your query, and press Enter or the Fetch button.
The results are displayed in the import inspection window. In case an error occurs, it is shown in a popup.
How to find, sort, and clean entries
Since: 3.7
Medline is a bibliographic database of life sciences and biomedical information. It includes bibliographic information for articles from academic journals covering medicine, nursing, pharmacy, dentistry, veterinary medicine, and health care. Medline also covers much of the literature in biology and biochemistry, as well as fields such as molecular evolution (Wikipedia).
To use this feature, choose BibTeX → New entry.... In the lower part, there is the box "ID-based entry generator". In the field "ID type", "Medline" can be selected (see screenshot below). Select the field "ID" and enter the Medline ID here (e.g., 27934767) and press Enter to generate an entry based on the Id. You can also click on "Generate". The found entry is opened in an entry editor. In case an error occurs, a popup is shown.
The ACM Portal includes two databases (Wikipedia):
the ACM Digital Library is a text collection of every article published by the Association for Computing Machinery, including over 60 years of archives
from articles, magazines and conference proceedings.
the Guide to Computing Literature that is a bibliographic collection from major publishers in computing with over one million entries.
To fetch entries from ACM, choose Search → Web search, and the search interface will appear in the side pane. Select ACM portal in the dropdown menu. You may choose which database to search and you may opt to download the abstracts along with the cite information for each entry, by checking the Include abstracts checkbox. To start a search, enter the words of your query, and press Enter or the Fetch button.
Frequent connections to ACM Portal may get your IP banned for hours. To avoid this, JabRef will display a preview (for each search) of the first page of entries returned by the server. You can then choose which entries to download.
Then, the results are displayed in the import inspection window.
JabRef can help you merging entries of your database.
First, select the two entries to be merged. Then select the menu Quality → Merge entries.... The Merge entries window will pop-up.
The fields of the two entries are displayed side-by-side on the upper part of the window.
The differences between the two entries can be emphasized through the drop-down menu located at the upper right-hand corner of the window. Five ways of displaying the differences are offered:
plain text: as is, no emphasis
show diff - word: differences are shown in the right entry. Full words are struck out in red if they are removed from the left entry or underlined in blue if they are added to the right entry.
show diff - character: differences are shown in the right entry. Individual characters are struck out in red or underlined in blue as above.
show symmetric diff - word: differences are shown on both sides. Words are underlined and displayed in color.
show symmetric diff - character: differences are shown on both sides. Characters are underlined and displayed in color.
In the central column, a radio button allows you to select which side to keep for each field: the left side, the right side, or none. By default, the left entry is kept, and any fields not present in the left entry are obtained from the right entry.
Based upon your selection, the merged entry is shown, both as a preview (on the left) and as source code (on the right).
If you right-click on the preview, you can Print entry preview or Copy preview.
Finally, after selecting which fields to keep, you can decide to Merge entries. Alternatively, you can press Cancel.
See also: Find duplicates
is a public search engine for scientific and academic papers primarily with a focus on computer and information science. However, CiteSeerX has been expanding into other scholarly domains such as economics, physics and others ().
To fetch entries from CiteSeerX, choose Search → Web search, and the search interface will appear in the side pane. Select CiteSeerX in the dropdown menu. To start a search, enter the words of your query, and press Enter or the Fetch button.
The results are displayed in the . In case an error occurs, it is shown in a popup.
DBLP is a computer science bibliography website listing more than 3.1 million journal articles, conference papers, and other publications on computer science (Wikipedia).
To fetch entries from DBLP, choose Search → Web search, and the search interface will appear in the side pane. Select DBLP in the dropdown menu. To start a search, enter the words of your query, and press Enter or the Fetch button.
The results are displayed in the import inspection window. In case an error occurs, it is shown in a popup.
DOAJ (Directory of Open Access Journals) is a database covering more than 10000 open access journals covering all areas of science, technology, medicine, social science and humanities (Wikipedia).
To fetch entries from DOAJ, choose Search → Web search, and the search interface will appear in the side pane. Select DOAJ in the dropdown menu. To start a search, enter the words of your query, and press Enter or the Fetch button.
The results are displayed in the import inspection window. In case an error occurs, it is shown in a popup.
It is possible to limit the search by adding a field name to the search, as field:text. The supported fields area:
title: The title of the article
doi: The DOI of the article
issn: The ISSN of the journal
publisher: The publisher of the journal
abstract: The abstract of the article
GVK, the GBV Union Catalogue, is a multimaterial bibliographic database of seven German federal states. It covers 41.5 million records of books, conference proceedings, periodicals, dissertations, microfilms and electronic resources.
To fetch entries from GVK, choose Search → Web search, and the search interface will appear in the side pane. Select GVK (Gemeinsamer Verbundkatalog) in the dropdown menu. To start a search, enter the words of your query, and press Enter or the Fetch button.
The results are displayed in the import inspection window. In case an error occurs, it is shown in a popup.
You can simply enter words / names / years you want to search for, or you can specify search keys. Supported keys are:
all - all words. Not specifYing a search key results in an "all" search
tit - title words
per - authors, editors, etc.
thm - topics
slw - key words
txt - tables of content
num - numbers, e.g. ISBN
kon - names of conferences
ppn - Pica Production Numbers of the GVK
bkl - Basisklassifikation-numbers
erj - year of publication
queries can be combined with "and". The use of "and" is optional, though.
in many cases you can use the truncation sign "?"
spaces in person names are not supported yet. Please use the truncation sign ? after the first name for several given names. E.g. "per Maas,jan?"
"marx kapital"
"per grodke and tit db2"
"per Maas,jan?"
Google Scholar is a freely accessible database that indexes the full text or metadata of scholarly literature across an array of publishing formats and disciplines. Google Scholar index includes most peer-reviewed online academic journals and books, conference papers, theses and dissertations, preprints, abstracts, technical reports, and other scholarly literature, including court opinions and patents (Wikipedia).
To fetch entries from Google Scholar, choose Search → Web search, and the search interface will appear in the side pane. Select Google Scholar in the dropdown menu. To start a search, enter the words of your query, and press Enter or the Fetch button.
Google scholar can block "automated" crawls which generate too much traffic in a short time. Normally, the results are displayed in the import inspection window. In case an error occurs, it is shown in a popup.
However, after too much crawls JabRef --- or more precisely: your IP address --- could be blocked. To unblock your IP, doing a Google scholar search in your browser might help. You will be asked to show that you are not a robot (a CAPTCHA challenge). If no CAPTCHA appears, or JabRef is still blocked after performing a search in the browser, you can also change your IP address manually or wait for some hours to get unblocked again.
Thus, the Google Scholar fetcher is not the best way to obtain lots of entries at the same time. If you are using Mozilla Firefox, the JabRef Plugin "JabFox" might be an alternative to download the BibTeX data directly from the browser. You can find the PlugIn here: https://addons.mozilla.org/en-US/firefox/addon/jabfox/?src=external-jabrefSite.
Import and export of bibliographic information using online bibliographic databases
MEDLINE is a bibliographic database of life sciences and biomedical information. It includes bibliographic information for articles from academic journals covering medicine, nursing, pharmacy, dentistry, veterinary medicine, and health care. MEDLINE also covers much of the literature in biology and biochemistry, as well as fields such as molecular evolution (Wikipedia).
To fetch entries from MEDLINE, choose Search → Web search, and the search interface will appear in the side pane. Select MEDLINE in the dropdown menu. To start a search, enter the words of your query, and press Enter or the Fetch button.
There are two ways of specifying which entries to download:
Enter one or more MEDLINE IDs (separated by comma/semicolon) in the text field.
Enter a set of names and/or words to search for. You can use the operators and and or and parentheses to refine your search expression. See OVID operators for full description.
Examples:
May \[au\] AND Anderson \[au\]
Anderson RM \[au\] HIV \[ti\]
Valleron \[au\] 1988:2000\[dp\] HIV \[ti\]
Valleron \[au\] AND 1987:2000\[dp\] AND (AIDS \[ti\] OR HIV\[ti\])
Anderson \[au\] AND Nature \[ta\]
Population \[ta\]
In both cases, press Enter or the Fetch button. If you use a text search, you will be prompted with the number of entries found, and given a choice of how many to download.
Then, the results are displayed in the import inspection window. In case an error occurs, it is shown in a popup.
If you need to use an HTTP proxy server, you can configure JabRef to use a proxy using the "Network" preferences (Options → Preferences → Network).
JabRef is not intended to be a tool for mass download of citations. The purpose of the WebFetchers (such as the Medline Fetcher) is to simplify download of single, or at least few entries without using the browser. That means, one tries to import the bibliographic information of already known publications in a simple way.
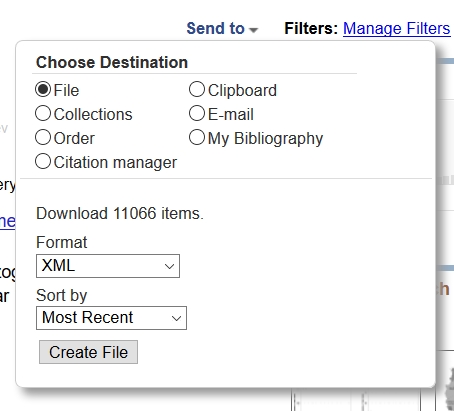
However, it is still possible to import hundreds or even thousands of entries from medline using the export functionality of the database itself. Perfom the search query you like, and then choose the "Send to" → "File" export (choose Medline or XML as format):
The downloaded file can then be imported using JabRefs "File" → "Import into current/new database" feature. Note: depending on the number the import might require some - or quite a lot of time. It was tried in 2016 with an exported XML file of 130MB an over 11000 found entries, which required more than 10 minutes of import.
Apart from fetching entries by using a full search it is also possible to directly create a BibTeX entry using the BibTeX → New Entry dialog. More details are described at Medline-to-BibTeX.
INSPIRE-HEP is an open access digital library for the field of high energy physics (Wikipedia).
To fetch entries from INSPIRE-HEP, choose Search → Web search, and the search interface will appear in the side pane. Select INSPIRE in the dropdown menu. To start a search, enter the words of your query, and press Enter or the Fetch button.
The results are displayed in the import inspection window. In case an error occurs, it is shown in a popup.
The INSPIRE-HEP search function merely passes your search queries onto the INSPIRE-HEP web search, so you should build your queries in the same way, except omitting the find or fin command. This help page will only give a brief introduction to the search queries. More extensive help on searching INSPIRE-HEP can be found on the page http://inspirehep.net/info/hep/search-tips .
Your query can be composed of several parts, combined using and and or as logical operators. Each part is composed of a letter or word indicating the type of field to search, followed by a space and the text to search for.
The following list shows some of the field indicators that can be used:
a or author: search author names
t or title: search in title
j: journal. Here either the common abbreviation or the 5 letter CODEN abbreviation for a journal can be used. Volume and page can also be included, separated by commas. For instance, j Phys. Rev.,D54,1 looks in the journal Phys. Rev., volume D54, page 1.
k: search in keywords
Example queries:
a smith and a jones: search for references with authors "smith" and "jones"
a smith or a jones: search for references with either author "smith" or author "jones"
a smith and not t processor: search for author "smith" and omit references with "processor" in the title
Since: 3.7
The search bar is located between the icon bar and the database tabs.
To make the cursor jump to the search field, you can:
click in the search field.
select the menu Search → Search.
press Ctrl + F.
Additionally, Ctrl + Shift + F also activates the global search setting.
Searching includes two modes (normal and advanced), along with several settings.
At the right of the search text field, several buttons allow for selecting some settings:
New window
When pressed, the results are displayed in a dedicated window.
Global search
activated:
the search query will be taken over when switching tabs
the external search result window will show matches in all databases
deactivated:
each tab will remember its search query
the external search result window will only show matches in the current database
Regular expressions
Whether or not the search query uses regular expressions.
Case sensitivity
Whether or not the search query is case sensitive.
Display setting
Filter - Displays only entries which match the search query, non-matches are hidden
Float - Matching entries are moved to the top, entries which do not match the search query are grayed-out
There are two search modes in JabRef.
In a normal search, the program searches your database for all occurrences of the words in your search string, once you entered it. Only entries containing all words will be considered matches. To search for sequences of words, enclose the sequences in double quotes. For instance, the query progress "marine aquaculture" will match entries containing both the word "progress" and the phrase "marine aquaculture". All entries that don't match are hidden, leaving for display the matching entries only (filter mode), or are grayed-out (float mode). To stop displaying the search results, just clear the search field again, press Esc or click on the "Clear" (X) button.
In order to search specific fields only and/or include logical operators in the search expression, a special syntax is available in which these can be specified. E.g. to search for entries whose an author contains miller, enter:
author = miller
Both the field specification and the search term support regular expressions. If the search term contains spaces, enclose it in quotes. Do not use spaces in the field specification! E.g. to search for entries about image processing, type:
title|keywords = "image processing"
You can use and, or, not, and parentheses as intuitively expected:
(author = miller or title|keywords = "image processing") and not author = brown
The = sign is actually a shorthand for contains. Searching for an exact match is possible using matches or ==. Using != tests if the search term is not contained in the field (equivalent to not ... contains ...). The selection of field types to search (required, optional, all) is always overruled by the field specification in the search expression. If a field is not given, all fields are searched. For example, video and year == 1932 will search for entries with any field containing video and the field year being exactly 1932.
JabRef defines the following pseudo fields:
Pseudo field
Purpose
Example
anyfield
Search in any field
anyfield contains fruit: search for entries having one of its fields containing the word fruit. This is identical to just writing apple. It may be more useful as anyfield matches apple, where one field must be exactly apple for a match.
anykeyword
Search among the keywords
anykeyword matches apple: search for entries which has the word apple among its keywords. However, as this also matches pineapple, it may be more useful in searches of the type anykeyword matches apple, which will not match apples or pineapple
bibtexkey
Search for citation keys
bibtexkey == miller2005: search for an entry whose BibTeX key is miller2005
entrytype
Search for entries of a certain type
entrytype = thesis: search entries whose type (as displayed in the entrytype column) contains the word thesis (which would be phdthesis and mastersthesis)
Regular expressions (regex for short) define a language for specifying the text to be matched, for example when searching. JabRef uses regular expressions as defined in Java. For extensive information, please, look at the documentation and at the tutorial.
They can be used in the normal search mode and the advanced search mode
By default, regular expressions do not account for upper/lower casing. Hence, while the examples below are all in lower case, they match also upper- and mixed case strings.
If casing is important to your search, activate the case-sensitive button.
. means any character
+ means one or more times
author != .+
\b means word boundary
\B means not a word boundary
keywords = \buv\b matches uv but not lluvia (it does match uv-b however)
author = \bblack\b matches black but neither blackwell nor blacker
author == black does not match john black, but author = \bblack\b does.
author = \bblack\B matches blackwell and blacker, but not black.
? means none or one copy of the preceeding character.
{n,m} means at least n, but not more than m copies of the preceding character.
[ ] defines a character class
title =neighbou?r matches neighbour and neighbor, and also neighbours and neighbors, and neighbouring and neighboring, etc.
title = neighbou?rs?\b matches neighbour and neighbor, and also neighbours and neighbors, but neither neighbouring nor neighboring.
author = s[aá]nchez matches sanchez and sánchez.
abstract = model{1,2}ing matches modeling and modelling.
abstract = modell?ing also matches modeling and modelling.
()[]{}\^-=$!|?*+.)If a special character (i.e. ( ) [ ] { } \ ^ - = $ ! | ? * + . ) is included in your search string, it has to be escaped with a backslash, such as \} for }.
It means that to search for a string including a backslash, two consecutive backslashes (\\) have to be used: abstract = xori{\\c{c}}o matches xoriço.
")The character " has a special meaning: it is used to group words into phrases for exact matches. So, if you search for a string that includes a double quotation, the double quotation character has to be replaced with the hexadecimal character 22 in ASCII table \x22.
Hence, to search for {"o}quist as an author, you must input author = \{\\\x22o\}quist, with regular expressions enabled (Note: the {, __ and the } are escaped with a backslash; see above).
Indeed, \" does not work as an escape for ". Hence, neither author = {\"o}quist with regular expression disabled, nor author = \{\\\"O\}quist with regular expression enabled, will find anything even if the name {"o}quist exists in the database.
Since: 3.7
is a searchable online bibliographic database. It contains all of the contents of the journal Mathematical Reviews (MR) since 1940 along with an extensive author database, links to other MR entries, citations, full journal entries, and links to original articles. It contains almost 3 million items and over 1.7 million links to original articles ().
To fetch entries from MathSciNet, choose Search → Web search, and the search interface will appear in the side pane. Select MathSciNet in the dropdown menu. To start a search, enter the words of your query, and press Enter or the Fetch button.
Then, the results are displayed in the . In case an error occurs, it is shown in a popup.
is a scholarly research database that indexes, abstracts, and provides full-text for articles and papers on computer science, electrical engineering and electronics. IEEEXplore comprises over 180 journals, over 1,400 conference proceedings, more than 3,800 technical standards, over 1,800 eBooks and over 400 educational courses ()
To fetch entries from IEEEXplore, choose Search → Web search, and the search interface will appear in the side pane. Select IEEEXplore in the dropdown menu. To start a search, enter the words of your query, and press Enter or the Fetch button.
By checking the Include abstracts checkbox, you may opt to download the abstracts along with the cite information for each entry. This will NOT cause more network queries.
The results are displayed in the . In case an error occurs, it is shown in a popup.
The search is done in guest mode, which means that a maximum of 100 results will be returned.
The option to download BibTeX citations directly from IEEEXplore is not working yet.
Please email Oscar Gustafsson ogib73@gmail.com or Aaron Chen nextAaron@gmail.com for any suggestions.
is an open database with over 20 million free scholarly articles harvested from over 50,000 journals and open-access repositories around the globe. Sources for these articles include repositories run by renowned universities, governments, and scholarly societies. Unpaywall is integrated into thousands of existing search engines, library platforms, and information products, making articles easy to find, track, and use for your scholarly communication needs.
The Unpaywall database has a very simple structure: it has one record for each article with a Crossref DOI. It harvests from many sources to find Open Access content, and then matches this content to these DOIs using content fingerprints. So for any given DOI, we know about any OA versions that exist anywhere.
To fetch entries from Unpaywall indirectly through Crossref, choose Search → Web search, and the search interface will appear in the side pane. Select Crossref in the dropdown menu. To start a search, enter the words of your query, and press Enter or the Fetch button.
The results are displayed in the . In case an error occurs, it is shown in a popup.
Since: 3.7
is a reviewing service providing reviews and abstracts for articles in pure and applied mathematics ().
To fetch entries from zbMATH, choose Search → Web search, and the search interface will appear in the side pane. Select zbMATH in the dropdown menu. To start a search, enter the words of your query, and press Enter or the Fetch button.
Then, the results are displayed in the . In case an error occurs, it is shown in a popup.
Springer (aka Springer Science+Business Media) is a global publishing company that publishes books, e-books and peer-reviewed journals in science, technical and medical publishing. Springer also hosts a number of scientific databases, including SpringerLink, Springer Protocols, and SpringerImages (Wikipedia).
To fetch entries from Springer, choose Search → Web search, and the search interface will appear in the side pane. Select Springer in the dropdown menu. To start a search, enter the words of your query, and press Enter or the Fetch button.
The results are displayed in the import inspection window. In case an error occurs, it is shown in a popup.
Import and export of bibliographic information using identifiers (such as a DOI)
Since: 3.7
SAO/NASA Astrophysics Data System is an online database of over eight million astronomy and physics papers from both peer reviewed and non-peer reviewed sources. Abstracts are available free online for almost all articles, and full scanned articles are available in Graphics Interchange Format (GIF) and Portable Document Format (PDF) for older articles (Wikipedia).
To fetch entries from SAO/NASA Astrophysics Data System, choose Search → Web search, and the search interface will appear in the side pane. Select SAO/NASA Astrophysics Data System in the dropdown menu. To start a search, enter the words of your query, and press Enter or the Fetch button.
Then, the results are displayed in the import inspection window. In case an error occurs, it is shown in a popup.
Apart from fetching entries by using a full search, it is also possible to directly create a BibTeX entry using the BibTeX → New Entry dialog. More details are described at ADS-to-BibTeX.
Since: 4.1
The International Association for Cryptologic Research maintains an eprint archive to which anyone can submit papers and technical reports. These eprints are given IDs based on the year of submission, e.g. the 10th submission in 2018 gets the ID "2018/10".
To create a new entry form an IACR eprint ID, choose BibTeX → New entry.... In the lower part, there is the box "ID-based entry generator". In the field "ID type", "IACR" should be already selected. The field "ID" is focused. Enter the eprints' ID here and press Enter to generate an entry based on the Id. You can also click on "Generate". The new entry is opened in an entry editor. In case an error occurs, a popup is shown.
To get the ID, you may want to use their web search form at https://eprint.iacr.org/search.html.
Since: 3.7
DiVA (Digitala Vetenskapliga Arkivet) is a database with publications from about 40 Swedish universities and research institutions.
To use this feature, choose BibTeX → New entry.... In the lower part, there is the box "ID-based entry generator". In the field "ID type", "DiVA" can be selected (see screenshot below). Select the field "ID" and enter the DiVA here (e.g., diva2:260746) and press Enter to generate an entry based on the Id. You can also click on "Generate". The found entry is opened in an entry editor. In case an error occurs, a popup is shown.
Since: 3.7
To use this feature, choose BibTeX → New entry.... In the lower part, there is the box "ID-based entry generator". In the field "ID type", "DOI" should be already selected. The field "ID" is focused. Enter the DOI here and press Enter to generate an entry based on the Id. You can also click on "Generate". Then, http://dx.doi.org/ (provided by http://crossref.org/) is used to convert the given DOI to a BibTeX entry. The found entry is opened in an entry editor. In case an error occurs, a popup is shown.
Since: 3.8
To use this feature, choose BibTeX → New entry.... In the lower part, there is the box "ID-based entry generator". In the field "ID type", you can select "ISBN". The field "ID" is focused. Enter the ISBN here and press Enter to generate an entry based on the Id. You can also click on "Generate". Then, eBook.de's API is used to convert an ISBN to a BibTeX entry. If no entry is found, the fetcher tries OttoBib to find an entry. The found entry is opened in an entry editor. In case an error occurs, a popup is shown.
Some fetched entries contain a url field. This field points to the URL of the book at the respective online book store. In case you buy the book using the link, the service provider (ebook.de) receive a commission to fund the service.
Since: 3.8.1
To use this feature, choose BibTeX → New entry.... In the lower part, there is the box "ID-based entry generator". In the field "ID type", you can select "Title". The field "ID" is focused. Enter the title here and press Enter to generate an entry based on the title. You can also click on "Generate". Then, http://dx.doi.org/ (provided by http://crossref.org/) is used to determine the DOI and convert the determined DOI to a BibTeX entry. The found entry is opened in an entry editor. In case an error occurs, a popup is shown. In case no DOI could be determined, no entry is created.
Since: 3.7
SAO/NASA Astrophysics Data System is an online database of over eight million astronomy and physics papers from both peer reviewed and non-peer reviewed sources. Abstracts are available free online for almost all articles, and full scanned articles are available in Graphics Interchange Format (GIF) and Portable Document Format (PDF) for older articles (Wikipedia).
To use this feature, choose BibTeX → New entry.... In the lower part, there is the box "ID-based entry generator". In the field "ID type", "SAO/NASA Astrophysics Data System" can be selected (see screenshot below). Select the field "ID" and enter the SAO/NASA Astrophysics Data System ID here (e.g., 2013Sci...339..671W) and press Enter to generate an entry based on the Id. You can also click on "Generate". The found entry is opened in an entry editor. In case an error occurs, a popup is shown.
Since: 4.3
IETF (Internet Engineering Task Force) Datatracker is a database that "contains data about the documents, working groups, meetings, agendas, minutes, presentations, and more, of the IETF."
To use this feature, choose BibTeX → New entry.... In the lower part, there is the box "ID-based entry generator". In the field "ID type", "RFC" can be selected (see screenshot below). Select the field "ID" and enter the RFC here, with or without the "rfc" prefix (e.g. 1954, rfc1954) and press Enter to generate an entry based on the Id. You can also click on "Generate". The found entry is opened in an entry editor. In case an error occurs, a popup is shown.
This feature is available through Quality → Find unlinked files....
The following description appeared first on tex.stackexchange.com.
JabRef offers a BibTeX key generation and offers different patterns described at BibtexKeyPatterns.
Create or open a .bib file.
Go to "Quality" -> "Find unlinked files".
The "Find unlinked files" dialog opens.
Choose a directory using the "Browse" button.
Click on "Scan directory".
In "Select files", the files not yet contained in the database are shown.
To create entries for all files, click on "Apply".
For each file, an import dialog is shown The dialog shows the XMP metadata stored in the PDF in the area "XMP-metadata". If this data fits your needs, select "Create entry based on XMP data". Typically, the XMP-metadata is not good enough. Choose "Create entry based on content".
Click on "OK" to start the import
A dialog asking for the link is opened You can choose "Leave file in its current directory" to keep the file where it is. Typically, this is that what one wants. In case you choose "Move file to file directory", you can also choose to rename the file to the generated BibTeX key.
Press OK to link the file to the BibTeX entry
This happens for each file. After that, the "Find unlinked files" dialog is shown. Just click on "Close" to close it.
The entry editor with the last imported entry is shown
You can now save the file and are finished.
Optional: Click on "General" to see the linked file
Optional: Click on "BibTeX source" to see the BibTeX source
Optional: You have to shrink it to see the entry in the entry table Enlarge the JabRef window and use the mouse at the upper border of the entry editor
Optional: Press Esc to show the entry preview
The importer based on the content has been written for IEEE and LNCS formatted papers. Other formats are not (yet) supported. In case a DOI is found on the first page, the DOI is used to generate the BibTeX information.
The next development step is to extract the title of the PDF, use the "Lookup DOI" and then the Get BibTeX data from DOI functionality from JabRef to fetch the BibTeX data.
We are also thinking about replacing the code completely by using another library. This is much effort and there is no timeline for that.
This makes the filenames start with the bibtey key followed by the full title. In the concrete case, \bibtexkey only may be the better option as the described bibtey key already contains the title.
JabRef used to have support for Mr.DLib, which returned back a full BibTeX entry or a PDF. Due to unclear copyright situation of a used library, this service was removed. Further, Mr.DLib changes its focus and will provide literature recommendations. See the realted articles tab.
JabRef also offers to change the filenames. You can adapt the pattern at Preferences -> Import
Select "Choose pattern" and choose "bibtexkey - title" This results in the setting \bibtexkey\begin{title} - \format[RemoveBrackets]{\title}\end{title}.
JabRef can check the integrity of a database.
This feature is available through Quality → Check integrity....
This feature is available through Quality → Synchronize file links....
JabRef can cleanup the entries of a database. To do a cleanup of the entries, go to Quality → Cleanup entries.
In the lower part, you can choose "Run field formatter", where you can choose different Save Actions. Dependent on the database mode, "Recommended for BibTeX" or "Recommended for BibLaTeX". When pressing this button, the recommended cleanups for the respective mode is called.
Field formatting can be tidied up when saving the database. That ensures your entries to have consistent formatting. If you check Enable save actions in the Database Properties, the list of actions can be configured.
Each action is defined by:
an entry field (upon which the action will be applied).
the type of action to be carried out (such as HTML to LaTeX, which converts HTML code to LaTeX code, as described in the window).
Dependent on the database mode, "Recommended for BibTeX" or "Recommended for BibLaTeX". When pressing this button, the recommended cleanups for the respective mode is called.
Add braces encapsulating the complete field content. For instance
gets
However, this procedure is not recommended. It is better to use the "Protect Terms" functionality. See also https://tex.stackexchange.com/q/10772/9075.
Clears the field completely.
Escape underscores
Converts HTML code to LaTeX code.
Converts HTML code to Unicode.
Cleans up LaTeX code.
Normalizes the date to ISO date format. Format date string to yyyy-mm-dd or yyyy-mm. Keeps the existing String if it does not match one of the following formats:
"M/y" (covers 9/15, 9/2015, and 09/2015)
"MMMM (dd), yyyy" (covers September 1, 2015 and September, 2015)
"yyyy-MM-dd" (covers 2009-1-15)
"d.M.uuuu" (covers 15.1.2015)
Normalizes the en dashes.
Replace “-” with “--”.
Normalize month to BibTeX standard abbreviation.
Normalizes lists of persons to the BibTeX standard. This separates authors by "and"s with first names after last name separated by a commma; first names are not abbreviated.
"John Smith" ⇒ "Smith, John"
"John Smith and Black Brown, Peter" ⇒ "Smith, John and Black Brown, Peter"
"John von Neumann and John Smith and Black Brown, Peter" ⇒ "von Neumann, John and Smith, John and Black Brown, Peter".
Normalize pages to BibTeX standard. Format page numbers, separated either by commas or double-hyphens. Converts the range number format to page_number--page_number. Removes unwanted literals except letters, numbers and -+ signs. Keeps the existing String if the resulting field does not match the expected Regex.
Converts ordinals to LaTeX superscripts, e.g. 1st, 2nd or 3rd. Will replace ordinal numbers even if they are semantically wrong, e.g. 21rd
1st Conf. Cloud Computing -> 1\textsuperscript{st} Conf. Cloud Computing
Removes braces encapsulating the complete field content.
Removes all hyphenated line breaks in the field content.
Removes all line breaks in the field content.
Shortens DOI to more human readable form using http://shortdoi.org .
Converts Unicode characters to LaTeX encoding.
Converts units to LaTeX formatting. This includes:
Add braces around the unit to keep case.
Replace hyphen with non-break hyphen
Replace space with a hard space
Changes the first letter of all words to capital case and the remaining letters to lower case.
Changes all letters to lower case.
Adds {} brackets around acronyms, month names and countries to preserve their case.
Capitalize the first word, changes other words to lower case.
Capitalize all words, but converts articles, prepositions, and conjunctions to lower case.
Changes all letters to upper case.
Shortens lists of persons if there are more than 2 persons to "et al.".
JabRef can help you complement your entries from their DOI.
Open the entry editor, and in the General tab, click on the button Get BibTeX data from DOI. Obviously, this feature is available only if your entry already has a DOI.
The Merge entry with DOI information window will pop-up.
The fields of the original entry and of the information gathered from the DOI are displayed side-by-side on the upper part of the window.
The differences between the two sides can be emphasized through the drop-down menu located at the upper right-hand corner of the window. Five ways of displaying the differences are offered:
plain text: as is, no emphasis
show diff - word: differences are shown on the right side.
Full words are struck out in red if they are removed from the original entry or underlined in blue if they are added to the information collected from the DOI.
show diff - character: differences are shown on the right side.
Individual characters are struck out in red or underlined in blue as above.
show symmetric diff - word: differences are shown on both sides.
Words are underlined and displayed in color.
show symmetric diff - character: differences are shown on both sides.
Characters are underlined and displayed in color.
In the central column, a radio button allows you to select which side to keep for each field: the left side, the right side, or none. By default, the original entry (left) is kept, and any fields not present in the original entry are obtained from the information collected from the DOI.
Based upon your selection, the merged entry is shown, both as a preview (on the left) and as source code (on the right).
If you right-click on the preview, you can Print entry preview or Copy preview.
Finally, after selecting which fields to keep, you can decide to Replace the original entry. Alternatively, you can press Cancel.
See also: Find duplicates, Merge entries
This feature is available through Search → Replace string....
Groups allow to structure a BibTeX database in a tree-like way that is similar to organizing files on disk in directories and subdirectories. The two main differences are:
While a file is always located in exactly one directory, an entry may be contained in more than one group.
Groups may use certain criteria to dynamically define their content. New entries that match these criteria are automatically contained in these groups. This feature is not available in common file systems, but in several Email clients (e.g. Thunderbird and Opera).
Selecting a group shows the entries contained in that group. Selecting multiple groups shows the entries contained in any group (union) or those contained in all groups (intersection), depending on the current settings. All this is explained in detail below.
Group definitions are database-specific; they are saved as a @COMMENT block in the .bib-file and are shared among all users. (Future versions of JabRef might support user-dependent groups.)
The groups interface is shown in the side pane on the left of the screen. It can be toggled on or off by pressing Ctrl + Shift + G or by the groups button in the toolbar. The interface has several buttons, but most functions are accessed via a context ("right-click") menu. Drag and Drop is also supported.
To manually assign entries to a group, press the New Group button, enter a name for the group, then press OK, leaving all values at their defaults. Now select the entries to be assigned to the group and use Drag and Drop to the group, or the option Add to group in the context menu. Finally select the group to see its content (which should be the entries you just assigned).
In case you want automatically fill the groups content based on keywords, do the following: Press the New Group button, enter a name for the group, and select the option to dynamically group entries by searching a field for a keyword. Enter the keyword to search for, then click OK. Finally select the group to see its content (which should be all entries whose keywords field contains the keyword you specified).
In case a group should be filled with entries containing defined search strings, do the following: Press the New Group button, enter a name for the group, and select the option to dynamically group entries by a free-form search expression. Enter author=smith as a search expression (replace smith with a name that actually occurs in your database) and click OK. Finally select the group to see its content (which should be all entries whose author field contains the name you specified).
You can also intersact or unition groups: Create two different groups (e.g. as described above). Click the Settings button and make sure that Union is selected. Now select both groups. You should see all entries contained in any of the two groups. Click Settings again and select Intersection. Now you should see only those entries contained in both groups (which might be none at all, or exactly the same entries as before in case both groups contain the same entries).
JabRef allows you to easily identify groups that overlap with the currently selected groups (i.e. that contain at least one entry that is also contained in the currently selected groups). Click Settings and activate the option to highlight overlapping groups. Then select a group that overlaps with other groups. The other groups should be highlighted.
In JabRef there are four different types of groups:
The group All Entries, which -- as the name suggests -- contains all entries, is always present and cannot be edited or removed.
Static groups behave like directories on disk and contain only those entries that you explicitly assign to them.
Dynamic groups based on keyword search contain entries in which a certain BibTeX field (e.g. keywords) contains a certain keyword (e.g. electrical). This method does not require manual assignment of entries, but uses information that is already present in the database. If all entries in your database have suitable keywords in their keywords field, using this type of group might be the best choice.
Dynamic groups based on free-form search expressions contain entries that match a specified search expression, using the same syntax as the search panel on the side pane. This syntax supports logical operators (AND, OR, NOT) and allows to specify one or more BibTeX fields to search, facilitating more flexible group definitions than a keyword search (e.g. author=smith and title=electrical).
Every group that you create is of one of the last three types. The group editing dialog, which is invoked by double-clicking on a group, shows a short description of the selected/edited group in plain English.
Just like directories, groups are structured like a tree, with the group All Entries at the root. By right-clicking on a group you can add a new group to the tree, either at the same level as the selected group or as a subgroup of it. The New Group button lets you create a new subgroup of the group All Entries, regardless of the currently selected group(s). The context menu also allows to remove groups and/or subgroups, to sort subgroups alphabetically, or to move groups to a different location in the tree. The latter can also be done by Drag and Drop, with the restriction that Drag and Drop does not support changing the order of a group's subgroups.
Undo and redo is supported for all edits.
Defines the name of the group, as displayed in the group panel.
A description of the group, to help you remember what it is about. Hovering the mouse over the group name displays this description.
An icon can be displayed in front of the group name. Choose your favorite icon among the ones available at https://materialdesignicons.com/, and enter its name of the field Icon. The color of the icon can be set in to the field Color.
Remark: outdated: The new interface (JabRef 5.0) displays a list of 5 choices under "Collect by".
Static groups are populated only by explicit manual assignment of entries. After creating a static group you select the entries to be assigned to it, and use either Drag and Drop or the main table's context menu to perform the assignment. To remove entries from a static group, select them and use the main table's context menu. There are no options to be configured.
This method of grouping requires that all entries have a unique BibTeX key. In case of missing or duplicate BibTeX keys, the assignment of the affected entries cannot be correctly restored in future sessions.
The content of a dynamic group is defined by a logical condition. Only entries that meet this condition are contained in the group. This method uses the information stored in the database itself, and updates dynamically whenever the database changes.
Two types of conditions can be used:
Searching a field for a keyword
This method groups entries in which a specified BibTeX field (e.g. keywords) contains a specified search term (e.g. electrical). Obviously, for this to work, the grouping field must be present in every entry, and its content must be accurate. The above example would group all entries referring to something electrical. Using the field author allows to group entries by a certain author, etc. The search can either be done as a plain-text or a regular expression search. In the former case, JabRef allows to manually assign/remove entries to/from the group by simply appending/removing the search term to/from the content of the grouping field. This makes sense only for the keywords field or for self-defined fields, but obviously not for fields like author or year.
Using a free-form search expression
This is similar to the above, but rather than search a single field for a single search term, the search expression syntax can be used, which supports logical operators (AND, OR, NOT) and allows to search multiple BibTeX fields. For example, the search expression keywords=regression and not keywords=linear groups entries concerned with non-linear regression.
In the groups view, dynamic groups are shown in italics by default. This can be turned off in the preferences (Options → Preferences → Groups, box "Show dynamic groups in italics").
By default, a group is independent of its position in the groups tree: When selected, only the group's contents are shown. However, especially when using dynamic groups, it is often useful to define a subgroup that refines its supergroup, i.e., when selected, entries contained in both groups are displayed. For example, create a supergroup containing entries with the keyword distribution and a subgroup containing entries with the keyword gauss that refines this supergroup. Selecting the subgroup now displays entries that match both conditions, i.e. are concerned with Gaussian distributions. Note that items that only belong to the subgroup gauss will not be shown, i.e. for an item to be displayed when selecting gauss it is necessary to be assigned to both the subgroup gauss and the supergroup distribution. By adding another refining subgroup for laplace to the original supergroup, the grouping can easily be extended. In the groups tree, refining groups have a special icon (this can be turned off in the preferences).
The logical complement to a refining group is a group that includes its subgroups, i.e. when selected, not only the group's own entries, but also its subgroups' entries are shown. In the groups tree, this type of group has a special icon (this can be turned off in the preferences).
In other words, this defines which entries are displayed when this group is selected:
independant. Displays only this group's entries.
intersection. Displays entries contained in both this group and its supergroup.
union. Displays entries contained in this group or its subgroups.
Selecting a group shows the entries contained in that group by highlighting them and, depending on the settings (accessible by clicking the Settings button), moving them to the top of the list and/or selecting them. These options are identical to those available for the regular search.
When multiple groups are selected, either the union or the intersection of their content is shown, depending on the current settings. This allows to quickly combine multiple conditions, e.g. if you have a static group Extremely Important to which you assign all extremely important entries, you can view the extremely important entries in any other group by selecting both groups (this requires to have Intersection selected in the settings).
When viewing the contents of the selected group(s), a search can be performed within these contents using the regular search facility.
The Settings button offers an option to highlight overlapping groups. If this is activated, upon selection of one or more groups, all groups that contain at least one of the entries contained in the currently selected group(s) are highlighted. This quickly identifies overlap between the groups' contents. You might, for example, create a group To Read that contains all entries which you plan to read. Now, whenever you select any group, the group To Read is highlighted if the selected group contains entries that you plan to read.
The Settings button offers also an option to automatically assign new entries to selected groups. If this is activated, upon selection of one or more groups, all the new entries created will be assigned to the selected groups. This work both for entries created from menu button or entries pasted from clipboard. This option can also be enabled/disabled from the menu "option > preferences > group".
After mastering the grouping concepts described above, the following advanced features might come in handy.
By clicking the Automatically create groups for database button, you can quickly create a set of groups appropriate for your database. This feature will gather all words found in a specific field of your choice, and create a group for each word. This is useful for instance if your database contains suitable keywords for all entries. By autogenerating groups based on the keywords field, you should have a basic set of groups at no cost.
You can also specify characters to ignore, for instance commas used between keywords. These will be treated as separators between words, and not part of them. This step is important for combined keywords such as laplace distribution to be recognized as a single semantic unit. (You cannot use this option to remove complete words. Instead, delete the unwanted groups manually after they were created automatically.)
The Refresh button updates the entry table to reflect the current groups selection. This is usually done automatically, but in rare occasions (e.g. after a group-related undo/redo) a manual refresh is required.
If a refining group is a subgroup of a group that includes its subgroups -- the refining group's siblings --, these siblings are ignored when the refining group is selected.
JabRef can look for duplicated entries inside a database.
This feature is accessible directly through Quality → Find duplicates. It is also used when importing new entries from a supported reference format or directly from the Internet.
Detection of potential duplicates is done by an edit distance algorithm. Extra weighting is put on the fields author, editor, title and journal.
When two potential duplicates are found, their fields are displayed side-by-side.
The differences between the two entries can be emphasized through the drop-down menu located at the upper right-hand corner of the window. Five ways of displaying the differences are offered:
plain text: as is, no emphasis
show diff - word: differences are shown in the right entry. Full words are struck out in red if they are removed from the left entry or underlined in blue if they are added to the right entry.
show diff - character: differences are shown in the right entry. Individual characters are struck out in red or underlined in blue as above.
show symmetric diff - word: differences are shown on both sides. Words are underlined and displayed in color.
show symmetric diff - character: differences are shown on both sides. Characters are underlined and displayed in color.
In the central column, a radio button allows you to select which side to keep for each field: the left side, the right side, or none. By default, the left entry is kept and any fields not present in the left entry are obtained from the right entry.
You are offered to:
Automatically remove exact duplicates. This button shows up if there are exact duplicates. Clicking that leads to all exact duplicates to be removed.
Keep left entry. Removes the right entry.
Keep right entry. Removes the left entry.
Keep both entries, meaning that you consider the two entries are not duplicates.
Keep merged entry only, meaning that the merged entry is the best. Both previous entries are removed.
Cancel, which will end the duplicate finding.






























